 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntWorld: A Holistic Environment and Benchmark for Verifiable Enterprise GUI Agents
Jan 25, 2026Recent advances in Multimodal Large Language Models (MLLMs) have enabled agents to operate in open-ended web and operating system environments. However, existing benchmarks predominantly target consumer-oriented scenarios (e.g., e-commerce and travel booking), failing to capture the complexity and rigor of professional enterprise workflows. Enterprise systems pose distinct challenges, including high-density user interfaces, strict business logic constraints, and a strong reliance on precise, state-consistent information retrieval-settings in which current generalist agents often struggle. To address this gap, we introduce EntWorld, a large-scale benchmark consisting of 1,756 tasks across six representative enterprise domains, including customer relationship management (CRM), information technology infrastructure library (ITIL), and enterprise resource planning (ERP) systems. Unlike previous datasets that depend on fragile execution traces or extensive manual annotation, EntWorld adopts a schema-grounded task generation framework that directly reverse-engineers business logic from underlying database schemas, enabling the synthesis of realistic, long-horizon workflows. Moreover, we propose a SQL-based deterministic verification mechanism in building datasets that replaces ambiguous visual matching with rigorous state-transition validation. Experimental results demonstrate that state-of-the-art models (e.g., GPT-4.1) achieve 47.61% success rate on EntWorld, substantially lower than the human performance, highlighting a pronounced enterprise gap in current agentic capabilities and the necessity of developing domain-specific agents. We release EntWorld as a rigorous testbed to facilitate the development and evaluation of the next generation of enterprise-ready digital agents.
Understanding and Preserving Safety in Fine-Tuned LLMs
Jan 15, 2026Fine-tuning is an essential and pervasive functionality for applying large language models (LLMs) to downstream tasks. However, it has the potential to substantially degrade safety alignment, e.g., by greatly increasing susceptibility to jailbreak attacks, even when the fine-tuning data is entirely harmless. Despite garnering growing attention in defense efforts during the fine-tuning stage, existing methods struggle with a persistent safety-utility dilemma: emphasizing safety compromises task performance, whereas prioritizing utility typically requires deep fine-tuning that inevitably leads to steep safety declination. In this work, we address this dilemma by shedding new light on the geometric interaction between safety- and utility-oriented gradients in safety-aligned LLMs. Through systematic empirical analysis, we uncover three key insights: (I) safety gradients lie in a low-rank subspace, while utility gradients span a broader high-dimensional space; (II) these subspaces are often negatively correlated, causing directional conflicts during fine-tuning; and (III) the dominant safety direction can be efficiently estimated from a single sample. Building upon these novel insights, we propose safety-preserving fine-tuning (SPF), a lightweight approach that explicitly removes gradient components conflicting with the low-rank safety subspace. Theoretically, we show that SPF guarantees utility convergence while bounding safety drift. Empirically, SPF consistently maintains downstream task performance and recovers nearly all pre-trained safety alignment, even under adversarial fine-tuning scenarios. Furthermore, SPF exhibits robust resistance to both deep fine-tuning and dynamic jailbreak attacks. Together, our findings provide new mechanistic understanding and practical guidance toward always-aligned LLM fine-tuning.
FBA$^2$D: Frequency-based Black-box Attack for AI-generated Image Detection
Dec 10, 2025



The prosperous development of Artificial Intelligence-Generated Content (AIGC) has brought people's anxiety about the spread of false information on social media. Designing detectors for filtering is an effective defense method, but most detectors will be compromised by adversarial samples. Currently, most studies exposing AIGC security issues assume information on model structure and data distribution. In real applications, attackers query and interfere with models that provide services in the form of application programming interfaces (APIs), which constitutes the black-box decision-based attack paradigm. However, to the best of our knowledge, decision-based attacks on AIGC detectors remain unexplored. In this study, we propose \textbf{FBA$^2$D}: a frequency-based black-box attack method for AIGC detection to fill the research gap. Motivated by frequency-domain discrepancies between generated and real images, we develop a decision-based attack that leverages the Discrete Cosine Transform (DCT) for fine-grained spectral partitioning and selects frequency bands as query subspaces, improving both query efficiency and image quality. Moreover, attacks on AIGC detectors should mitigate initialization failures, preserve image quality, and operate under strict query budgets. To address these issues, we adopt an ``adversarial example soup'' method, averaging candidates from successive surrogate iterations and using the result as the initialization to accelerate the query-based attack. The empirical study on the Synthetic LSUN dataset and GenImage dataset demonstrate the effectiveness of our prosed method. This study shows the urgency of addressing practical AIGC security problems.
Toward Adaptive BCIs: Enhancing Decoding Stability via User State-Aware EEG Filtering
Nov 11, 2025Brain-computer interfaces (BCIs) often suffer from limited robustness and poor long-term adaptability. Model performance rapidly degrades when user attention fluctuates, brain states shift over time, or irregular artifacts appear during interaction. To mitigate these issues, we introduce a user state-aware electroencephalogram (EEG) filtering framework that refines neural representations before decoding user intentions. The proposed method continuously estimates the user's cognitive state (e.g., focus or distraction) from EEG features and filters unreliable segments by applying adaptive weighting based on the estimated attention level. This filtering stage suppresses noisy or out-of-focus epochs, thereby reducing distributional drift and improving the consistency of subsequent decoding. Experiments on multiple EEG datasets that emulate real BCI scenarios demonstrate that the proposed state-aware filtering enhances classification accuracy and stability across different user states and sessions compared with conventional preprocessing pipelines. These findings highlight that leveraging brain-derived state information--even without additional user labels--can substantially improve the reliability of practical EEG-based BCIs.
Lightweight Time Series Data Valuation on Time Series Foundation Models via In-Context Finetuning
Nov 10, 2025Time series foundation models (TSFMs) have demonstrated increasing capabilities due to their extensive pretraining on large volumes of diverse time series data. Consequently, the quality of time series data is crucial to TSFM performance, rendering an accurate and efficient data valuation of time series for TSFMs indispensable. However, traditional data valuation methods, such as influence functions, face severe computational bottlenecks due to their poor scalability with growing TSFM model sizes and often fail to preserve temporal dependencies. In this paper, we propose LTSV, a Lightweight Time Series Valuation on TSFMS via in-context finetuning. Grounded in the theoretical evidence that in-context finetuning approximates the influence function, LTSV estimates a sample's contribution by measuring the change in context loss after in-context finetuning, leveraging the strong generalization capabilities of TSFMs to produce robust and transferable data valuations. To capture temporal dependencies, we introduce temporal block aggregation, which integrates per-block influence scores across overlapping time windows. Experiments across multiple time series datasets and models demonstrate that LTSV consistently provides reliable and strong valuation performance, while maintaining manageable computational requirements. Our results suggest that in-context finetuning on time series foundation models provides a practical and effective bridge between data attribution and model generalization in time series learning.
DMA: Online RAG Alignment with Human Feedback
Nov 06, 2025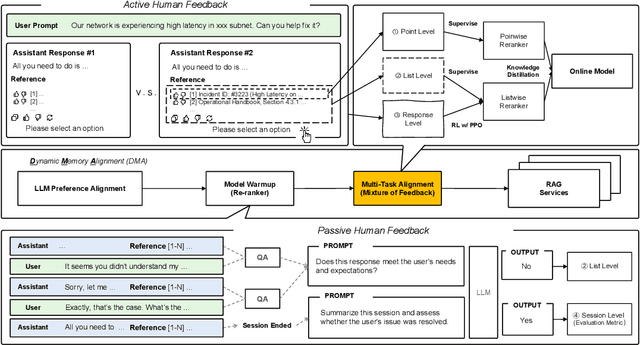

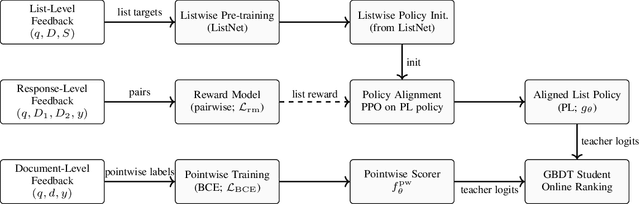
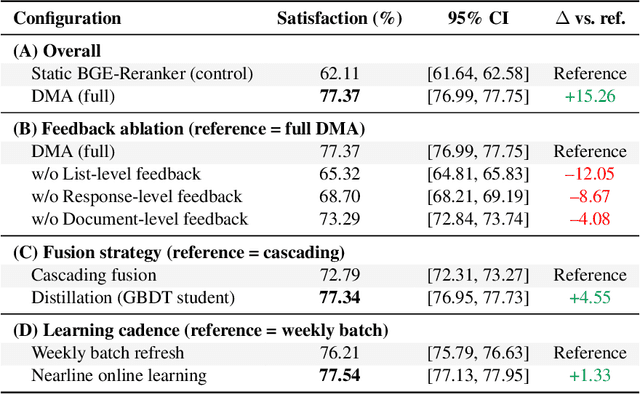
Retrieval-augmented generation (RAG) systems often rely on static retrieval, limiting adaptation to evolving intent and content drift. We introduce Dynamic Memory Alignment (DMA), an online learning framework that systematically incorporates multi-granularity human feedback to align ranking in interactive settings. DMA organizes document-, list-, and response-level signals into a coherent learning pipeline: supervised training for pointwise and listwise rankers, policy optimization driven by response-level preferences, and knowledge distillation into a lightweight scorer for low-latency serving. Throughout this paper, memory refers to the model's working memory, which is the entire context visible to the LLM for In-Context Learning. We adopt a dual-track evaluation protocol mirroring deployment: (i) large-scale online A/B ablations to isolate the utility of each feedback source, and (ii) few-shot offline tests on knowledge-intensive benchmarks. Online, a multi-month industrial deployment further shows substantial improvements in human engagement. Offline, DMA preserves competitive foundational retrieval while yielding notable gains on conversational QA (TriviaQA, HotpotQA). Taken together, these results position DMA as a principled approach to feedback-driven, real-time adaptation in RAG without sacrificing baseline capability.
Tensor-Efficient High-Dimensional Q-learning
Nov 05, 2025


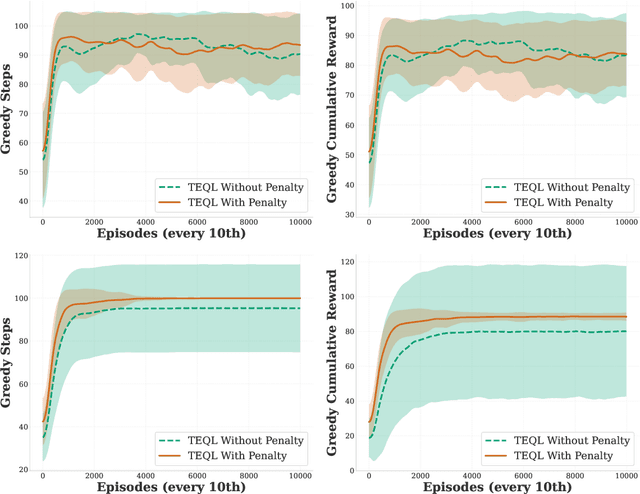
High-dimensional reinforcement learning faces challenges with complex calculations and low sample efficiency in large state-action spaces. Q-learning algorithms struggle particularly with the curse of dimensionality, where the number of state-action pairs grows exponentially with problem size. While neural network-based approaches like Deep Q-Networks have shown success, recent tensor-based methods using low-rank decomposition offer more parameter-efficient alternatives. Building upon existing tensor-based methods, we propose Tensor-Efficient Q-Learning (TEQL), which enhances low-rank tensor decomposition via improved block coordinate descent on discretized state-action spaces, incorporating novel exploration and regularization mechanisms. The key innovation is an exploration strategy that combines approximation error with visit count-based upper confidence bound to prioritize actions with high uncertainty, avoiding wasteful random exploration. Additionally, we incorporate a frequency-based penalty term in the objective function to encourage exploration of less-visited state-action pairs and reduce overfitting to frequently visited regions. Empirical results on classic control tasks demonstrate that TEQL outperforms conventional matrix-based methods and deep RL approaches in both sample efficiency and total rewards, making it suitable for resource-constrained applications, such as space and healthcare where sampling costs are high.
DynaMark: A Reinforcement Learning Framework for Dynamic Watermarking in Industrial Machine Tool Controllers
Aug 29, 2025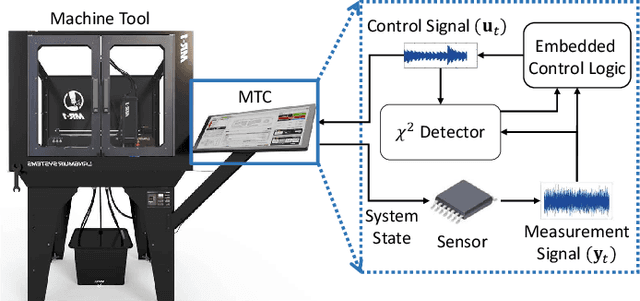
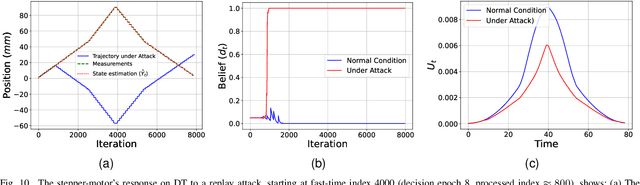
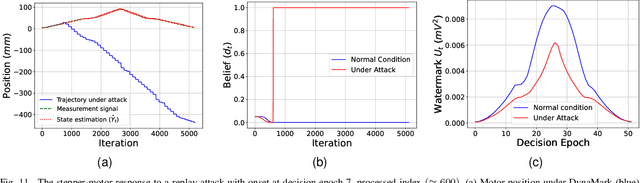
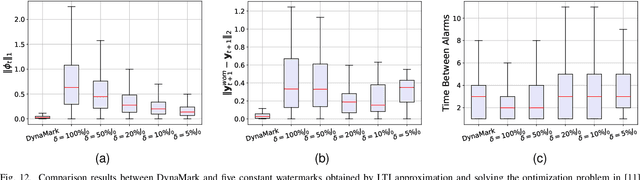
Industry 4.0's highly networked Machine Tool Controllers (MTCs) are prime targets for replay attacks that use outdated sensor data to manipulate actuators. Dynamic watermarking can reveal such tampering, but current schemes assume linear-Gaussian dynamics and use constant watermark statistics, making them vulnerable to the time-varying, partly proprietary behavior of MTCs. We close this gap with DynaMark, a reinforcement learning framework that models dynamic watermarking as a Markov decision process (MDP). It learns an adaptive policy online that dynamically adapts the covariance of a zero-mean Gaussian watermark using available measurements and detector feedback, without needing system knowledge. DynaMark maximizes a unique reward function balancing control performance, energy consumption, and detection confidence dynamically. We develop a Bayesian belief updating mechanism for real-time detection confidence in linear systems. This approach, independent of specific system assumptions, underpins the MDP for systems with linear dynamics. On a Siemens Sinumerik 828D controller digital twin, DynaMark achieves a reduction in watermark energy by 70% while preserving the nominal trajectory, compared to constant variance baselines. It also maintains an average detection delay equivalent to one sampling interval. A physical stepper-motor testbed validates these findings, rapidly triggering alarms with less control performance decline and exceeding existing benchmarks.
Comparing Uncertainty Measurement and Mitigation Methods for Large Language Models: A Systematic Review
Apr 25, 2025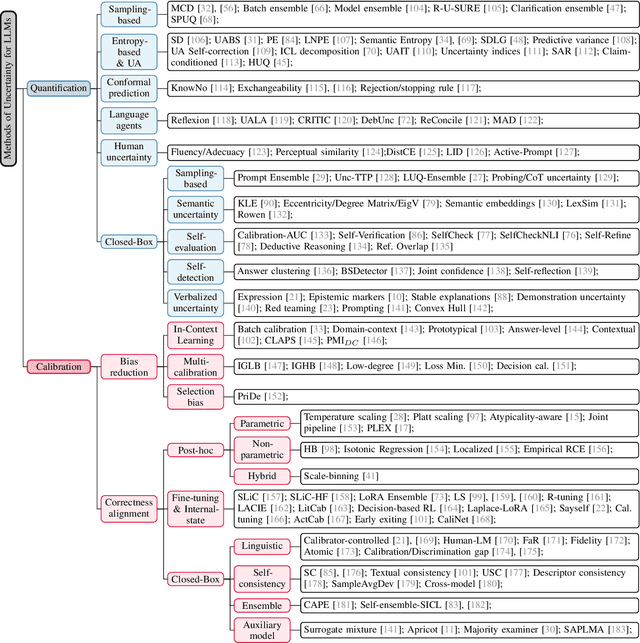
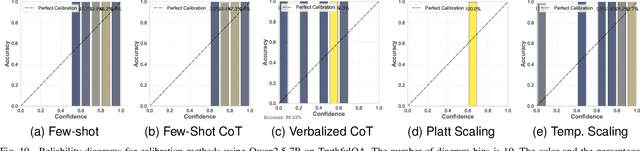
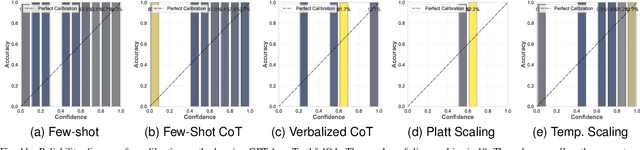
Large Language Models (LLMs) have been transformative across many domains. However, hallucination -- confidently outputting incorrect information -- remains one of the leading challenges for LLMs. This raises the question of how to accurately assess and quantify the uncertainty of LLMs. Extensive literature on traditional models has explored Uncertainty Quantification (UQ) to measure uncertainty and employed calibration techniques to address the misalignment between uncertainty and accuracy. While some of these methods have been adapted for LLMs, the literature lacks an in-depth analysis of their effectiveness and does not offer a comprehensive benchmark to enable insightful comparison among existing solutions. In this work, we fill this gap via a systematic survey of representative prior works on UQ and calibration for LLMs and introduce a rigorous benchmark. Using two widely used reliability datasets, we empirically evaluate six related methods, which justify the significant findings of our review. Finally, we provide outlooks for key future directions and outline open challenges. To the best of our knowledge, this survey is the first dedicated study to review the calibration methods and relevant metrics for LLMs.
BACE-RUL: A Bi-directional Adversarial Network with Covariate Encoding for Machine Remaining Useful Life Prediction
Mar 14, 2025Prognostic and Health Management (PHM) are crucial ways to avoid unnecessary maintenance for Cyber-Physical Systems (CPS) and improve system reliability. Predicting the Remaining Useful Life (RUL) is one of the most challenging tasks for PHM. Existing methods require prior knowledge about the system, contrived assumptions, or temporal mining to model the life cycles of machine equipment/devices, resulting in diminished accuracy and limited applicability in real-world scenarios. This paper proposes a Bi-directional Adversarial network with Covariate Encoding for machine Remaining Useful Life (BACE-RUL) prediction, which only adopts sensor measurements from the current life cycle to predict RUL rather than relying on previous consecutive cycle recordings. The current sensor measurements of mechanical devices are encoded to a conditional space to better understand the implicit inner mechanical status. The predictor is trained as a conditional generative network with the encoded sensor measurements as its conditions. Various experiments on several real-world datasets, including the turbofan aircraft engine dataset and the dataset collected from degradation experiments of Li-Ion battery cells, show that the proposed model is a general framework and outperforms state-of-the-art methods.