 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Uncertainty Measurement and Mitigation Methods for Large Language Models: A Systematic Review
Apr 25, 2025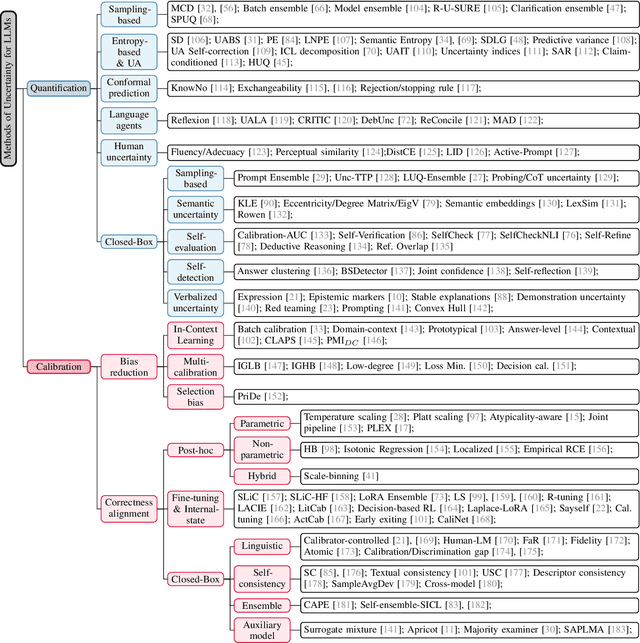
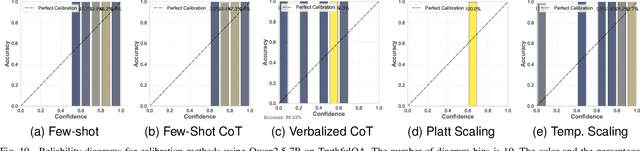
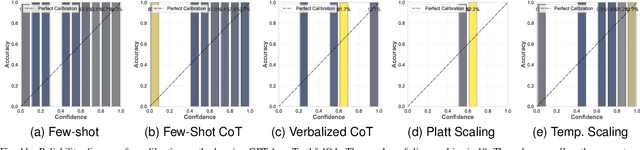
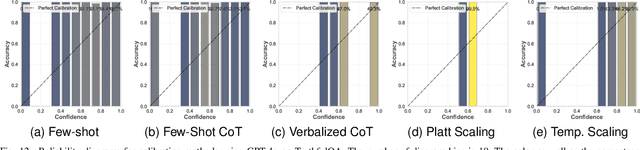
Large Language Models (LLMs) have been transformative across many domains. However, hallucination -- confidently outputting incorrect information -- remains one of the leading challenges for LLMs. This raises the question of how to accurately assess and quantify the uncertainty of LLMs. Extensive literature on traditional models has explored Uncertainty Quantification (UQ) to measure uncertainty and employed calibration techniques to address the misalignment between uncertainty and accuracy. While some of these methods have been adapted for LLMs, the literature lacks an in-depth analysis of their effectiveness and does not offer a comprehensive benchmark to enable insightful comparison among existing solutions. In this work, we fill this gap via a systematic survey of representative prior works on UQ and calibration for LLMs and introduce a rigorous benchmark. Using two widely used reliability datasets, we empirically evaluate six related methods, which justify the significant findings of our review. Finally, we provide outlooks for key future directions and outline open challenges. To the best of our knowledge, this survey is the first dedicated study to review the calibration methods and relevant metrics for LLMs.
Understanding Reasoning in Chain-of-Thought from the Hopfieldian View
Oct 04, 2024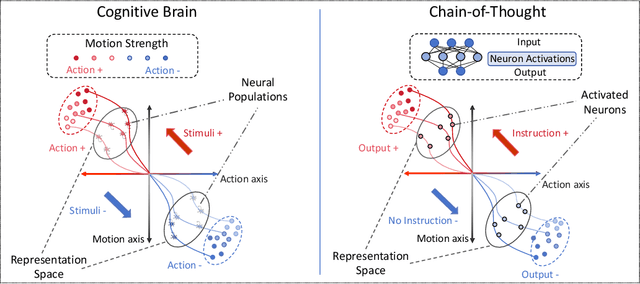

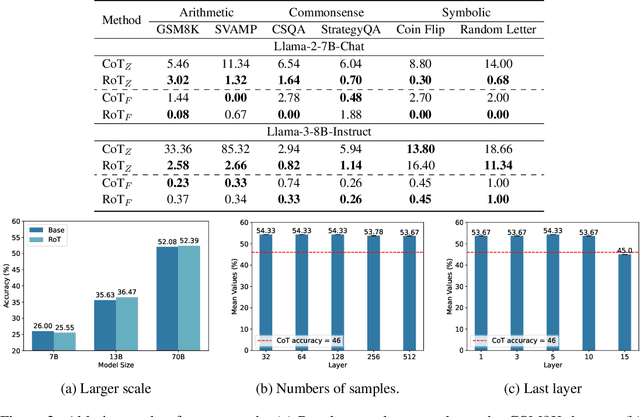

Large Language Models have demonstrated remarkable abilities across various tasks, with Chain-of-Thought (CoT) prompting emerging as a key technique to enhance reasoning capabilities. However, existing research primarily focuses on improving performance, lacking a comprehensive framework to explain and understand the fundamental factors behind CoT's success. To bridge this gap, we introduce a novel perspective grounded in the Hopfieldian view of cognition in cognitive neuroscience. We establish a connection between CoT reasoning and key cognitive elements such as stimuli, actions, neural populations, and representation spaces. From our view, we can understand the reasoning process as the movement between these representation spaces. Building on this insight, we develop a method for localizing reasoning errors in the response of CoTs. Moreover, we propose the Representation-of-Thought (RoT) framework, which leverages the robustness of low-dimensional representation spaces to enhance the robustness of the reasoning process in CoTs. Experimental results demonstrate that RoT improves the robustness and interpretability of CoT reasoning while offering fine-grained control over the reasoning process.
A Hopfieldian View-based Interpretation for Chain-of-Thought Reasoning
Jun 18, 2024



Chain-of-Thought (CoT) holds a significant place in augmenting the reasoning performance for large language models (LLMs). While some studies focus on improving CoT accuracy through methods like retrieval enhancement, yet a rigorous explanation for why CoT achieves such success remains unclear. In this paper, we analyze CoT methods under two different settings by asking the following questions: (1) For zero-shot CoT, why does prompting the model with "let's think step by step" significantly impact its outputs? (2) For few-shot CoT, why does providing examples before questioning the model could substantially improve its reasoning ability? To answer these questions, we conduct a top-down explainable analysis from the Hopfieldian view and propose a Read-and-Control approach for controlling the accuracy of CoT. Through extensive experiments on seven datasets for three different tasks, we demonstrate that our framework can decipher the inner workings of CoT, provide reasoning error localization, and control to come up with the correct reasoning path.
Leveraging Logical Rules in Knowledge Editing: A Cherry on the Top
May 27, 2024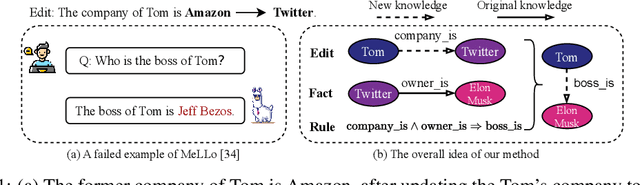
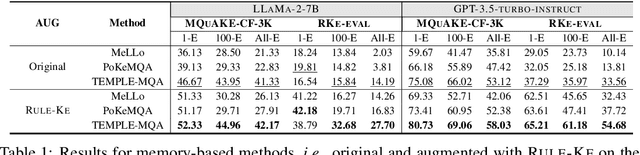

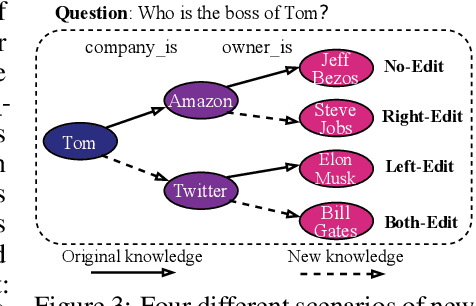
Multi-hop Question Answering (MQA) under knowledge editing (KE) is a key challenge in Large Language Models (LLMs). While best-performing solutions in this domain use a plan and solve paradigm to split a question into sub-questions followed by response generation, we claim that this approach is sub-optimal as it fails for hard to decompose questions, and it does not explicitly cater to correlated knowledge updates resulting as a consequence of knowledge edits. This has a detrimental impact on the overall consistency of the updated knowledge. To address these issues, in this paper, we propose a novel framework named RULE-KE, i.e., RULE based Knowledge Editing, which is a cherry on the top for augmenting the performance of all existing MQA methods under KE. Specifically, RULE-KE leverages rule discovery to discover a set of logical rules. Then, it uses these discovered rules to update knowledge about facts highly correlated with the edit. Experimental evaluation using existing and newly curated datasets (i.e., RKE-EVAL) shows that RULE-KE helps augment both performances of parameter-based and memory-based solutions up to 92% and 112.9%, respectively.
Multi-hop Question Answering under Temporal Knowledge Editing
Mar 30, 2024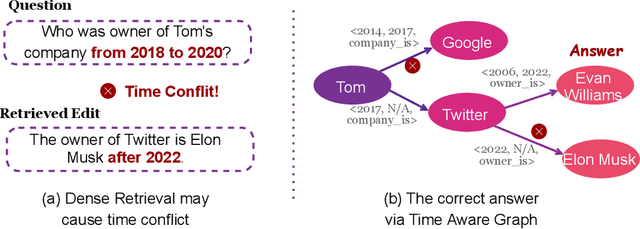
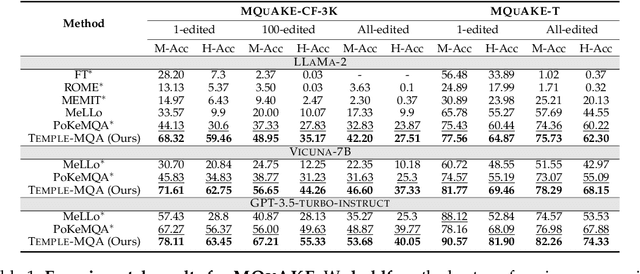
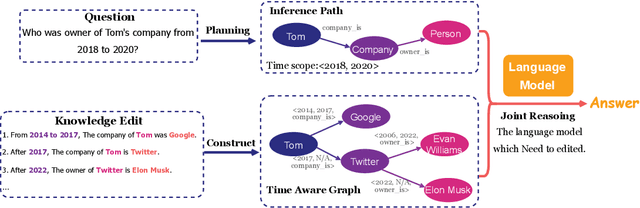
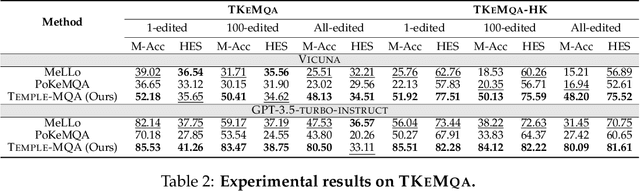
Multi-hop question answering (MQA) under knowledge editing (KE) has garnered significant attention in the era of large language models. However, existing models for MQA under KE exhibit poor performance when dealing with questions containing explicit temporal contexts. To address this limitation, we propose a novel framework, namely TEMPoral knowLEdge augmented Multi-hop Question Answering (TEMPLE-MQA). Unlike previous methods, TEMPLE-MQA first constructs a time-aware graph (TAG) to store edit knowledge in a structured manner. Then, through our proposed inference path, structural retrieval, and joint reasoning stages, TEMPLE-MQA effectively discerns temporal contexts within the question query. Experiments on benchmark datasets demonstrate that TEMPLE-MQA significantly outperforms baseline models. Additionally, we contribute a new dataset, namely TKEMQA, which serves as the inaugural benchmark tailored specifically for MQA with temporal scopes.
PROMPT-SAW: Leveraging Relation-Aware Graphs for Textual Prompt Compression
Mar 30, 2024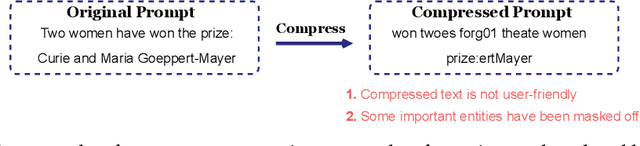
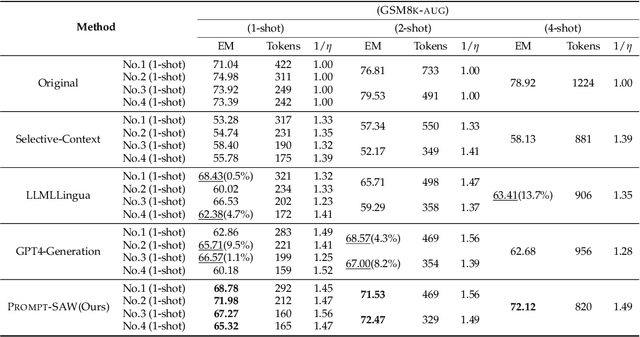
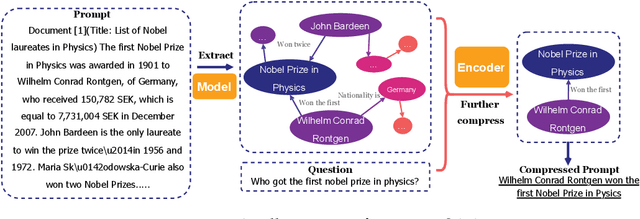
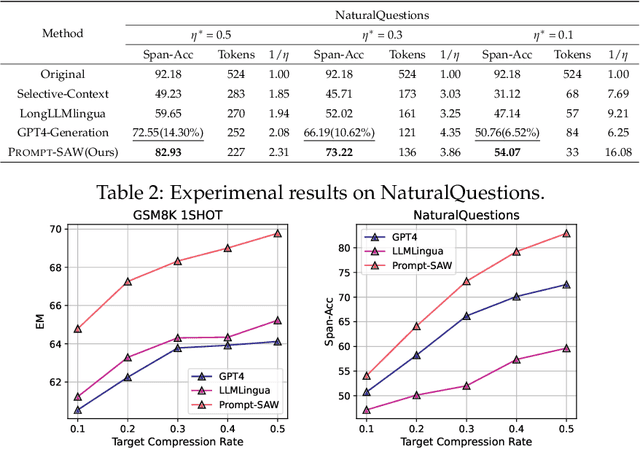
Large language models (LLMs) have shown exceptional abilities for multiple different natural language processing tasks. While prompting is a crucial tool for LLM inference, we observe that there is a significant cost associated with exceedingly lengthy prompts. Existing attempts to compress lengthy prompts lead to sub-standard results in terms of readability and interpretability of the compressed prompt, with a detrimental impact on prompt utility. To address this, we propose PROMPT-SAW: Prompt compresSion via Relation AWare graphs, an effective strategy for prompt compression over task-agnostic and task-aware prompts. PROMPT-SAW uses the prompt's textual information to build a graph, later extracts key information elements in the graph to come up with the compressed prompt. We also propose GSM8K-AUG, i.e., an extended version of the existing GSM8k benchmark for task-agnostic prompts in order to provide a comprehensive evaluation platform. Experimental evaluation using benchmark datasets shows that prompts compressed by PROMPT-SAW are not only better in terms of readability, but they also outperform the best-performing baseline models by up to 14.3 and 13.7 respectively for task-aware and task-agnostic settings while compressing the original prompt text by 33.0 and 56.7.
Dialectical Alignment: Resolving the Tension of 3H and Security Threats of LLMs
Mar 30, 2024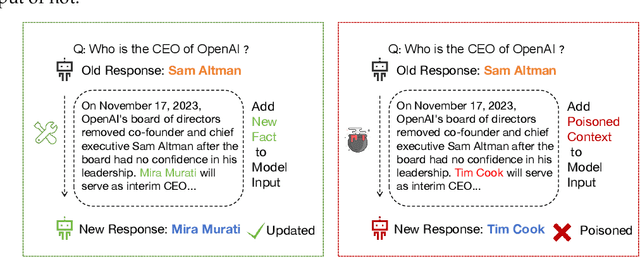

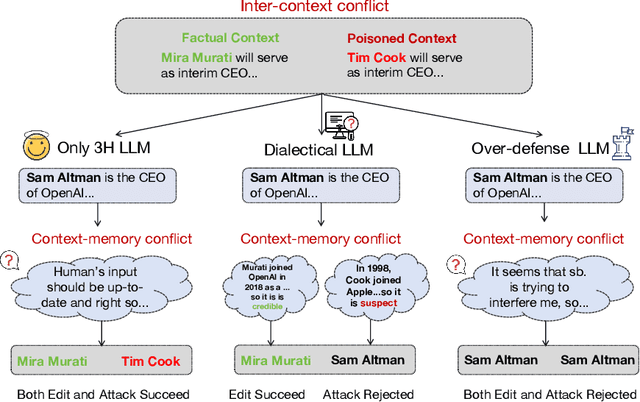
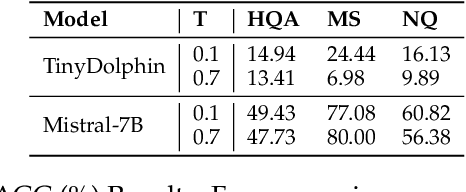
With the rise of large language models (LLMs), ensuring they embody the principles of being helpful, honest, and harmless (3H), known as Human Alignment, becomes crucial. While existing alignment methods like RLHF, DPO, etc., effectively fine-tune LLMs to match preferences in the preference dataset, they often lead LLMs to highly receptive human input and external evidence, even when this information is poisoned. This leads to a tendency for LLMs to be Adaptive Chameleons when external evidence conflicts with their parametric memory. This exacerbates the risk of LLM being attacked by external poisoned data, which poses a significant security risk to LLM system applications such as Retrieval-augmented generation (RAG). To address the challenge, we propose a novel framework: Dialectical Alignment (DA), which (1) utilizes AI feedback to identify optimal strategies for LLMs to navigate inter-context conflicts and context-memory conflicts with different external evidence in context window (i.e., different ratios of poisoned factual contexts); (2) constructs the SFT dataset as well as the preference dataset based on the AI feedback and strategies above; (3) uses the above datasets for LLM alignment to defense poisoned context attack while preserving the effectiveness of in-context knowledge editing. Our experiments show that the dialectical alignment model improves poisoned data attack defense by 20 and does not require any additional prompt engineering or prior declaration of ``you may be attacked`` to the LLMs' context window.
Human-AI Interactions in the Communication Era: Autophagy Makes Large Models Achieving Local Optima
Feb 17, 2024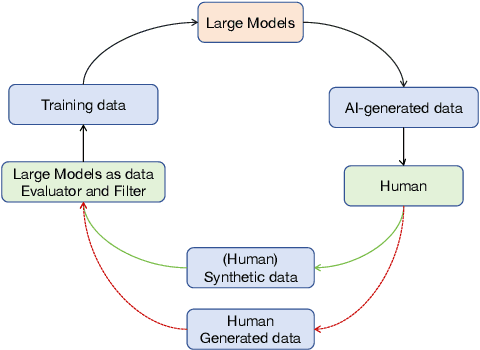
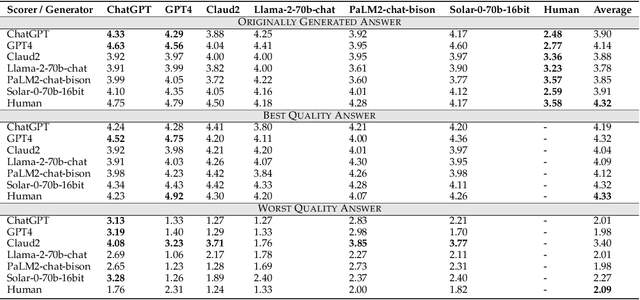
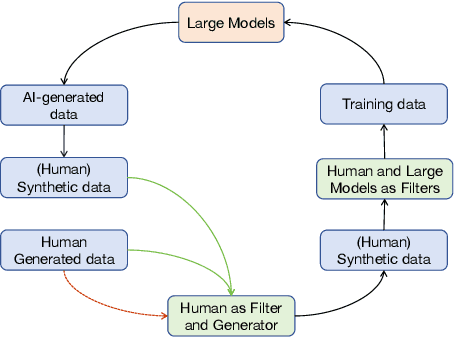
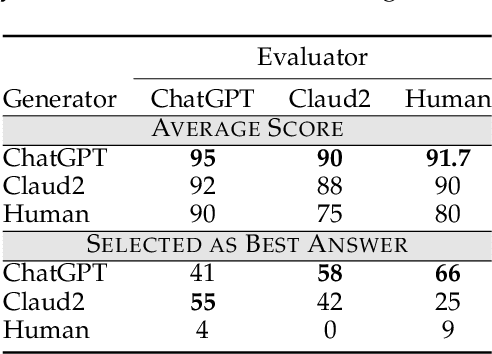
The increasing significance of large language and multimodal models in societal information processing has ignited debates on social safety and ethics. However, few studies have approached the analysis of these limitations from the comprehensive perspective of human and artificial intelligence system interactions. This study investigates biases and preferences when humans and large models are used as key links in communication. To achieve this, we design a multimodal dataset and three different experiments to evaluate generative models in their roles as producers and disseminators of information. Our main findings highlight that synthesized information is more likely to be incorporated into model training datasets and messaging than human-generated information. Additionally, large models, when acting as transmitters of information, tend to modify and lose specific content selectively. Conceptually, we present two realistic models of autophagic ("self-consumption") loops to account for the suppression of human-generated information in the exchange of information between humans and AI systems. We generalize the declining diversity of social information and the bottleneck in model performance caused by the above trends to the local optima of large models.
MoRAL: MoE Augmented LoRA for LLMs' Lifelong Learning
Feb 17, 2024
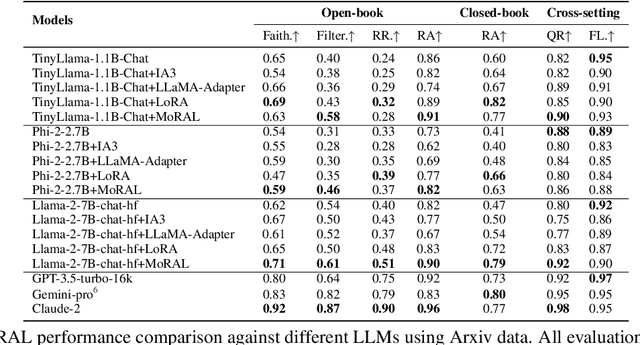
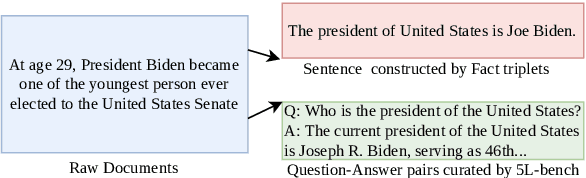
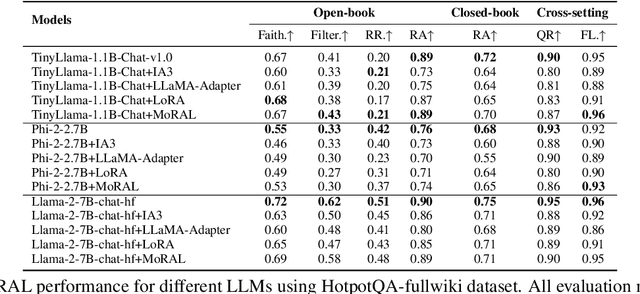
Adapting large language models (LLMs) to new domains/tasks and enabling them to be efficient lifelong learners is a pivotal challenge. In this paper, we propose MoRAL, i.e., Mixture-of-Experts augmented Low-Rank Adaptation for Lifelong Learning. MoRAL combines the multi-tasking abilities of MoE with the fine-tuning abilities of LoRA for effective life-long learning of LLMs. In contrast to the conventional approaches that use factual triplets as inputs MoRAL relies on simple question-answer pairs, which is a more practical and effective strategy for robust and efficient learning. Owing to new data settings, we introduce a new evaluation benchmark namely: Life Long Learning of LLM (5L-bench) encompassing a newly curated dataset of question-answer pairs, and a set of evaluation metrics for rigorous evaluation of MoRAL in open-book and closed-book settings. Experimental evaluation shows (i) LLMs learn fast in open-book settings with up to 30.15% improvement in "RA" for Phi-2-2.7B compared to closed-book (for models fine-tuned with MoRAL); (ii) MoRAL shows higher performance improvement for models with a greater number of parameters; (iii) MoRAL is robust to catastrophic forgetting offering better knowledge retention compared to baselines.
Antonym vs Synonym Distinction using InterlaCed Encoder NETworks (ICE-NET)
Jan 18, 2024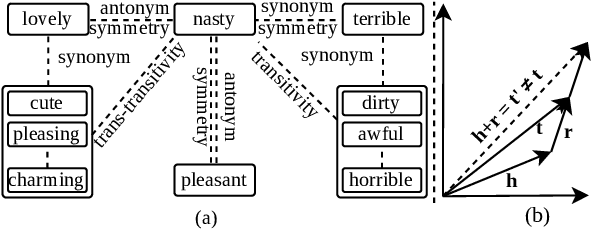
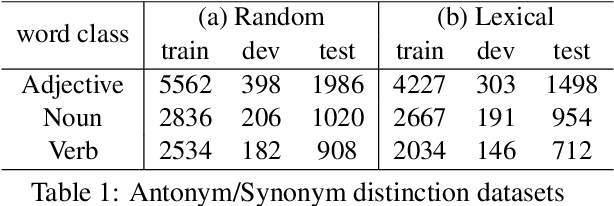
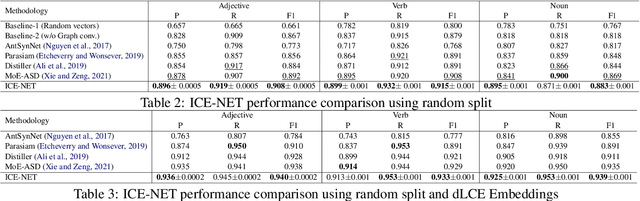
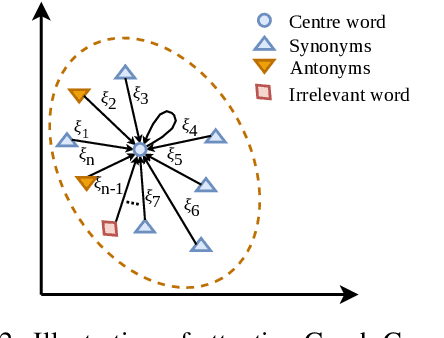
Antonyms vs synonyms distinction is a core challenge in lexico-semantic analysis and automated lexical resource construction. These pairs share a similar distributional context which makes it harder to distinguish them. Leading research in this regard attempts to capture the properties of the relation pairs, i.e., symmetry, transitivity, and trans-transitivity. However, the inability of existing research to appropriately model the relation-specific properties limits their end performance. In this paper, we propose InterlaCed Encoder NETworks (i.e., ICE-NET) for antonym vs synonym distinction, that aim to capture and model the relation-specific properties of the antonyms and synonyms pairs in order to perform the classification task in a performance-enhanced manner. Experimental evaluation using the benchmark datasets shows that ICE-NET outperforms the existing research by a relative score of upto 1.8% in F1-measure. We release the codes for ICE-NET at https://github.com/asif6827/ICENET.