 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Concept Bottleneck Models
Jan 01, 2026Concept Bottleneck Models (CBMs) have garnered much attention for their ability to elucidate the prediction process through a human-understandable concept layer. However, most previous studies focused on static scenarios where the data and concepts are assumed to be fixed and clean. In real-world applications, deployed models require continuous maintenance: we often need to remove erroneous or sensitive data (unlearning), correct mislabeled concepts, or incorporate newly acquired samples (incremental learning) to adapt to evolving environments. Thus, deriving efficient editable CBMs without retraining from scratch remains a significant challenge, particularly in large-scale applications. To address these challenges, we propose Controllable Concept Bottleneck Models (CCBMs). Specifically, CCBMs support three granularities of model editing: concept-label-level, concept-level, and data-level, the latter of which encompasses both data removal and data addition. CCBMs enjoy mathematically rigorous closed-form approximations derived from influence functions that obviate the need for retraining. Experimental results demonstrate the efficiency and adaptability of our CCBMs, affirming their practical value in enabling dynamic and trustworthy CBMs.
Towards Lifecycle Unlearning Commitment Management: Measuring Sample-level Unlearning Completeness
Jun 06, 2025Growing concerns over data privacy and security highlight the importance of machine unlearning--removing specific data influences from trained models without full retraining. Techniques like Membership Inference Attacks (MIAs) are widely used to externally assess successful unlearning. However, existing methods face two key limitations: (1) maximizing MIA effectiveness (e.g., via online attacks) requires prohibitive computational resources, often exceeding retraining costs; (2) MIAs, designed for binary inclusion tests, struggle to capture granular changes in approximate unlearning. To address these challenges, we propose the Interpolated Approximate Measurement (IAM), a framework natively designed for unlearning inference. IAM quantifies sample-level unlearning completeness by interpolating the model's generalization-fitting behavior gap on queried samples. IAM achieves strong performance in binary inclusion tests for exact unlearning and high correlation for approximate unlearning--scalable to LLMs using just one pre-trained shadow model. We theoretically analyze how IAM's scoring mechanism maintains performance efficiently. We then apply IAM to recent approximate unlearning algorithms, revealing general risks of both over-unlearning and under-unlearning, underscoring the need for stronger safeguards in approximate unlearning systems. The code is available at https://github.com/Happy2Git/Unlearning_Inference_IAM.
Data Lineage Inference: Uncovering Privacy Vulnerabilities of Dataset Pruning
Nov 24, 2024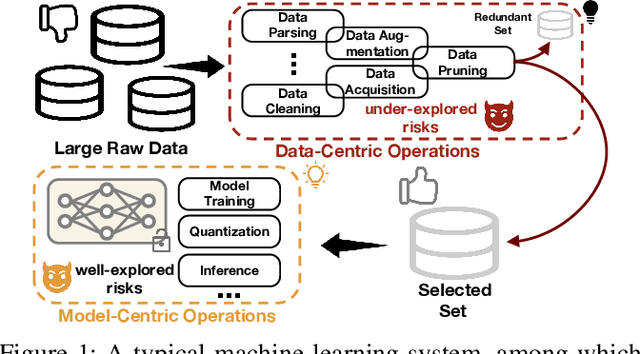
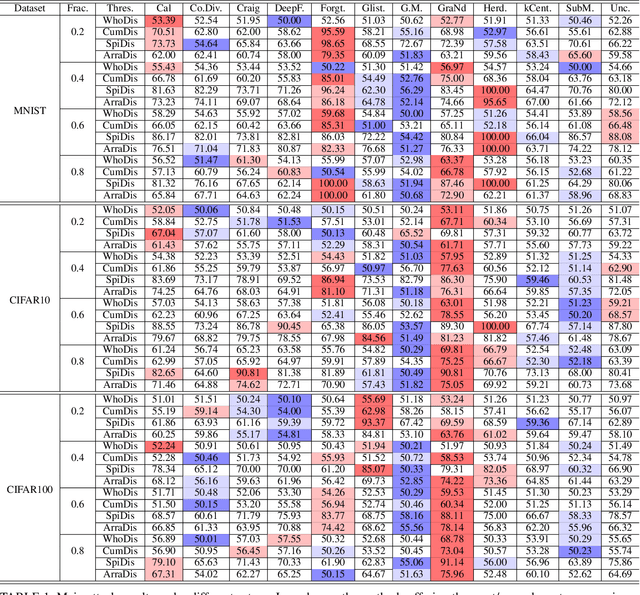
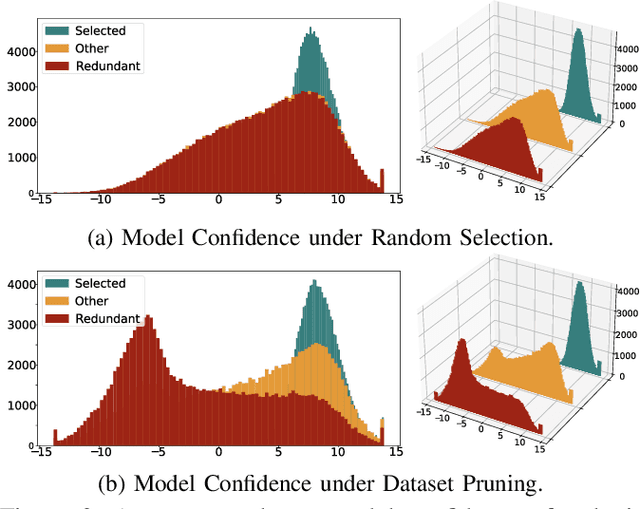
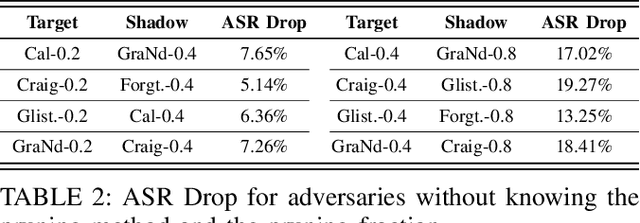
In this work, we systematically explore the data privacy issues of dataset pruning in machine learning systems. Our findings reveal, for the first time, that even if data in the redundant set is solely used before model training, its pruning-phase membership status can still be detected through attacks. Since this is a fully upstream process before model training, traditional model output-based privacy inference methods are completely unsuitable. To address this, we introduce a new task called Data-Centric Membership Inference and propose the first ever data-centric privacy inference paradigm named Data Lineage Inference (DaLI). Under this paradigm, four threshold-based attacks are proposed, named WhoDis, CumDis, ArraDis and SpiDis. We show that even without access to downstream models, adversaries can accurately identify the redundant set with only limited prior knowledge. Furthermore, we find that different pruning methods involve varying levels of privacy leakage, and even the same pruning method can present different privacy risks at different pruning fractions. We conducted an in-depth analysis of these phenomena and introduced a metric called the Brimming score to offer guidance for selecting pruning methods with privacy protection in mind.
Visual Agents as Fast and Slow Thinkers
Aug 16, 2024



Achieving human-level intelligence requires refining cognitive distinctions between System 1 and System 2 thinking. While contemporary AI, driven by large language models, demonstrates human-like traits, it falls short of genuine cognition. Transitioning from structured benchmarks to real-world scenarios presents challenges for visual agents, often leading to inaccurate and overly confident responses. To address the challenge, we introduce FaST, which incorporates the Fast and Slow Thinking mechanism into visual agents. FaST employs a switch adapter to dynamically select between System 1/2 modes, tailoring the problem-solving approach to different task complexity. It tackles uncertain and unseen objects by adjusting model confidence and integrating new contextual data. With this novel design, we advocate a flexible system, hierarchical reasoning capabilities, and a transparent decision-making pipeline, all of which contribute to its ability to emulate human-like cognitive processes in visual intelligence. Empirical results demonstrate that FaST outperforms various well-known baselines, achieving 80.8% accuracy over VQA^{v2} for visual question answering and 48.7% GIoU score over ReasonSeg for reasoning segmentation, demonstrate FaST's superior performance. Extensive testing validates the efficacy and robustness of FaST's core components, showcasing its potential to advance the development of cognitive visual agents in AI systems.
Editable Concept Bottleneck Models
May 24, 2024Concept Bottleneck Models (CBMs) have garnered much attention for their ability to elucidate the prediction process through a human-understandable concept layer. However, most previous studies focused on cases where the data, including concepts, are clean. In many scenarios, we always need to remove/insert some training data or new concepts from trained CBMs due to different reasons, such as privacy concerns, data mislabelling, spurious concepts, and concept annotation errors. Thus, the challenge of deriving efficient editable CBMs without retraining from scratch persists, particularly in large-scale applications. To address these challenges, we propose Editable Concept Bottleneck Models (ECBMs). Specifically, ECBMs support three different levels of data removal: concept-label-level, concept-level, and data-level. ECBMs enjoy mathematically rigorous closed-form approximations derived from influence functions that obviate the need for re-training. Experimental results demonstrate the efficiency and effectiveness of our ECBMs, affirming their adaptability within the realm of CBMs.
Has Approximate Machine Unlearning been evaluated properly? From Auditing to Side Effects
Mar 19, 2024



The growing concerns surrounding data privacy and security have underscored the critical necessity for machine unlearning--aimed at fully removing data lineage from machine learning models. MLaaS providers expect this to be their ultimate safeguard for regulatory compliance. Despite its critical importance, the pace at which privacy communities have been developing and implementing strong methods to verify the effectiveness of machine unlearning has been disappointingly slow, with this vital area often receiving insufficient focus. This paper seeks to address this shortfall by introducing well-defined and effective metrics for black-box unlearning auditing tasks. We transform the auditing challenge into a question of non-membership inference and develop efficient metrics for auditing. By relying exclusively on the original and unlearned models--eliminating the need to train additional shadow models--our approach simplifies the evaluation of unlearning at the individual data point level. Utilizing these metrics, we conduct an in-depth analysis of current approximate machine unlearning algorithms, identifying three key directions where these approaches fall short: utility, resilience, and equity. Our aim is that this work will greatly improve our understanding of approximate machine unlearning methods, taking a significant stride towards converting the theoretical right to data erasure into a auditable reality.
MoRAL: MoE Augmented LoRA for LLMs' Lifelong Learning
Feb 17, 2024
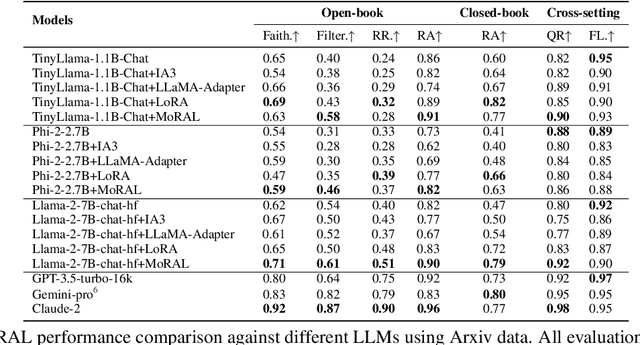
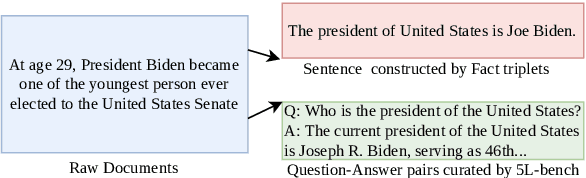
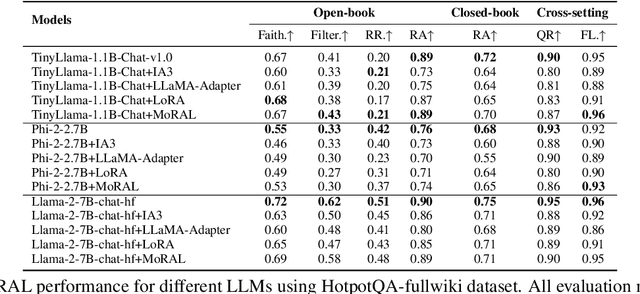
Adapting large language models (LLMs) to new domains/tasks and enabling them to be efficient lifelong learners is a pivotal challenge. In this paper, we propose MoRAL, i.e., Mixture-of-Experts augmented Low-Rank Adaptation for Lifelong Learning. MoRAL combines the multi-tasking abilities of MoE with the fine-tuning abilities of LoRA for effective life-long learning of LLMs. In contrast to the conventional approaches that use factual triplets as inputs MoRAL relies on simple question-answer pairs, which is a more practical and effective strategy for robust and efficient learning. Owing to new data settings, we introduce a new evaluation benchmark namely: Life Long Learning of LLM (5L-bench) encompassing a newly curated dataset of question-answer pairs, and a set of evaluation metrics for rigorous evaluation of MoRAL in open-book and closed-book settings. Experimental evaluation shows (i) LLMs learn fast in open-book settings with up to 30.15% improvement in "RA" for Phi-2-2.7B compared to closed-book (for models fine-tuned with MoRAL); (ii) MoRAL shows higher performance improvement for models with a greater number of parameters; (iii) MoRAL is robust to catastrophic forgetting offering better knowledge retention compared to baselines.
Communication Efficient and Provable Federated Unlearning
Jan 19, 2024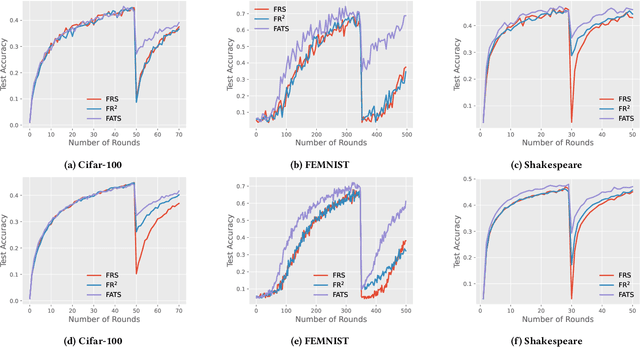
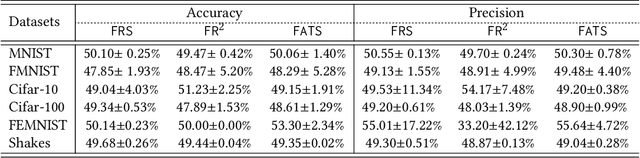
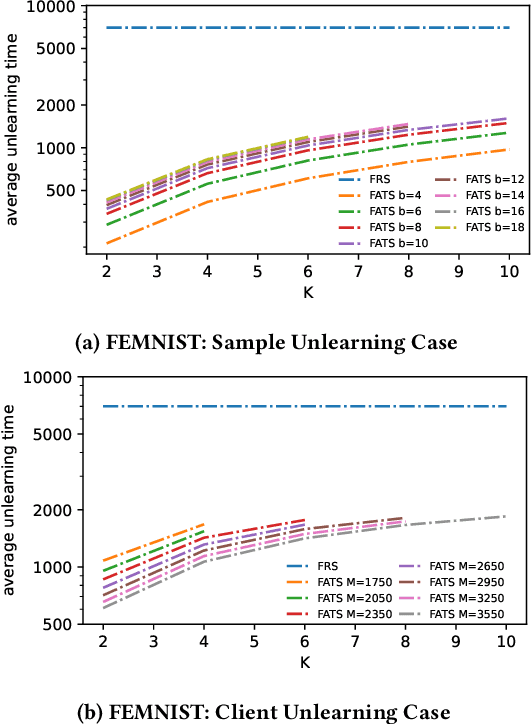

We study federated unlearning, a novel problem to eliminate the impact of specific clients or data points on the global model learned via federated learning (FL). This problem is driven by the right to be forgotten and the privacy challenges in FL. We introduce a new framework for exact federated unlearning that meets two essential criteria: \textit{communication efficiency} and \textit{exact unlearning provability}. To our knowledge, this is the first work to tackle both aspects coherently. We start by giving a rigorous definition of \textit{exact} federated unlearning, which guarantees that the unlearned model is statistically indistinguishable from the one trained without the deleted data. We then pinpoint the key property that enables fast exact federated unlearning: total variation (TV) stability, which measures the sensitivity of the model parameters to slight changes in the dataset. Leveraging this insight, we develop a TV-stable FL algorithm called \texttt{FATS}, which modifies the classical \texttt{\underline{F}ed\underline{A}vg} algorithm for \underline{T}V \underline{S}tability and employs local SGD with periodic averaging to lower the communication round. We also design efficient unlearning algorithms for \texttt{FATS} under two settings: client-level and sample-level unlearning. We provide theoretical guarantees for our learning and unlearning algorithms, proving that they achieve exact federated unlearning with reasonable convergence rates for both the original and unlearned models. We empirically validate our framework on 6 benchmark datasets, and show its superiority over state-of-the-art methods in terms of accuracy, communication cost, computation cost, and unlearning efficacy.
Differentially Private Non-convex Learning for Multi-layer Neural Networks
Oct 12, 2023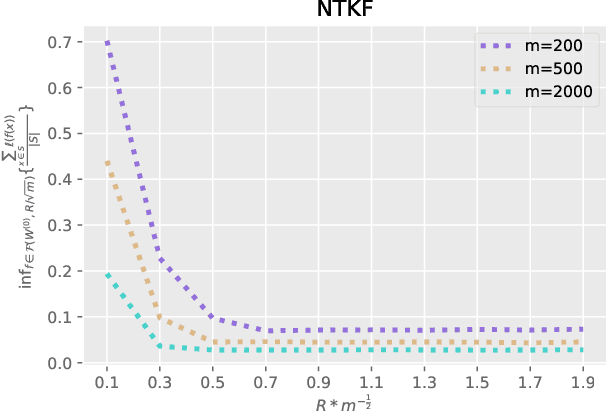
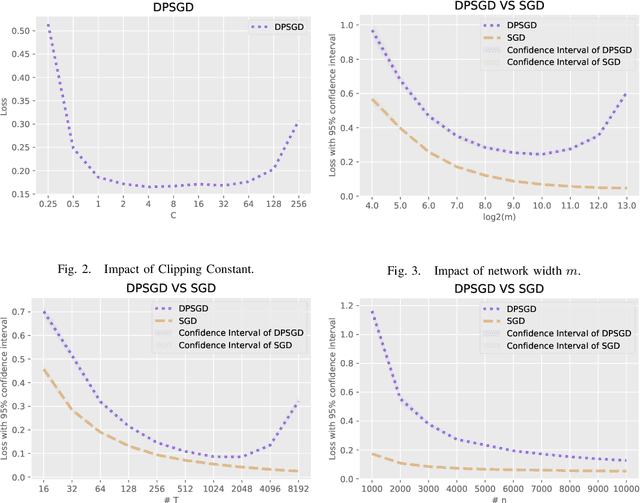
This paper focuses on the problem of Differentially Private Stochastic Optimization for (multi-layer) fully connected neural networks with a single output node. In the first part, we examine cases with no hidden nodes, specifically focusing on Generalized Linear Models (GLMs). We investigate the well-specific model where the random noise possesses a zero mean, and the link function is both bounded and Lipschitz continuous. We propose several algorithms and our analysis demonstrates the feasibility of achieving an excess population risk that remains invariant to the data dimension. We also delve into the scenario involving the ReLU link function, and our findings mirror those of the bounded link function. We conclude this section by contrasting well-specified and misspecified models, using ReLU regression as a representative example. In the second part of the paper, we extend our ideas to two-layer neural networks with sigmoid or ReLU activation functions in the well-specified model. In the third part, we study the theoretical guarantees of DP-SGD in Abadi et al. (2016) for fully connected multi-layer neural networks. By utilizing recent advances in Neural Tangent Kernel theory, we provide the first excess population risk when both the sample size and the width of the network are sufficiently large. Additionally, we discuss the role of some parameters in DP-SGD regarding their utility, both theoretically and empirically.
Inductive Graph Unlearning
Apr 07, 2023



As a way to implement the "right to be forgotten" in machine learning, \textit{machine unlearning} aims to completely remove the contributions and information of the samples to be deleted from a trained model without affecting the contributions of other samples. Recently, many frameworks for machine unlearning have been proposed, and most of them focus on image and text data. To extend machine unlearning to graph data, \textit{GraphEraser} has been proposed. However, a critical issue is that \textit{GraphEraser} is specifically designed for the transductive graph setting, where the graph is static and attributes and edges of test nodes are visible during training. It is unsuitable for the inductive setting, where the graph could be dynamic and the test graph information is invisible in advance. Such inductive capability is essential for production machine learning systems with evolving graphs like social media and transaction networks. To fill this gap, we propose the \underline{{\bf G}}\underline{{\bf U}}ided \underline{{\bf I}}n\underline{{\bf D}}uctiv\underline{{\bf E}} Graph Unlearning framework (GUIDE). GUIDE consists of three components: guided graph partitioning with fairness and balance, efficient subgraph repair, and similarity-based aggregation. Empirically, we evaluate our method on several inductive benchmarks and evolving transaction graphs. Generally speaking, GUIDE can be efficiently implemented on the inductive graph learning tasks for its low graph partition cost, no matter on computation or structure information. The code will be available here: https://github.com/Happy2Git/GUIDE.