 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanLLM: Towards Personalized Understanding and Simulation of Human Nature
Jan 22, 2026Motivated by the remarkable progress of large language models (LLMs) in objective tasks like mathematics and coding, there is growing interest in their potential to simulate human behavior--a capability with profound implications for transforming social science research and customer-centric business insights. However, LLMs often lack a nuanced understanding of human cognition and behavior, limiting their effectiveness in social simulation and personalized applications. We posit that this limitation stems from a fundamental misalignment: standard LLM pretraining on vast, uncontextualized web data does not capture the continuous, situated context of an individual's decisions, thoughts, and behaviors over time. To bridge this gap, we introduce HumanLLM, a foundation model designed for personalized understanding and simulation of individuals. We first construct the Cognitive Genome Dataset, a large-scale corpus curated from real-world user data on platforms like Reddit, Twitter, Blogger, and Amazon. Through a rigorous, multi-stage pipeline involving data filtering, synthesis, and quality control, we automatically extract over 5.5 million user logs to distill rich profiles, behaviors, and thinking patterns. We then formulate diverse learning tasks and perform supervised fine-tuning to empower the model to predict a wide range of individualized human behaviors, thoughts, and experiences. Comprehensive evaluations demonstrate that HumanLLM achieves superior performance in predicting user actions and inner thoughts, more accurately mimics user writing styles and preferences, and generates more authentic user profiles compared to base models. Furthermore, HumanLLM shows significant gains on out-of-domain social intelligence benchmarks, indicating enhanced generalization.
Controllable Concept Bottleneck Models
Jan 01, 2026Concept Bottleneck Models (CBMs) have garnered much attention for their ability to elucidate the prediction process through a human-understandable concept layer. However, most previous studies focused on static scenarios where the data and concepts are assumed to be fixed and clean. In real-world applications, deployed models require continuous maintenance: we often need to remove erroneous or sensitive data (unlearning), correct mislabeled concepts, or incorporate newly acquired samples (incremental learning) to adapt to evolving environments. Thus, deriving efficient editable CBMs without retraining from scratch remains a significant challenge, particularly in large-scale applications. To address these challenges, we propose Controllable Concept Bottleneck Models (CCBMs). Specifically, CCBMs support three granularities of model editing: concept-label-level, concept-level, and data-level, the latter of which encompasses both data removal and data addition. CCBMs enjoy mathematically rigorous closed-form approximations derived from influence functions that obviate the need for retraining. Experimental results demonstrate the efficiency and adaptability of our CCBMs, affirming their practical value in enabling dynamic and trustworthy CBMs.
Graph-Guided Dual-Level Augmentation for 3D Scene Segmentation
Jul 30, 20253D point cloud segmentation aims to assign semantic labels to individual points in a scene for fine-grained spatial understanding. Existing methods typically adopt data augmentation to alleviate the burden of large-scale annotation. However, most augmentation strategies only focus on local transformations or semantic recomposition, lacking the consideration of global structural dependencies within scenes. To address this limitation, we propose a graph-guided data augmentation framework with dual-level constraints for realistic 3D scene synthesis. Our method learns object relationship statistics from real-world data to construct guiding graphs for scene generation. Local-level constraints enforce geometric plausibility and semantic consistency between objects, while global-level constraints maintain the topological structure of the scene by aligning the generated layout with the guiding graph. Extensive experiments on indoor and outdoor datasets demonstrate that our framework generates diverse and high-quality augmented scenes, leading to consistent improvements in point cloud segmentation performance across various models.
Unveiling the Learning Mind of Language Models: A Cognitive Framework and Empirical Study
Jun 16, 2025
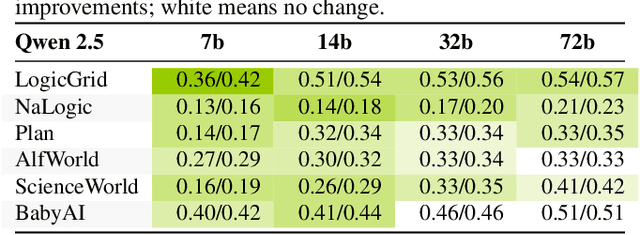

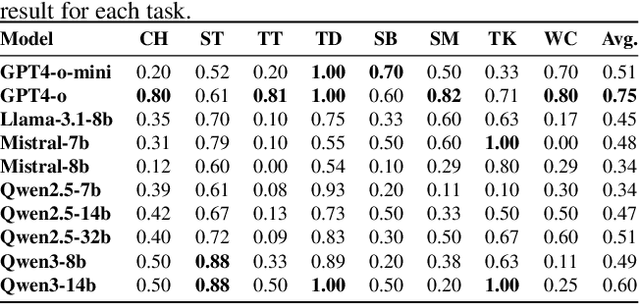
Large language models (LLMs) have shown impressive capabilities across tasks such as mathematics, coding, and reasoning, yet their learning ability, which is crucial for adapting to dynamic environments and acquiring new knowledge, remains underexplored. In this work, we address this gap by introducing a framework inspired by cognitive psychology and education. Specifically, we decompose general learning ability into three distinct, complementary dimensions: Learning from Instructor (acquiring knowledge via explicit guidance), Learning from Concept (internalizing abstract structures and generalizing to new contexts), and Learning from Experience (adapting through accumulated exploration and feedback). We conduct a comprehensive empirical study across the three learning dimensions and identify several insightful findings, such as (i) interaction improves learning; (ii) conceptual understanding is scale-emergent and benefits larger models; and (iii) LLMs are effective few-shot learners but not many-shot learners. Based on our framework and empirical findings, we introduce a benchmark that provides a unified and realistic evaluation of LLMs' general learning abilities across three learning cognition dimensions. It enables diagnostic insights and supports evaluation and development of more adaptive and human-like models.
LLM-powered Multi-agent Framework for Goal-oriented Learning in Intelligent Tutoring System
Jan 27, 2025



Intelligent Tutoring Systems (ITSs) have revolutionized education by offering personalized learning experiences. However, as goal-oriented learning, which emphasizes efficiently achieving specific objectives, becomes increasingly important in professional contexts, existing ITSs often struggle to deliver this type of targeted learning experience. In this paper, we propose GenMentor, an LLM-powered multi-agent framework designed to deliver goal-oriented, personalized learning within ITS. GenMentor begins by accurately mapping learners' goals to required skills using a fine-tuned LLM trained on a custom goal-to-skill dataset. After identifying the skill gap, it schedules an efficient learning path using an evolving optimization approach, driven by a comprehensive and dynamic profile of learners' multifaceted status. Additionally, GenMentor tailors learning content with an exploration-drafting-integration mechanism to align with individual learner needs. Extensive automated and human evaluations demonstrate GenMentor's effectiveness in learning guidance and content quality. Furthermore, we have deployed it in practice and also implemented it as an application. Practical human study with professional learners further highlights its effectiveness in goal alignment and resource targeting, leading to enhanced personalization. Supplementary resources are available at https://github.com/GeminiLight/gen-mentor.
Language Model Preference Evaluation with Multiple Weak Evaluators
Oct 14, 2024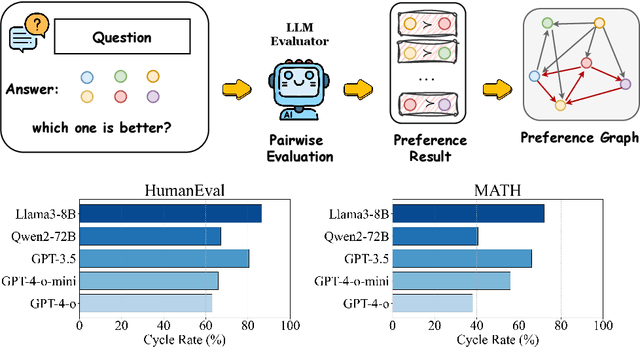
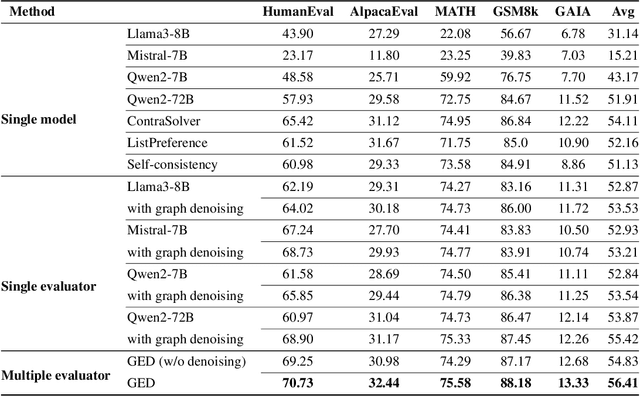
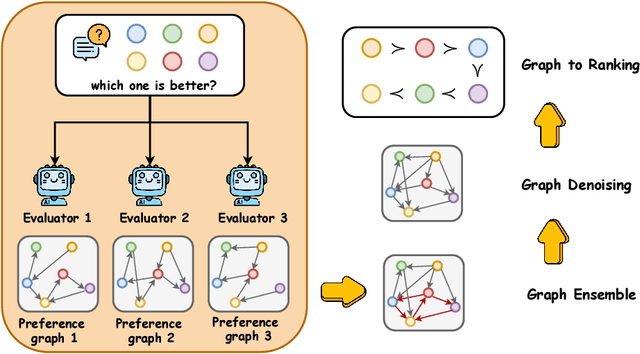
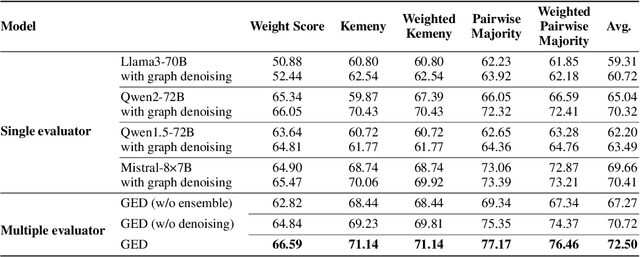
Despite the remarkable success of Large Language Models (LLMs), evaluating their outputs' quality regarding preference remains a critical challenge. Existing works usually leverage a powerful LLM (e.g., GPT4) as the judge for comparing LLMs' output pairwisely, yet such model-based evaluator is vulnerable to conflicting preference, i.e., output A is better than B, B than C, but C than A, causing contradictory evaluation results. To improve model-based preference evaluation, we introduce GED (Preference Graph Ensemble and Denoise), a novel approach that leverages multiple model-based evaluators to construct preference graphs, and then ensemble and denoise these graphs for better, non-contradictory evaluation results. In particular, our method consists of two primary stages: aggregating evaluations into a unified graph and applying a denoising process to eliminate cyclic inconsistencies, ensuring a directed acyclic graph (DAG) structure. We provide theoretical guarantees for our framework, demonstrating its efficacy in recovering the ground truth preference structure. Extensive experiments across ten benchmark datasets show that GED outperforms baseline methods in model ranking, response selection, and model alignment tasks. Notably, GED combines weaker evaluators like Llama3-8B, Mistral-7B, and Qwen2-7B to surpass the performance of stronger evaluators like Qwen2-72B, highlighting its ability to enhance evaluation reliability and improve model performance.
Let's Ask GNN: Empowering Large Language Model for Graph In-Context Learning
Oct 09, 2024



Textual Attributed Graphs (TAGs) are crucial for modeling complex real-world systems, yet leveraging large language models (LLMs) for TAGs presents unique challenges due to the gap between sequential text processing and graph-structured data. We introduce AskGNN, a novel approach that bridges this gap by leveraging In-Context Learning (ICL) to integrate graph data and task-specific information into LLMs. AskGNN employs a Graph Neural Network (GNN)-powered structure-enhanced retriever to select labeled nodes across graphs, incorporating complex graph structures and their supervision signals. Our learning-to-retrieve algorithm optimizes the retriever to select example nodes that maximize LLM performance on graph. Experiments across three tasks and seven LLMs demonstrate AskGNN's superior effectiveness in graph task performance, opening new avenues for applying LLMs to graph-structured data without extensive fine-tuning.
Rethinking LLM-based Preference Evaluation
Jul 01, 2024Recently, large language model (LLM)-based preference evaluation has been widely adopted to compare pairs of model responses. However, a severe bias towards lengthy responses has been observed, raising concerns about the reliability of this evaluation method. In this work, we designed a series of controlled experiments to study the major impacting factors of the metric of LLM-based preference evaluation, i.e., win rate, and conclude that the win rate is affected by two axes of model response: desirability and information mass, where the former is length-independent and related to trustworthiness, and the latter is length-dependent and can be represented by conditional entropy. We find that length impacts the existing evaluations by influencing information mass. However, a reliable evaluation metric should not only assess content quality but also ensure that the assessment is not confounded by extraneous factors such as response length. Therefore, we propose a simple yet effective adjustment, AdapAlpaca, to the existing practice of win rate measurement. Specifically, by adjusting the lengths of reference answers to match the test model's answers within the same interval, we debias information mass relative to length, ensuring a fair model evaluation.
Semi-supervised Concept Bottleneck Models
Jun 27, 2024Concept Bottleneck Models (CBMs) have garnered increasing attention due to their ability to provide concept-based explanations for black-box deep learning models while achieving high final prediction accuracy using human-like concepts. However, the training of current CBMs heavily relies on the accuracy and richness of annotated concepts in the dataset. These concept labels are typically provided by experts, which can be costly and require significant resources and effort. Additionally, concept saliency maps frequently misalign with input saliency maps, causing concept predictions to correspond to irrelevant input features - an issue related to annotation alignment. To address these limitations, we propose a new framework called SSCBM (Semi-supervised Concept Bottleneck Model). Our SSCBM is suitable for practical situations where annotated data is scarce. By leveraging joint training on both labeled and unlabeled data and aligning the unlabeled data at the concept level, we effectively solve these issues. We proposed a strategy to generate pseudo labels and an alignment loss. Experiments demonstrate that our SSCBM is both effective and efficient. With only 20% labeled data, we achieved 93.19% (96.39% in a fully supervised setting) concept accuracy and 75.51% (79.82% in a fully supervised setting) prediction accuracy.
Editable Concept Bottleneck Models
May 24, 2024Concept Bottleneck Models (CBMs) have garnered much attention for their ability to elucidate the prediction process through a human-understandable concept layer. However, most previous studies focused on cases where the data, including concepts, are clean. In many scenarios, we always need to remove/insert some training data or new concepts from trained CBMs due to different reasons, such as privacy concerns, data mislabelling, spurious concepts, and concept annotation errors. Thus, the challenge of deriving efficient editable CBMs without retraining from scratch persists, particularly in large-scale applications. To address these challenges, we propose Editable Concept Bottleneck Models (ECBMs). Specifically, ECBMs support three different levels of data removal: concept-label-level, concept-level, and data-level. ECBMs enjoy mathematically rigorous closed-form approximations derived from influence functions that obviate the need for re-training. Experimental results demonstrate the efficiency and effectiveness of our ECBMs, affirming their adaptability within the realm of CBMs.