 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-Based Reward Modeling for Computer-Use Agents
Mar 10, 2026Computer-using agents (CUAs) are becoming increasingly capable; however, it remains difficult to scale evaluation of whether a trajectory truly fulfills a user instruction. In this work, we study reward modeling from execution video: a sequence of keyframes from an agent trajectory that is independent of the agent's internal reasoning or actions. Although video-execution modeling is method-agnostic, it presents key challenges, including highly redundant layouts and subtle, localized cues that determine success. We introduce Execution Video Reward 53k (ExeVR-53k), a dataset of 53k high-quality video--task--reward triplets. We further propose adversarial instruction translation to synthesize negative samples with step-level annotations. To enable learning from long, high-resolution execution videos, we design spatiotemporal token pruning, which removes homogeneous regions and persistent tokens while preserving decisive UI changes. Building on these components, we fine-tune an Execution Video Reward Model (ExeVRM) that takes only a user instruction and a video-execution sequence to predict task success. Our ExeVRM 8B achieves 84.7% accuracy and 87.7% recall on video-execution assessment, outperforming strong proprietary models such as GPT-5.2 and Gemini-3 Pro across Ubuntu, macOS, Windows, and Android, while providing more precise temporal attribution. These results show that video-execution reward modeling can serve as a scalable, model-agnostic evaluator for CUAs.
Experiential Reinforcement Learning
Feb 15, 2026Reinforcement learning has become the central approach for language models (LMs) to learn from environmental reward or feedback. In practice, the environmental feedback is usually sparse and delayed. Learning from such signals is challenging, as LMs must implicitly infer how observed failures should translate into behavioral changes for future iterations. We introduce Experiential Reinforcement Learning (ERL), a training paradigm that embeds an explicit experience-reflection-consolidation loop into the reinforcement learning process. Given a task, the model generates an initial attempt, receives environmental feedback, and produces a reflection that guides a refined second attempt, whose success is reinforced and internalized into the base policy. This process converts feedback into structured behavioral revision, improving exploration and stabilizing optimization while preserving gains at deployment without additional inference cost. Across sparse-reward control environments and agentic reasoning benchmarks, ERL consistently improves learning efficiency and final performance over strong reinforcement learning baselines, achieving gains of up to +81% in complex multi-step environments and up to +11% in tool-using reasoning tasks. These results suggest that integrating explicit self-reflection into policy training provides a practical mechanism for transforming feedback into durable behavioral improvement.
CoAct-1: Computer-using Agents with Coding as Actions
Aug 05, 2025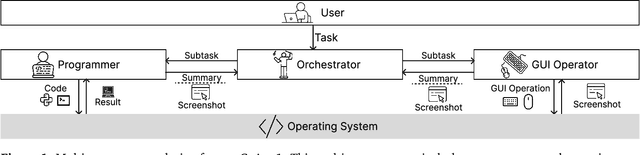
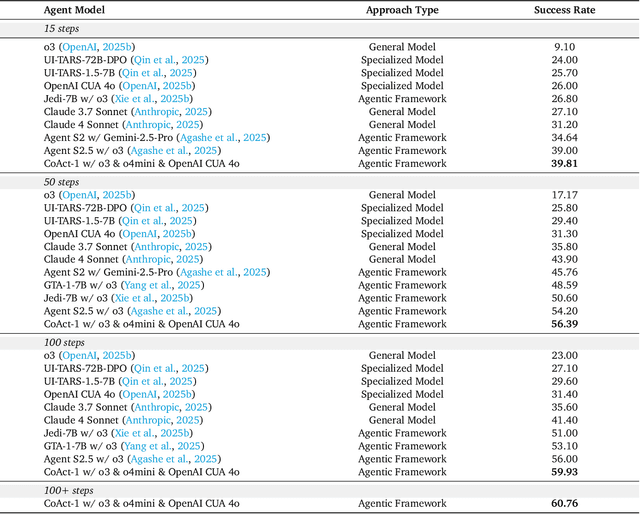
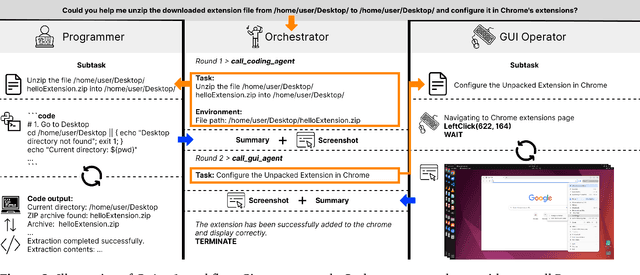

Autonomous agents that operate computers via Graphical User Interfaces (GUIs) often struggle with efficiency and reliability on complex, long-horizon tasks. While augmenting these agents with planners can improve task decomposition, they remain constrained by the inherent limitations of performing all actions through GUI manipulation, leading to brittleness and inefficiency. In this work, we introduce a more robust and flexible paradigm: enabling agents to use coding as a enhanced action. We present CoAct-1, a novel multi-agent system that synergistically combines GUI-based control with direct programmatic execution. CoAct-1 features an Orchestrator that dynamically delegates subtasks to either a conventional GUI Operator or a specialized Programmer agent, which can write and execute Python or Bash scripts. This hybrid approach allows the agent to bypass inefficient GUI action sequences for tasks like file management and data processing, while still leveraging visual interaction when necessary. We evaluate our system on the challenging OSWorld benchmark, where CoAct-1 achieves a new state-of-the-art success rate of 60.76%, significantly outperforming prior methods. Furthermore, our approach dramatically improves efficiency, reducing the average number of steps required to complete a task to just 10.15, compared to 15 for leading GUI agents. Our results demonstrate that integrating coding as a core action provides a more powerful, efficient, and scalable path toward generalized computer automation.
A Personalized Conversational Benchmark: Towards Simulating Personalized Conversations
May 20, 2025
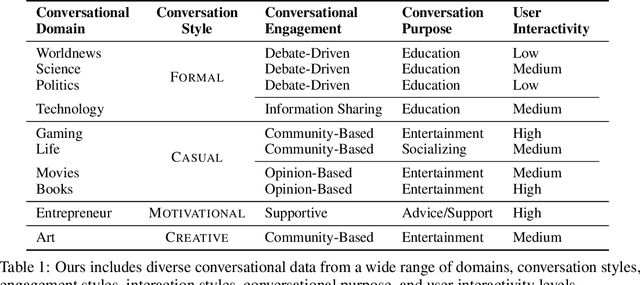
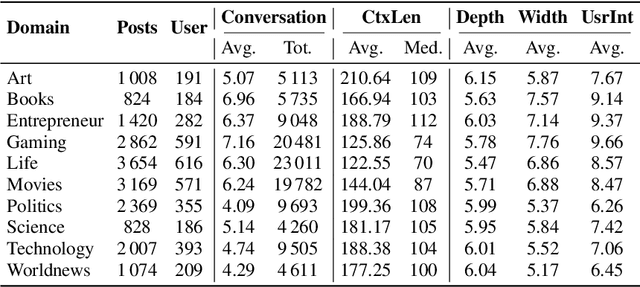
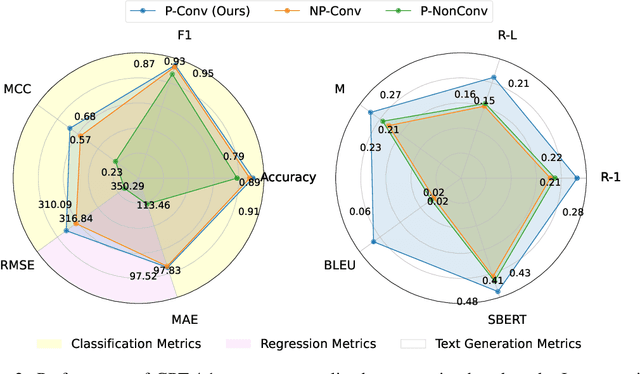
We present PersonaConvBench, a large-scale benchmark for evaluating personalized reasoning and generation in multi-turn conversations with large language models (LLMs). Unlike existing work that focuses on either personalization or conversational structure in isolation, PersonaConvBench integrates both, offering three core tasks: sentence classification, impact regression, and user-centric text generation across ten diverse Reddit-based domains. This design enables systematic analysis of how personalized conversational context shapes LLM outputs in realistic multi-user scenarios. We benchmark several commercial and open-source LLMs under a unified prompting setup and observe that incorporating personalized history yields substantial performance improvements, including a 198 percent relative gain over the best non-conversational baseline in sentiment classification. By releasing PersonaConvBench with evaluations and code, we aim to support research on LLMs that adapt to individual styles, track long-term context, and produce contextually rich, engaging responses.
The Hallucination Tax of Reinforcement Finetuning
May 20, 2025Reinforcement finetuning (RFT) has become a standard approach for enhancing the reasoning capabilities of large language models (LLMs). However, its impact on model trustworthiness remains underexplored. In this work, we identify and systematically study a critical side effect of RFT, which we term the hallucination tax: a degradation in refusal behavior causing models to produce hallucinated answers to unanswerable questions confidently. To investigate this, we introduce SUM (Synthetic Unanswerable Math), a high-quality dataset of unanswerable math problems designed to probe models' ability to recognize an unanswerable question by reasoning from the insufficient or ambiguous information. Our results show that standard RFT training could reduce model refusal rates by more than 80%, which significantly increases model's tendency to hallucinate. We further demonstrate that incorporating just 10% SUM during RFT substantially restores appropriate refusal behavior, with minimal accuracy trade-offs on solvable tasks. Crucially, this approach enables LLMs to leverage inference-time compute to reason about their own uncertainty and knowledge boundaries, improving generalization not only to out-of-domain math problems but also to factual question answering tasks.
Efficient Reinforcement Finetuning via Adaptive Curriculum Learning
Apr 07, 2025Reinforcement finetuning (RFT) has shown great potential for enhancing the mathematical reasoning capabilities of large language models (LLMs), but it is often sample- and compute-inefficient, requiring extensive training. In this work, we introduce AdaRFT (Adaptive Curriculum Reinforcement Finetuning), a method that significantly improves both the efficiency and final accuracy of RFT through adaptive curriculum learning. AdaRFT dynamically adjusts the difficulty of training problems based on the model's recent reward signals, ensuring that the model consistently trains on tasks that are challenging but solvable. This adaptive sampling strategy accelerates learning by maintaining an optimal difficulty range, avoiding wasted computation on problems that are too easy or too hard. AdaRFT requires only a lightweight extension to standard RFT algorithms like Proximal Policy Optimization (PPO), without modifying the reward function or model architecture. Experiments on competition-level math datasets-including AMC, AIME, and IMO-style problems-demonstrate that AdaRFT significantly improves both training efficiency and reasoning performance. We evaluate AdaRFT across multiple data distributions and model sizes, showing that it reduces the number of training steps by up to 2x and improves accuracy by a considerable margin, offering a more scalable and effective RFT framework.
Attributed Synthetic Data Generation for Zero-shot Domain-specific Image Classification
Apr 06, 2025Zero-shot domain-specific image classification is challenging in classifying real images without ground-truth in-domain training examples. Recent research involved knowledge from texts with a text-to-image model to generate in-domain training images in zero-shot scenarios. However, existing methods heavily rely on simple prompt strategies, limiting the diversity of synthetic training images, thus leading to inferior performance compared to real images. In this paper, we propose AttrSyn, which leverages large language models to generate attributed prompts. These prompts allow for the generation of more diverse attributed synthetic images. Experiments for zero-shot domain-specific image classification on two fine-grained datasets show that training with synthetic images generated by AttrSyn significantly outperforms CLIP's zero-shot classification under most situations and consistently surpasses simple prompt strategies.
Discovering Knowledge Deficiencies of Language Models on Massive Knowledge Base
Mar 30, 2025Large language models (LLMs) possess impressive linguistic capabilities but often fail to faithfully retain factual knowledge, leading to hallucinations and unreliable outputs. Understanding LLMs' knowledge deficiencies by exhaustively evaluating against full-scale knowledge bases is computationally prohibitive, especially for closed-weight models. We propose stochastic error ascent (SEA), a scalable and efficient framework for discovering knowledge deficiencies (errors) in closed-weight LLMs under a strict query budget. Rather than naively probing all knowledge candidates, SEA formulates error discovery as a stochastic optimization process: it iteratively retrieves new high-error candidates by leveraging the semantic similarity to previously observed failures. To further enhance search efficiency and coverage, SEA employs hierarchical retrieval across document and paragraph levels, and constructs a relation directed acyclic graph to model error propagation and identify systematic failure modes. Empirically, SEA uncovers 40.7x more knowledge errors than Automated Capability Discovery and 26.7% more than AutoBencher, while reducing the cost-per-error by 599x and 9x, respectively. Human evaluation confirms the high quality of generated questions, while ablation and convergence analyses validate the contribution of each component in SEA. Further analysis on the discovered errors reveals correlated failure patterns across LLM families and recurring deficits, highlighting the need for better data coverage and targeted fine-tuning in future LLM development.
Template Matters: Understanding the Role of Instruction Templates in Multimodal Language Model Evaluation and Training
Dec 11, 2024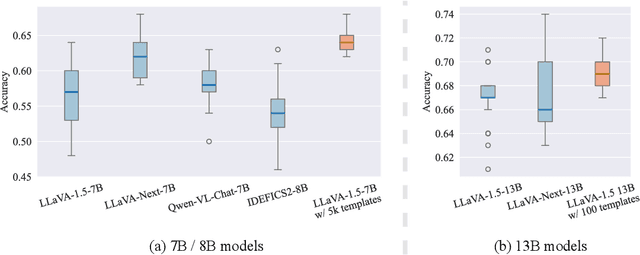
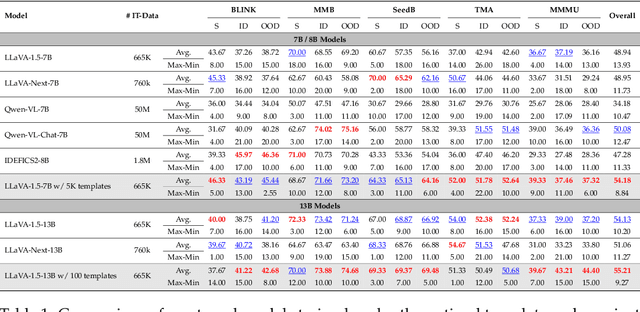

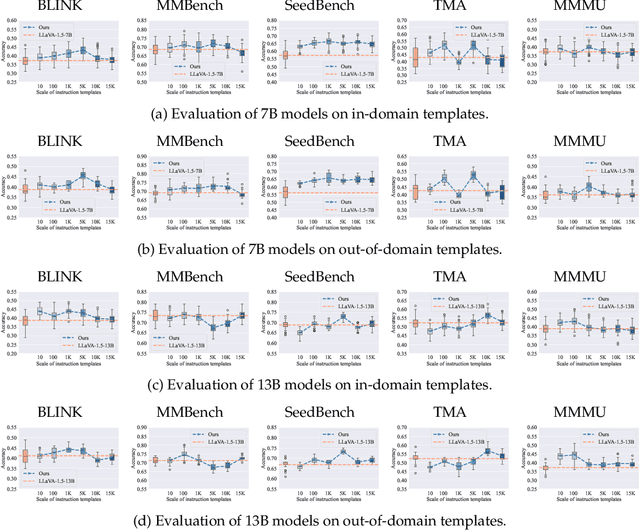
Current multimodal language models (MLMs) evaluation and training approaches overlook the influence of instruction format, presenting an elephant-in-the-room problem. Previous research deals with this problem by manually crafting instructions, failing to yield significant insights due to limitations in diversity and scalability. In this work, we propose a programmatic instruction template generator capable of producing over 39B unique template combinations by filling randomly sampled positional synonyms into weighted sampled meta templates, enabling us to comprehensively examine the MLM's performance across diverse instruction templates. Our experiments across eight common MLMs on five benchmark datasets reveal that MLMs have high template sensitivities with at most 29% performance gaps between different templates. We further augment the instruction tuning dataset of LLaVA-1.5 with our template generator and perform instruction tuning on LLaVA-1.5-7B and LLaVA-1.5-13B. Models tuned on our augmented dataset achieve the best overall performance when compared with the same scale MLMs tuned on at most 75 times the scale of our augmented dataset, highlighting the importance of instruction templates in MLM training. The code is available at https://github.com/shijian2001/TemplateMatters .
ProVision: Programmatically Scaling Vision-centric Instruction Data for Multimodal Language Models
Dec 09, 2024
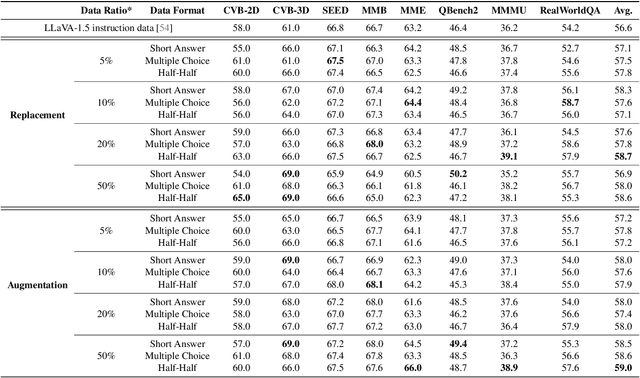
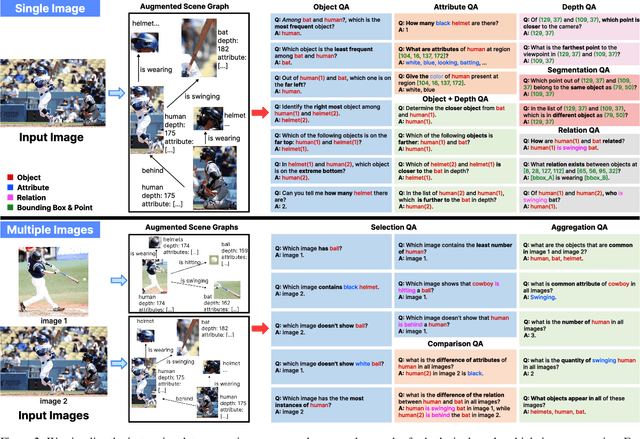
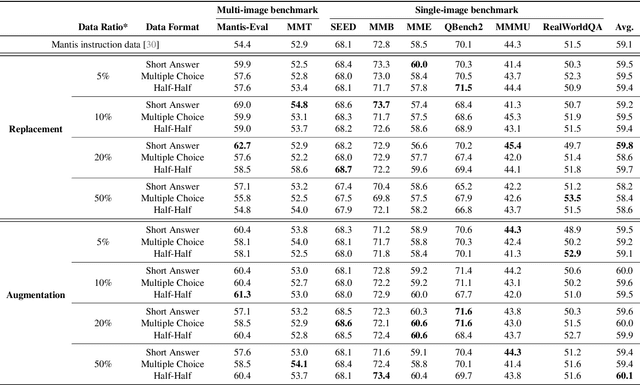
With the rise of multimodal applications, instruction data has become critical for training multimodal language models capable of understanding complex image-based queries. Existing practices rely on powerful but costly large language models (LLMs) or multimodal language models (MLMs) to produce instruction data. These are often prone to hallucinations, licensing issues and the generation process is often hard to scale and interpret. In this work, we present a programmatic approach that employs scene graphs as symbolic representations of images and human-written programs to systematically synthesize vision-centric instruction data. Our approach ensures the interpretability and controllability of the data generation process and scales efficiently while maintaining factual accuracy. By implementing a suite of 24 single-image, 14 multi-image instruction generators, and a scene graph generation pipeline, we build a scalable, cost-effective system: ProVision which produces diverse question-answer pairs concerning objects, attributes, relations, depth, etc., for any given image. Applied to Visual Genome and DataComp datasets, we generate over 10 million instruction data points, ProVision-10M, and leverage them in both pretraining and instruction tuning stages of MLMs. When adopted in the instruction tuning stage, our single-image instruction data yields up to a 7% improvement on the 2D split and 8% on the 3D split of CVBench, along with a 3% increase in performance on QBench2, RealWorldQA, and MMMU. Our multi-image instruction data leads to an 8% improvement on Mantis-Eval. Incorporation of our data in both pre-training and fine-tuning stages of xGen-MM-4B leads to an averaged improvement of 1.6% across 11 benchmarks.