 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehaviorBench: Modeling Real-World User Decisions from Behavioral Traces
Jun 01, 2026Many decision-support settings require systems that adapt to individual users, but evaluation data for this problem remain limited. Existing benchmarks for user understanding often rely on simulated users or model-generated behavior, even though recent work cautions that model-based simulations can diverge systematically from human behavior. We introduce \textsc{BehaviorBench}, a benchmark for evaluating personalized decision modeling from real-world behavioral traces. \textsc{BehaviorBench} reconstructs wallet-level decision histories from observed public prediction-market and on-chain records, and organizes them into two complementary task layers: \emph{Belief prediction}, which predicts a user's final revealed stance and confidence in a market, and \emph{Trade prediction}, which predicts the direction and amount of individual transactions. Across 2,000 evaluation wallets, the benchmark contains 141,445 Belief instances and 1,485,972 Trade instances, with disjoint support pools for retrieval-based evaluation. We evaluate frontier and open-weight generative models under four history interfaces: no personalization, direct recent history, generated user profiles, and retrieved support-wallet evidence. Personalization improves Belief prediction more consistently than Trade prediction, model rankings change across task layers and metrics, and different history interfaces expose different failure modes. \textsc{BehaviorBench} provides an evaluation setting for studying whether personalized methods can use real-world behavioral evidence rather than simulated users alone.
GPA: Learning GUI Process Automation from Demonstrations
Apr 02, 2026GUI Process Automation (GPA) is a lightweight but general vision-based Robotic Process Automation (RPA), which enables fast and stable process replay with only a single demo. Addressing the fragility of traditional RPA and the non-deterministic risks of current vision language model-based GUI agents, GPA introduces three core benefits: (1) Robustness via Sequential Monte Carlo-based localization to handle rescaling and detection uncertainty; (2) Deterministic and Reliability safeguarded by readiness calibration; and (3) Privacy through fast, fully local execution. This approach delivers the adaptability, robustness, and security required for enterprise workflows. It can also be used as an MCP/CLI tool by other agents with coding capabilities so that the agent only reasons and orchestrates while GPA handles the GUI execution. We conducted a pilot experiment to compare GPA with Gemini 3 Pro (with CUA tools) and found that GPA achieves higher success rate with 10 times faster execution speed in finishing long-horizon GUI tasks.
Position: Vector Prompt Interfaces Should Be Exposed to Enable Customization of Large Language Models
Mar 04, 2026As large language models (LLMs) transition from research prototypes to real-world systems, customization has emerged as a central bottleneck. While text prompts can already customize LLM behavior, we argue that text-only prompting does not constitute a suitable control interface for scalable, stable, and inference-only customization. This position paper argues that model providers should expose \emph{vector prompt inputs} as part of the public interface for customizing LLMs. We support this position with diagnostic evidence showing that vector prompt tuning continues to improve with increasing supervision whereas text-based prompt optimization saturates early, and that vector prompts exhibit dense, global attention patterns indicative of a distinct control mechanism. We further discuss why inference-only customization is increasingly important under realistic deployment constraints, and why exposing vector prompts need not fundamentally increase model leakage risk under a standard black-box threat model. We conclude with a call to action for the community to rethink prompt interfaces as a core component of LLM customization.
AudioCapBench: Quick Evaluation on Audio Captioning across Sound, Music, and Speech
Feb 27, 2026We introduce AudioCapBench, a benchmark for evaluating audio captioning capabilities of large multimodal models. \method covers three distinct audio domains, including environmental sound, music, and speech, with 1,000 curated evaluation samples drawn from established datasets. We evaluate 13 models across two providers (OpenAI, Google Gemini) using both reference-based metrics (METEOR, BLEU, ROUGE-L) and an LLM-as-Judge framework that scores predictions on three orthogonal dimensions: \textit{accuracy} (semantic correctness), \textit{completeness} (coverage of reference content), and \textit{hallucination} (absence of fabricated content). Our results reveal that Gemini models generally outperform OpenAI models on overall captioning quality, with Gemini~3~Pro achieving the highest overall score (6.00/10), while OpenAI models exhibit lower hallucination rates. All models perform best on speech captioning and worst on music captioning. We release the benchmark as well as evaluation code to facilitate reproducible audio understanding research.
W&D:Scaling Parallel Tool Calling for Efficient Deep Research Agents
Feb 07, 2026Deep research agents have emerged as powerful tools for automating complex intellectual tasks through multi-step reasoning and web-based information seeking. While recent efforts have successfully enhanced these agents by scaling depth through increasing the number of sequential thinking and tool calls, the potential of scaling width via parallel tool calling remains largely unexplored. In this work, we propose the Wide and Deep research agent, a framework designed to investigate the behavior and performance of agents when scaling not only depth but also width via parallel tool calling. Unlike existing approaches that rely on complex multi-agent orchestration to parallelize workloads, our method leverages intrinsic parallel tool calling to facilitate effective coordination within a single reasoning step. We demonstrate that scaling width significantly improves performance on deep research benchmarks while reducing the number of turns required to obtain correct answers. Furthermore, we analyze the factors driving these improvements through case studies and explore various tool call schedulers to optimize parallel tool calling strategy. Our findings suggest that optimizing the trade-off between width and depth is a critical pathway toward high-efficiency deep research agents. Notably, without context management or other tricks, we obtain 62.2% accuracy with GPT-5-Medium on BrowseComp, surpassing the original 54.9% reported by GPT-5-High.
Future Optical Flow Prediction Improves Robot Control & Video Generation
Jan 15, 2026Future motion representations, such as optical flow, offer immense value for control and generative tasks. However, forecasting generalizable spatially dense motion representations remains a key challenge, and learning such forecasting from noisy, real-world data remains relatively unexplored. We introduce FOFPred, a novel language-conditioned optical flow forecasting model featuring a unified Vision-Language Model (VLM) and Diffusion architecture. This unique combination enables strong multimodal reasoning with pixel-level generative fidelity for future motion prediction. Our model is trained on web-scale human activity data-a highly scalable but unstructured source. To extract meaningful signals from this noisy video-caption data, we employ crucial data preprocessing techniques and our unified architecture with strong image pretraining. The resulting trained model is then extended to tackle two distinct downstream tasks in control and generation. Evaluations across robotic manipulation and video generation under language-driven settings establish the cross-domain versatility of FOFPred, confirming the value of a unified VLM-Diffusion architecture and scalable learning from diverse web data for future optical flow prediction.
Robotic VLA Benefits from Joint Learning with Motion Image Diffusion
Dec 19, 2025Vision-Language-Action (VLA) models have achieved remarkable progress in robotic manipulation by mapping multimodal observations and instructions directly to actions. However, they typically mimic expert trajectories without predictive motion reasoning, which limits their ability to reason about what actions to take. To address this limitation, we propose joint learning with motion image diffusion, a novel strategy that enhances VLA models with motion reasoning capabilities. Our method extends the VLA architecture with a dual-head design: while the action head predicts action chunks as in vanilla VLAs, an additional motion head, implemented as a Diffusion Transformer (DiT), predicts optical-flow-based motion images that capture future dynamics. The two heads are trained jointly, enabling the shared VLM backbone to learn representations that couple robot control with motion knowledge. This joint learning builds temporally coherent and physically grounded representations without modifying the inference pathway of standard VLAs, thereby maintaining test-time latency. Experiments in both simulation and real-world environments demonstrate that joint learning with motion image diffusion improves the success rate of pi-series VLAs to 97.5% on the LIBERO benchmark and 58.0% on the RoboTwin benchmark, yielding a 23% improvement in real-world performance and validating its effectiveness in enhancing the motion reasoning capability of large-scale VLAs.
LoCoBench-Agent: An Interactive Benchmark for LLM Agents in Long-Context Software Engineering
Nov 17, 2025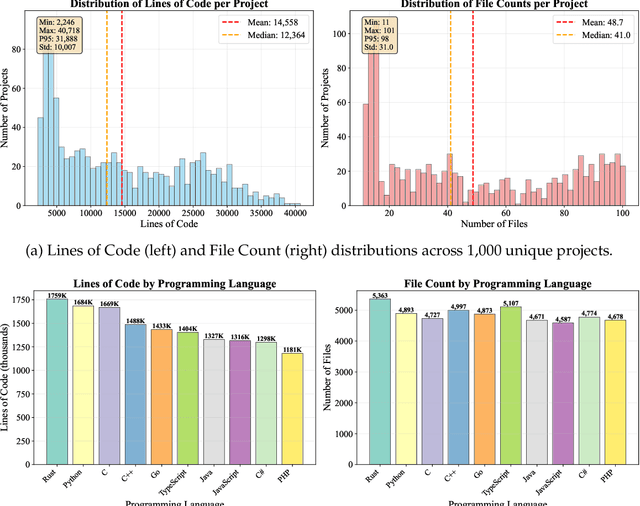
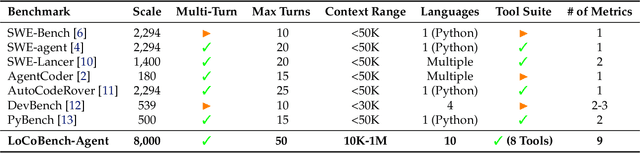

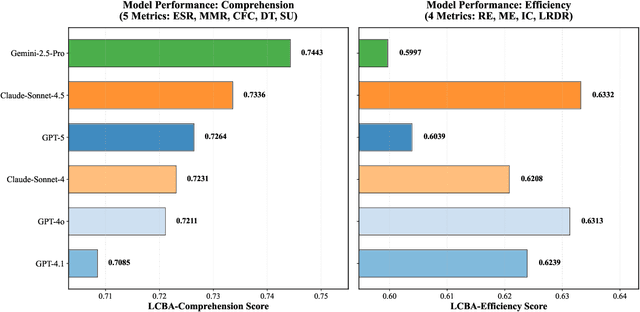
As large language models (LLMs) evolve into sophisticated autonomous agents capable of complex software development tasks, evaluating their real-world capabilities becomes critical. While existing benchmarks like LoCoBench~\cite{qiu2025locobench} assess long-context code understanding, they focus on single-turn evaluation and cannot capture the multi-turn interactive nature, tool usage patterns, and adaptive reasoning required by real-world coding agents. We introduce \textbf{LoCoBench-Agent}, a comprehensive evaluation framework specifically designed to assess LLM agents in realistic, long-context software engineering workflows. Our framework extends LoCoBench's 8,000 scenarios into interactive agent environments, enabling systematic evaluation of multi-turn conversations, tool usage efficiency, error recovery, and architectural consistency across extended development sessions. We also introduce an evaluation methodology with 9 metrics across comprehension and efficiency dimensions. Our framework provides agents with 8 specialized tools (file operations, search, code analysis) and evaluates them across context lengths ranging from 10K to 1M tokens, enabling precise assessment of long-context performance. Through systematic evaluation of state-of-the-art models, we reveal several key findings: (1) agents exhibit remarkable long-context robustness; (2) comprehension-efficiency trade-off exists with negative correlation, where thorough exploration increases comprehension but reduces efficiency; and (3) conversation efficiency varies dramatically across models, with strategic tool usage patterns differentiating high-performing agents. As the first long-context LLM agent benchmark for software engineering, LoCoBench-Agent establishes a rigorous foundation for measuring agent capabilities, identifying performance gaps, and advancing autonomous software development at scale.
SSR: Socratic Self-Refine for Large Language Model Reasoning
Nov 13, 2025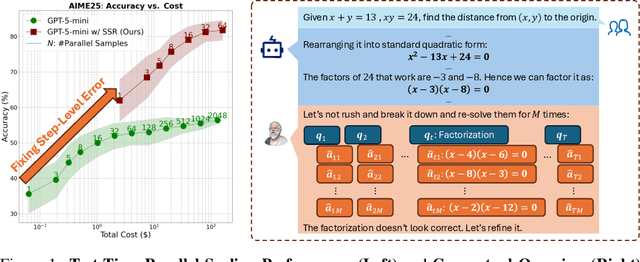
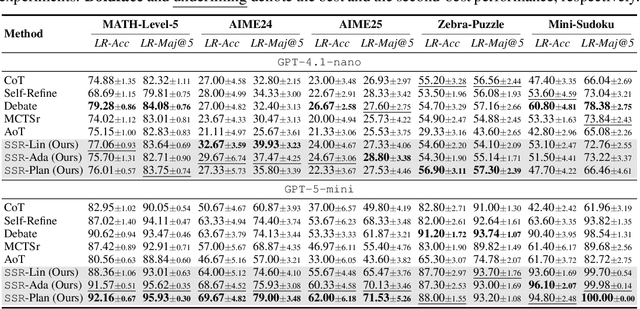
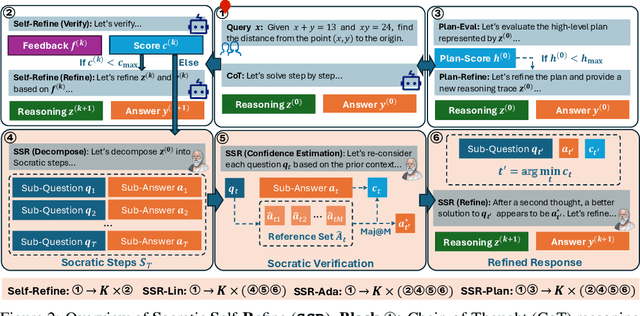
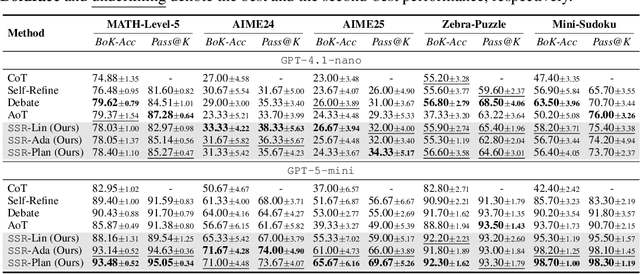
Large Language Models (LLMs) have demonstrated remarkable reasoning abilities, yet existing test-time frameworks often rely on coarse self-verification and self-correction, limiting their effectiveness on complex tasks. In this paper, we propose Socratic Self-Refine (SSR), a novel framework for fine-grained evaluation and precise refinement of LLM reasoning. Our proposed SSR decomposes model responses into verifiable (sub-question, sub-answer) pairs, enabling step-level confidence estimation through controlled re-solving and self-consistency checks. By pinpointing unreliable steps and iteratively refining them, SSR produces more accurate and interpretable reasoning chains. Empirical results across five reasoning benchmarks and three LLMs show that SSR consistently outperforms state-of-the-art iterative self-refinement baselines. Beyond performance gains, SSR provides a principled black-box approach for evaluating and understanding the internal reasoning processes of LLMs. Code is available at https://github.com/SalesforceAIResearch/socratic-self-refine-reasoning.
Moirai 2.0: When Less Is More for Time Series Forecasting
Nov 12, 2025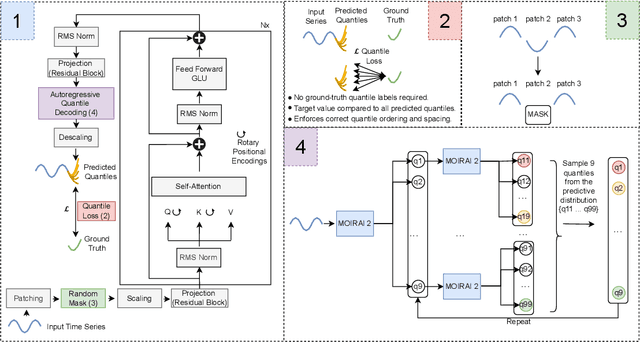
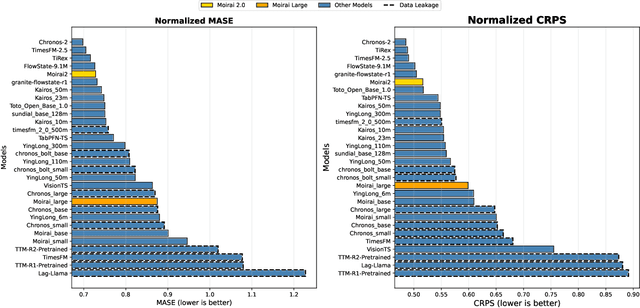

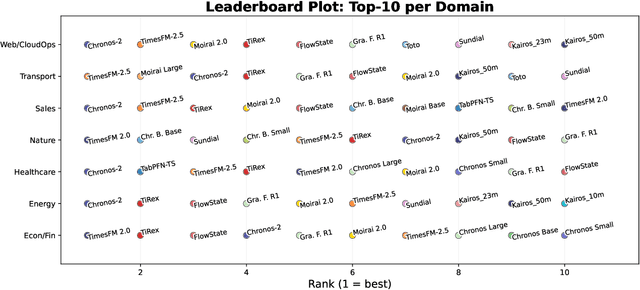
We introduce Moirai 2.0, a decoder-only time-series foundation model trained on a new corpus of 36M series. The model adopts quantile forecasting and multi-token prediction, improving both probabilistic accuracy and inference efficiency. On the Gift-Eval benchmark, it ranks among the top pretrained models while achieving a strong trade-off between accuracy, speed, and model size. Compared to Moirai 1.0, Moirai 2.0 replaces masked-encoder training, multi-patch inputs, and mixture-distribution outputs with a simpler decoder-only architecture, single patch, and quantile loss. Ablation studies isolate these changes -- showing that the decoder-only backbone along with recursive multi-quantile decoding contribute most to the gains. Additional experiments show that Moirai 2.0 outperforms larger models from the same family and exhibits robust domain-level results. In terms of efficiency and model size, Moirai 2.0 is twice as fast and thirty times smaller than its prior best version, Moirai 1.0-Large, while also performing better. Model performance plateaus with increasing parameter count and declines at longer horizons, motivating future work on data scaling and long-horizon modeling. We release code and evaluation details to support further research.