 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehaviorBench: Modeling Real-World User Decisions from Behavioral Traces
Jun 01, 2026Many decision-support settings require systems that adapt to individual users, but evaluation data for this problem remain limited. Existing benchmarks for user understanding often rely on simulated users or model-generated behavior, even though recent work cautions that model-based simulations can diverge systematically from human behavior. We introduce \textsc{BehaviorBench}, a benchmark for evaluating personalized decision modeling from real-world behavioral traces. \textsc{BehaviorBench} reconstructs wallet-level decision histories from observed public prediction-market and on-chain records, and organizes them into two complementary task layers: \emph{Belief prediction}, which predicts a user's final revealed stance and confidence in a market, and \emph{Trade prediction}, which predicts the direction and amount of individual transactions. Across 2,000 evaluation wallets, the benchmark contains 141,445 Belief instances and 1,485,972 Trade instances, with disjoint support pools for retrieval-based evaluation. We evaluate frontier and open-weight generative models under four history interfaces: no personalization, direct recent history, generated user profiles, and retrieved support-wallet evidence. Personalization improves Belief prediction more consistently than Trade prediction, model rankings change across task layers and metrics, and different history interfaces expose different failure modes. \textsc{BehaviorBench} provides an evaluation setting for studying whether personalized methods can use real-world behavioral evidence rather than simulated users alone.
Position: Vector Prompt Interfaces Should Be Exposed to Enable Customization of Large Language Models
Mar 04, 2026As large language models (LLMs) transition from research prototypes to real-world systems, customization has emerged as a central bottleneck. While text prompts can already customize LLM behavior, we argue that text-only prompting does not constitute a suitable control interface for scalable, stable, and inference-only customization. This position paper argues that model providers should expose \emph{vector prompt inputs} as part of the public interface for customizing LLMs. We support this position with diagnostic evidence showing that vector prompt tuning continues to improve with increasing supervision whereas text-based prompt optimization saturates early, and that vector prompts exhibit dense, global attention patterns indicative of a distinct control mechanism. We further discuss why inference-only customization is increasingly important under realistic deployment constraints, and why exposing vector prompts need not fundamentally increase model leakage risk under a standard black-box threat model. We conclude with a call to action for the community to rethink prompt interfaces as a core component of LLM customization.
AudioCapBench: Quick Evaluation on Audio Captioning across Sound, Music, and Speech
Feb 27, 2026We introduce AudioCapBench, a benchmark for evaluating audio captioning capabilities of large multimodal models. \method covers three distinct audio domains, including environmental sound, music, and speech, with 1,000 curated evaluation samples drawn from established datasets. We evaluate 13 models across two providers (OpenAI, Google Gemini) using both reference-based metrics (METEOR, BLEU, ROUGE-L) and an LLM-as-Judge framework that scores predictions on three orthogonal dimensions: \textit{accuracy} (semantic correctness), \textit{completeness} (coverage of reference content), and \textit{hallucination} (absence of fabricated content). Our results reveal that Gemini models generally outperform OpenAI models on overall captioning quality, with Gemini~3~Pro achieving the highest overall score (6.00/10), while OpenAI models exhibit lower hallucination rates. All models perform best on speech captioning and worst on music captioning. We release the benchmark as well as evaluation code to facilitate reproducible audio understanding research.
LoCoBench-Agent: An Interactive Benchmark for LLM Agents in Long-Context Software Engineering
Nov 17, 2025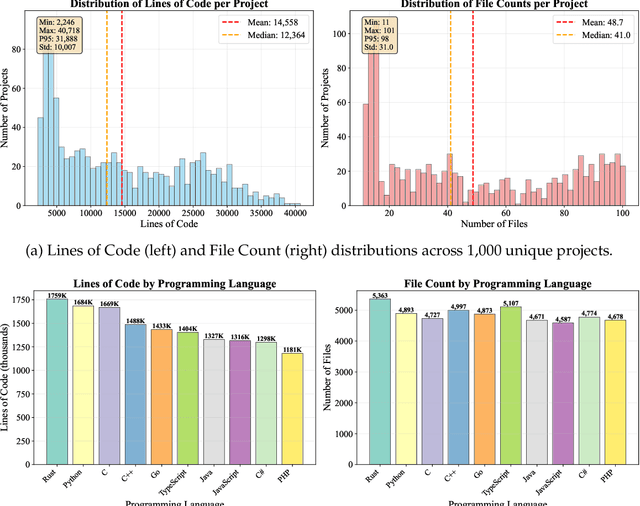
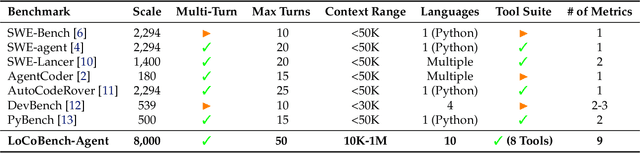

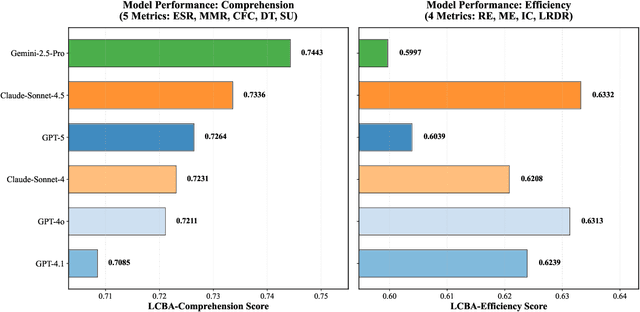
As large language models (LLMs) evolve into sophisticated autonomous agents capable of complex software development tasks, evaluating their real-world capabilities becomes critical. While existing benchmarks like LoCoBench~\cite{qiu2025locobench} assess long-context code understanding, they focus on single-turn evaluation and cannot capture the multi-turn interactive nature, tool usage patterns, and adaptive reasoning required by real-world coding agents. We introduce \textbf{LoCoBench-Agent}, a comprehensive evaluation framework specifically designed to assess LLM agents in realistic, long-context software engineering workflows. Our framework extends LoCoBench's 8,000 scenarios into interactive agent environments, enabling systematic evaluation of multi-turn conversations, tool usage efficiency, error recovery, and architectural consistency across extended development sessions. We also introduce an evaluation methodology with 9 metrics across comprehension and efficiency dimensions. Our framework provides agents with 8 specialized tools (file operations, search, code analysis) and evaluates them across context lengths ranging from 10K to 1M tokens, enabling precise assessment of long-context performance. Through systematic evaluation of state-of-the-art models, we reveal several key findings: (1) agents exhibit remarkable long-context robustness; (2) comprehension-efficiency trade-off exists with negative correlation, where thorough exploration increases comprehension but reduces efficiency; and (3) conversation efficiency varies dramatically across models, with strategic tool usage patterns differentiating high-performing agents. As the first long-context LLM agent benchmark for software engineering, LoCoBench-Agent establishes a rigorous foundation for measuring agent capabilities, identifying performance gaps, and advancing autonomous software development at scale.
GeoGNN: Quantifying and Mitigating Semantic Drift in Text-Attributed Graphs
Nov 12, 2025Graph neural networks (GNNs) on text--attributed graphs (TAGs) typically encode node texts using pretrained language models (PLMs) and propagate these embeddings through linear neighborhood aggregation. However, the representation spaces of modern PLMs are highly non--linear and geometrically structured, where textual embeddings reside on curved semantic manifolds rather than flat Euclidean spaces. Linear aggregation on such manifolds inevitably distorts geometry and causes semantic drift--a phenomenon where aggregated representations deviate from the intrinsic manifold, losing semantic fidelity and expressive power. To quantitatively investigate this problem, this work introduces a local PCA--based metric that measures the degree of semantic drift and provides the first quantitative framework to analyze how different aggregation mechanisms affect manifold structure. Building upon these insights, we propose Geodesic Aggregation, a manifold--aware mechanism that aggregates neighbor information along geodesics via log--exp mappings on the unit sphere, ensuring that representations remain faithful to the semantic manifold during message passing. We further develop GeoGNN, a practical instantiation that integrates spherical attention with manifold interpolation. Extensive experiments across four benchmark datasets and multiple text encoders show that GeoGNN substantially mitigates semantic drift and consistently outperforms strong baselines, establishing the importance of manifold--aware aggregation in text--attributed graph learning.
LoCoBench: A Benchmark for Long-Context Large Language Models in Complex Software Engineering
Sep 11, 2025



The emergence of long-context language models with context windows extending to millions of tokens has created new opportunities for sophisticated code understanding and software development evaluation. We propose LoCoBench, a comprehensive benchmark specifically designed to evaluate long-context LLMs in realistic, complex software development scenarios. Unlike existing code evaluation benchmarks that focus on single-function completion or short-context tasks, LoCoBench addresses the critical evaluation gap for long-context capabilities that require understanding entire codebases, reasoning across multiple files, and maintaining architectural consistency across large-scale software systems. Our benchmark provides 8,000 evaluation scenarios systematically generated across 10 programming languages, with context lengths spanning 10K to 1M tokens, a 100x variation that enables precise assessment of long-context performance degradation in realistic software development settings. LoCoBench introduces 8 task categories that capture essential long-context capabilities: architectural understanding, cross-file refactoring, multi-session development, bug investigation, feature implementation, code comprehension, integration testing, and security analysis. Through a 5-phase pipeline, we create diverse, high-quality scenarios that challenge LLMs to reason about complex codebases at unprecedented scale. We introduce a comprehensive evaluation framework with 17 metrics across 4 dimensions, including 8 new evaluation metrics, combined in a LoCoBench Score (LCBS). Our evaluation of state-of-the-art long-context models reveals substantial performance gaps, demonstrating that long-context understanding in complex software development represents a significant unsolved challenge that demands more attention. LoCoBench is released at: https://github.com/SalesforceAIResearch/LoCoBench.
MoDoMoDo: Multi-Domain Data Mixtures for Multimodal LLM Reinforcement Learning
May 30, 2025



Reinforcement Learning with Verifiable Rewards (RLVR) has recently emerged as a powerful paradigm for post-training large language models (LLMs), achieving state-of-the-art performance on tasks with structured, verifiable answers. Applying RLVR to Multimodal LLMs (MLLMs) presents significant opportunities but is complicated by the broader, heterogeneous nature of vision-language tasks that demand nuanced visual, logical, and spatial capabilities. As such, training MLLMs using RLVR on multiple datasets could be beneficial but creates challenges with conflicting objectives from interaction among diverse datasets, highlighting the need for optimal dataset mixture strategies to improve generalization and reasoning. We introduce a systematic post-training framework for Multimodal LLM RLVR, featuring a rigorous data mixture problem formulation and benchmark implementation. Specifically, (1) We developed a multimodal RLVR framework for multi-dataset post-training by curating a dataset that contains different verifiable vision-language problems and enabling multi-domain online RL learning with different verifiable rewards; (2) We proposed a data mixture strategy that learns to predict the RL fine-tuning outcome from the data mixture distribution, and consequently optimizes the best mixture. Comprehensive experiments showcase that multi-domain RLVR training, when combined with mixture prediction strategies, can significantly boost MLLM general reasoning capacities. Our best mixture improves the post-trained model's accuracy on out-of-distribution benchmarks by an average of 5.24% compared to the same model post-trained with uniform data mixture, and by a total of 20.74% compared to the pre-finetuning baseline.
Evaluating Durability: Benchmark Insights into Multimodal Watermarking
Jun 06, 2024



With the development of large models, watermarks are increasingly employed to assert copyright, verify authenticity, or monitor content distribution. As applications become more multimodal, the utility of watermarking techniques becomes even more critical. The effectiveness and reliability of these watermarks largely depend on their robustness to various disturbances. However, the robustness of these watermarks in real-world scenarios, particularly under perturbations and corruption, is not well understood. To highlight the significance of robustness in watermarking techniques, our study evaluated the robustness of watermarked content generated by image and text generation models against common real-world image corruptions and text perturbations. Our results could pave the way for the development of more robust watermarking techniques in the future. Our project website can be found at \url{https://mmwatermark-robustness.github.io/}.
Entity6K: A Large Open-Domain Evaluation Dataset for Real-World Entity Recognition
Mar 19, 2024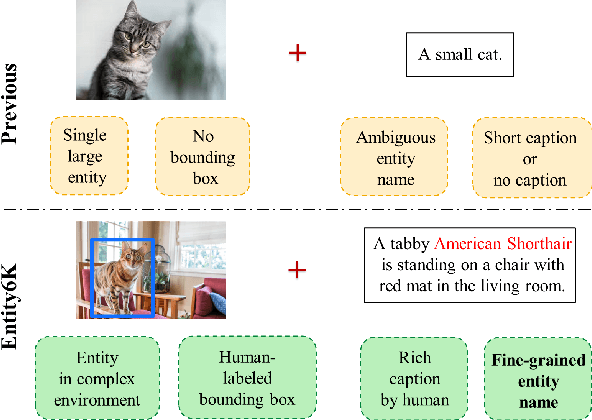
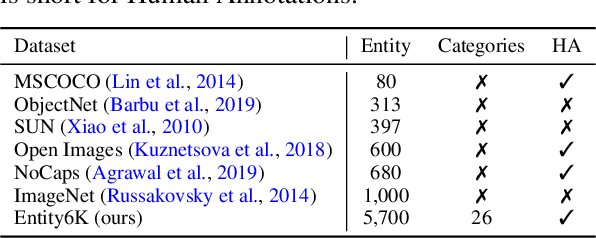

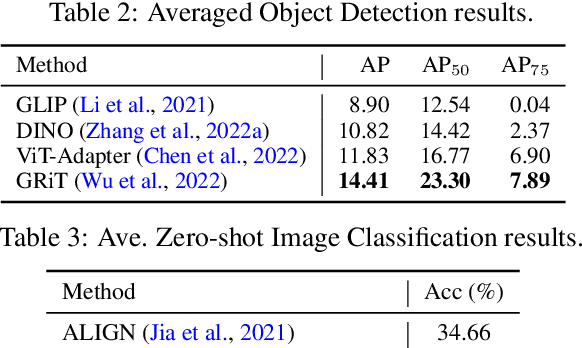
Open-domain real-world entity recognition is essential yet challenging, involving identifying various entities in diverse environments. The lack of a suitable evaluation dataset has been a major obstacle in this field due to the vast number of entities and the extensive human effort required for data curation. We introduce Entity6K, a comprehensive dataset for real-world entity recognition, featuring 5,700 entities across 26 categories, each supported by 5 human-verified images with annotations. Entity6K offers a diverse range of entity names and categorizations, addressing a gap in existing datasets. We conducted benchmarks with existing models on tasks like image captioning, object detection, zero-shot classification, and dense captioning to demonstrate Entity6K's effectiveness in evaluating models' entity recognition capabilities. We believe Entity6K will be a valuable resource for advancing accurate entity recognition in open-domain settings.
SnapNTell: Enhancing Entity-Centric Visual Question Answering with Retrieval Augmented Multimodal LLM
Mar 07, 2024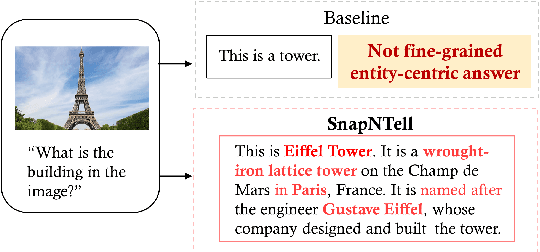

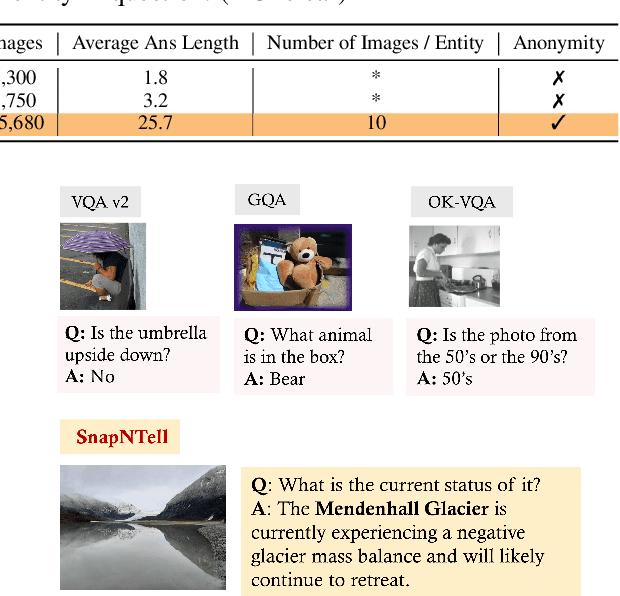
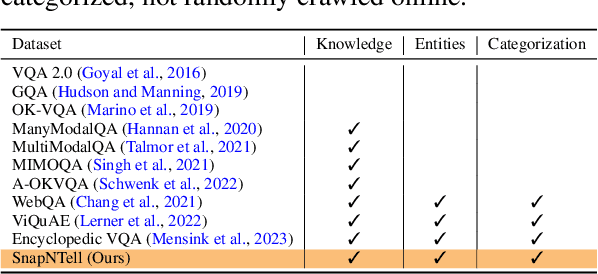
Vision-extended LLMs have made significant strides in Visual Question Answering (VQA). Despite these advancements, VLLMs still encounter substantial difficulties in handling queries involving long-tail entities, with a tendency to produce erroneous or hallucinated responses. In this work, we introduce a novel evaluative benchmark named \textbf{SnapNTell}, specifically tailored for entity-centric VQA. This task aims to test the models' capabilities in identifying entities and providing detailed, entity-specific knowledge. We have developed the \textbf{SnapNTell Dataset}, distinct from traditional VQA datasets: (1) It encompasses a wide range of categorized entities, each represented by images and explicitly named in the answers; (2) It features QA pairs that require extensive knowledge for accurate responses. The dataset is organized into 22 major categories, containing 7,568 unique entities in total. For each entity, we curated 10 illustrative images and crafted 10 knowledge-intensive QA pairs. To address this novel task, we devised a scalable, efficient, and transparent retrieval-augmented multimodal LLM. Our approach markedly outperforms existing methods on the SnapNTell dataset, achieving a 66.5\% improvement in the BELURT score. We will soon make the dataset and the source code publicly accessible.