 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Sensing Framework Design and Performance Optimization with Action Detection for ISCC
May 05, 2025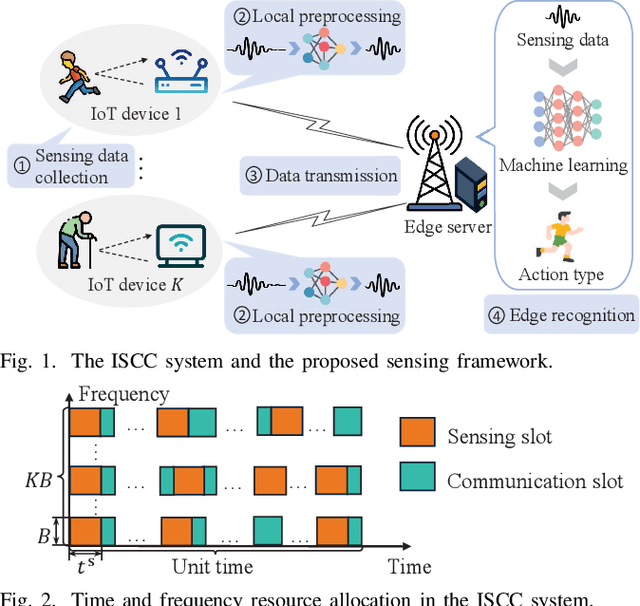
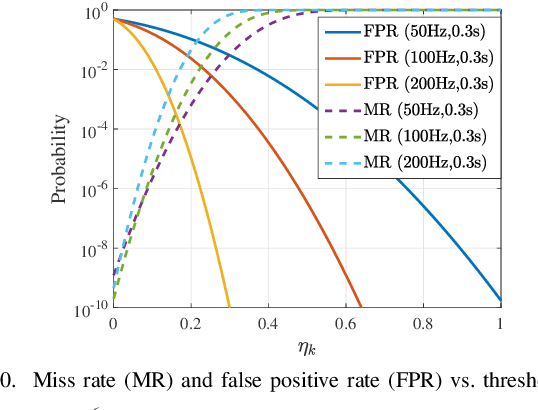
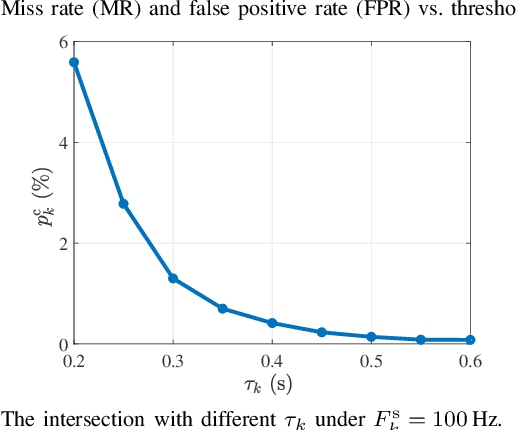
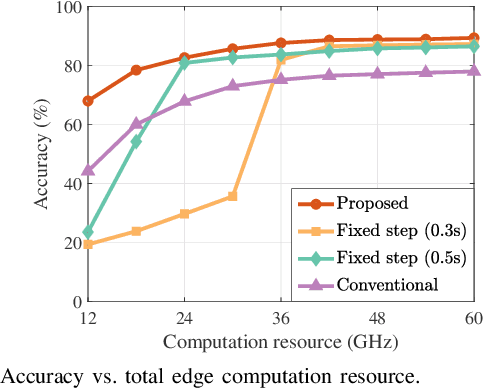
Integrated sensing, communication, and computation (ISCC) has been regarded as a prospective technology for the next-generation wireless network, supporting humancentric intelligent applications. However, the delay sensitivity of these computation-intensive applications, especially in a multidevice ISCC system with limited resources, highlights the urgent need for efficient sensing task execution frameworks. To address this, we propose a resource-efficient sensing framework in this paper. Different from existing solutions, it features a novel action detection module deployed at each device to detect the onset of an action. Only time windows filled with signals of interest are offloaded to the edge server and processed by the edge recognition module, thus reducing overhead. Furthermore, we quantitatively analyze the sensing performance of the proposed sensing framework and formulate a sensing accuracy maximization problem under power, delay, and resource limitations for the multi-device ISCC system. By decomposing it into two subproblems, we develop an alternating direction method of multipliers (ADMM)-based distributed algorithm. It alternatively solves a sensing accuracy maximization subproblem at each device and employs a closed-form computation resource allocation strategy at the edge server till convergence. Finally, a real-world test is conducted using commodity wireless devices to validate the sensing performance analysis. Extensive test results demonstrate that our proposal achieves higher sensing accuracy under the limited resource compared to two baselines.
Zero-Shot Audio-Visual Editing via Cross-Modal Delta Denoising
Mar 26, 2025
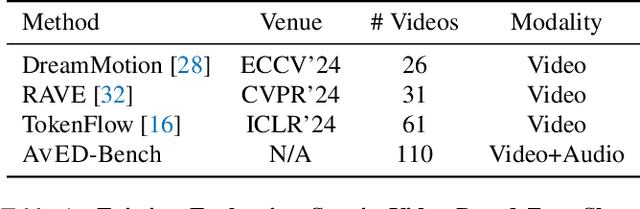
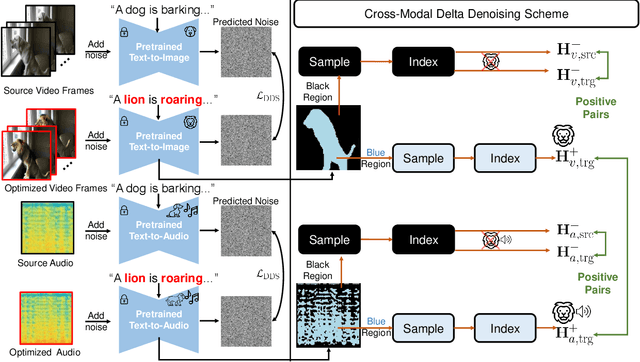
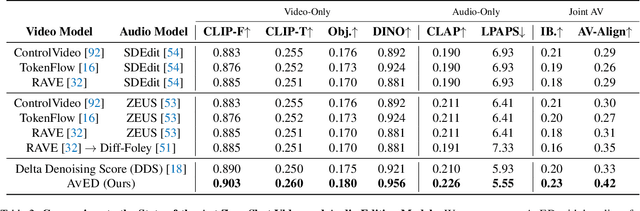
In this paper, we introduce zero-shot audio-video editing, a novel task that requires transforming original audio-visual content to align with a specified textual prompt without additional model training. To evaluate this task, we curate a benchmark dataset, AvED-Bench, designed explicitly for zero-shot audio-video editing. AvED-Bench includes 110 videos, each with a 10-second duration, spanning 11 categories from VGGSound. It offers diverse prompts and scenarios that require precise alignment between auditory and visual elements, enabling robust evaluation. We identify limitations in existing zero-shot audio and video editing methods, particularly in synchronization and coherence between modalities, which often result in inconsistent outcomes. To address these challenges, we propose AvED, a zero-shot cross-modal delta denoising framework that leverages audio-video interactions to achieve synchronized and coherent edits. AvED demonstrates superior results on both AvED-Bench and the recent OAVE dataset to validate its generalization capabilities. Results are available at https://genjib.github.io/project_page/AVED/index.html
GenXD: Generating Any 3D and 4D Scenes
Nov 05, 2024



Recent developments in 2D visual generation have been remarkably successful. However, 3D and 4D generation remain challenging in real-world applications due to the lack of large-scale 4D data and effective model design. In this paper, we propose to jointly investigate general 3D and 4D generation by leveraging camera and object movements commonly observed in daily life. Due to the lack of real-world 4D data in the community, we first propose a data curation pipeline to obtain camera poses and object motion strength from videos. Based on this pipeline, we introduce a large-scale real-world 4D scene dataset: CamVid-30K. By leveraging all the 3D and 4D data, we develop our framework, GenXD, which allows us to produce any 3D or 4D scene. We propose multiview-temporal modules, which disentangle camera and object movements, to seamlessly learn from both 3D and 4D data. Additionally, GenXD employs masked latent conditions to support a variety of conditioning views. GenXD can generate videos that follow the camera trajectory as well as consistent 3D views that can be lifted into 3D representations. We perform extensive evaluations across various real-world and synthetic datasets, demonstrating GenXD's effectiveness and versatility compared to previous methods in 3D and 4D generation.
LiVOS: Light Video Object Segmentation with Gated Linear Matching
Nov 05, 2024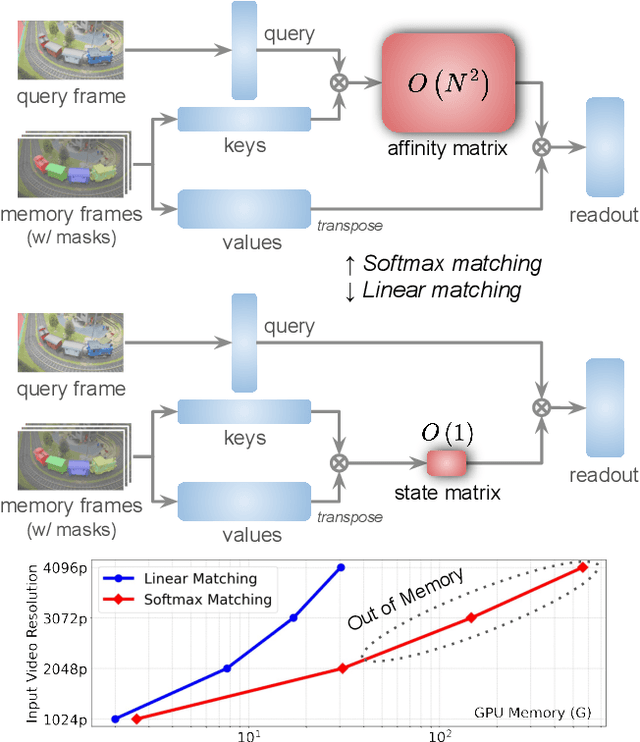
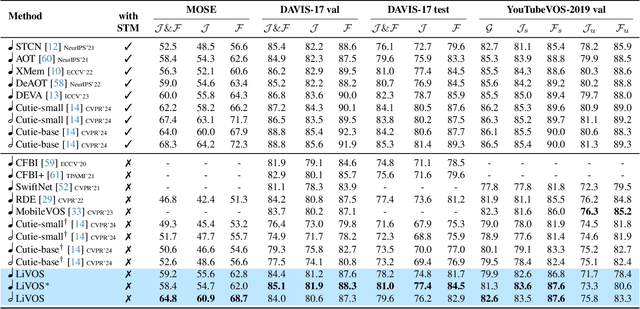
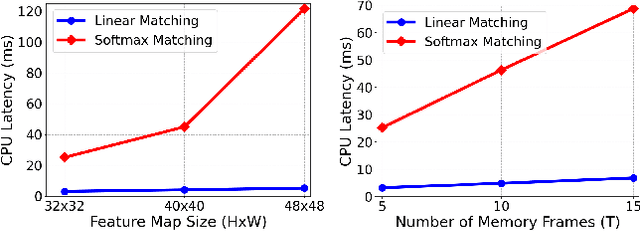
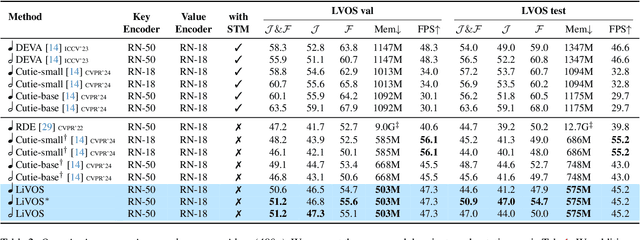
Semi-supervised video object segmentation (VOS) has been largely driven by space-time memory (STM) networks, which store past frame features in a spatiotemporal memory to segment the current frame via softmax attention. However, STM networks face memory limitations due to the quadratic complexity of softmax matching, restricting their applicability as video length and resolution increase. To address this, we propose LiVOS, a lightweight memory network that employs linear matching via linear attention, reformulating memory matching into a recurrent process that reduces the quadratic attention matrix to a constant-size, spatiotemporal-agnostic 2D state. To enhance selectivity, we introduce gated linear matching, where a data-dependent gate matrix is multiplied with the state matrix to control what information to retain or discard. Experiments on diverse benchmarks demonstrated the effectiveness of our method. It achieved 64.8 J&F on MOSE and 85.1 J&F on DAVIS, surpassing all non-STM methods and narrowing the gap with STM-based approaches. For longer and higher-resolution videos, it matched STM-based methods with 53% less GPU memory and supports 4096p inference on a 32G consumer-grade GPU--a previously cost-prohibitive capability--opening the door for long and high-resolution video foundation models.
SlowFast-VGen: Slow-Fast Learning for Action-Driven Long Video Generation
Oct 30, 2024



Human beings are endowed with a complementary learning system, which bridges the slow learning of general world dynamics with fast storage of episodic memory from a new experience. Previous video generation models, however, primarily focus on slow learning by pre-training on vast amounts of data, overlooking the fast learning phase crucial for episodic memory storage. This oversight leads to inconsistencies across temporally distant frames when generating longer videos, as these frames fall beyond the model's context window. To this end, we introduce SlowFast-VGen, a novel dual-speed learning system for action-driven long video generation. Our approach incorporates a masked conditional video diffusion model for the slow learning of world dynamics, alongside an inference-time fast learning strategy based on a temporal LoRA module. Specifically, the fast learning process updates its temporal LoRA parameters based on local inputs and outputs, thereby efficiently storing episodic memory in its parameters. We further propose a slow-fast learning loop algorithm that seamlessly integrates the inner fast learning loop into the outer slow learning loop, enabling the recall of prior multi-episode experiences for context-aware skill learning. To facilitate the slow learning of an approximate world model, we collect a large-scale dataset of 200k videos with language action annotations, covering a wide range of scenarios. Extensive experiments show that SlowFast-VGen outperforms baselines across various metrics for action-driven video generation, achieving an FVD score of 514 compared to 782, and maintaining consistency in longer videos, with an average of 0.37 scene cuts versus 0.89. The slow-fast learning loop algorithm significantly enhances performances on long-horizon planning tasks as well. Project Website: https://slowfast-vgen.github.io
EditRoom: LLM-parameterized Graph Diffusion for Composable 3D Room Layout Editing
Oct 03, 2024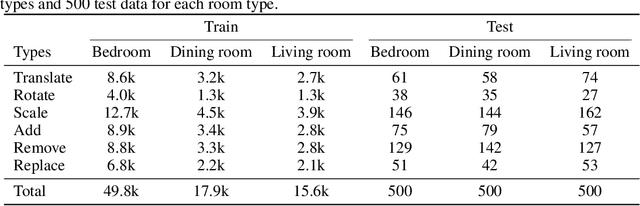
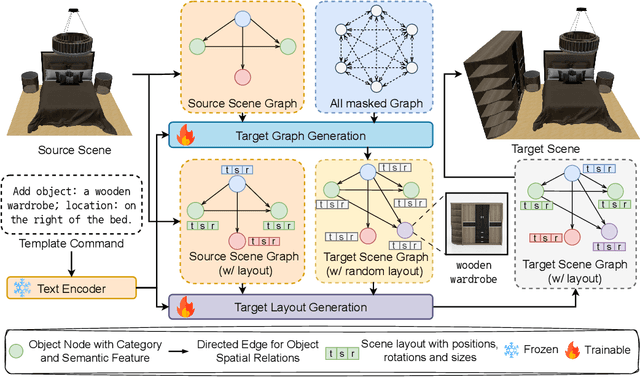

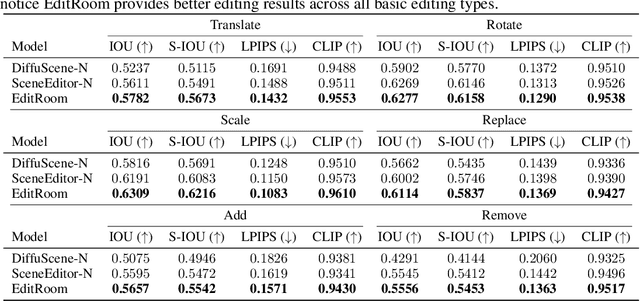
Given the steep learning curve of professional 3D software and the time-consuming process of managing large 3D assets, language-guided 3D scene editing has significant potential in fields such as virtual reality, augmented reality, and gaming. However, recent approaches to language-guided 3D scene editing either require manual interventions or focus only on appearance modifications without supporting comprehensive scene layout changes. In response, we propose Edit-Room, a unified framework capable of executing a variety of layout edits through natural language commands, without requiring manual intervention. Specifically, EditRoom leverages Large Language Models (LLMs) for command planning and generates target scenes using a diffusion-based method, enabling six types of edits: rotate, translate, scale, replace, add, and remove. To address the lack of data for language-guided 3D scene editing, we have developed an automatic pipeline to augment existing 3D scene synthesis datasets and introduced EditRoom-DB, a large-scale dataset with 83k editing pairs, for training and evaluation. Our experiments demonstrate that our approach consistently outperforms other baselines across all metrics, indicating higher accuracy and coherence in language-guided scene layout editing.
MM-Vet v2: A Challenging Benchmark to Evaluate Large Multimodal Models for Integrated Capabilities
Aug 01, 2024



MM-Vet, with open-ended vision-language questions targeting at evaluating integrated capabilities, has become one of the most popular benchmarks for large multimodal model evaluation. MM-Vet assesses six core vision-language (VL) capabilities: recognition, knowledge, spatial awareness, language generation, OCR, and math. However, its question format is restricted to single image-text pairs, lacking the interleaved image and text sequences prevalent in real-world scenarios. To address this limitation, we introduce MM-Vet v2, which includes a new VL capability called "image-text sequence understanding", evaluating models' ability to process VL sequences. Furthermore, we maintain the high quality of evaluation samples while further expanding the evaluation set size. Using MM-Vet v2 to benchmark large multimodal models, we found that Claude 3.5 Sonnet is the best model with a score of 71.8, slightly outperforming GPT-4o which scored 71.0. Among open-weight models, InternVL2-Llama3-76B leads with a score of 68.4.
IDOL: Unified Dual-Modal Latent Diffusion for Human-Centric Joint Video-Depth Generation
Jul 15, 2024

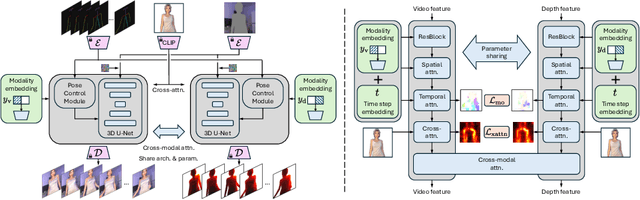

Significant advances have been made in human-centric video generation, yet the joint video-depth generation problem remains underexplored. Most existing monocular depth estimation methods may not generalize well to synthesized images or videos, and multi-view-based methods have difficulty controlling the human appearance and motion. In this work, we present IDOL (unIfied Dual-mOdal Latent diffusion) for high-quality human-centric joint video-depth generation. Our IDOL consists of two novel designs. First, to enable dual-modal generation and maximize the information exchange between video and depth generation, we propose a unified dual-modal U-Net, a parameter-sharing framework for joint video and depth denoising, wherein a modality label guides the denoising target, and cross-modal attention enables the mutual information flow. Second, to ensure a precise video-depth spatial alignment, we propose a motion consistency loss that enforces consistency between the video and depth feature motion fields, leading to harmonized outputs. Additionally, a cross-attention map consistency loss is applied to align the cross-attention map of the video denoising with that of the depth denoising, further facilitating spatial alignment. Extensive experiments on the TikTok and NTU120 datasets show our superior performance, significantly surpassing existing methods in terms of video FVD and depth accuracy.
MMWorld: Towards Multi-discipline Multi-faceted World Model Evaluation in Videos
Jun 12, 2024



Multimodal Language Language Models (MLLMs) demonstrate the emerging abilities of "world models" -- interpreting and reasoning about complex real-world dynamics. To assess these abilities, we posit videos are the ideal medium, as they encapsulate rich representations of real-world dynamics and causalities. To this end, we introduce MMWorld, a new benchmark for multi-discipline, multi-faceted multimodal video understanding. MMWorld distinguishes itself from previous video understanding benchmarks with two unique advantages: (1) multi-discipline, covering various disciplines that often require domain expertise for comprehensive understanding; (2) multi-faceted reasoning, including explanation, counterfactual thinking, future prediction, etc. MMWorld consists of a human-annotated dataset to evaluate MLLMs with questions about the whole videos and a synthetic dataset to analyze MLLMs within a single modality of perception. Together, MMWorld encompasses 1,910 videos across seven broad disciplines and 69 subdisciplines, complete with 6,627 question-answer pairs and associated captions. The evaluation includes 2 proprietary and 10 open-source MLLMs, which struggle on MMWorld (e.g., GPT-4V performs the best with only 52.3\% accuracy), showing large room for improvement. Further ablation studies reveal other interesting findings such as models' different skill sets from humans. We hope MMWorld can serve as an essential step towards world model evaluation in videos.