 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Evolving 3D Scene Generation from a Single Image
Dec 09, 2025Generating high-quality, textured 3D scenes from a single image remains a fundamental challenge in vision and graphics. Recent image-to-3D generators recover reasonable geometry from single views, but their object-centric training limits generalization to complex, large-scale scenes with faithful structure and texture. We present EvoScene, a self-evolving, training-free framework that progressively reconstructs complete 3D scenes from single images. The key idea is combining the complementary strengths of existing models: geometric reasoning from 3D generation models and visual knowledge from video generation models. Through three iterative stages--Spatial Prior Initialization, Visual-guided 3D Scene Mesh Generation, and Spatial-guided Novel View Generation--EvoScene alternates between 2D and 3D domains, gradually improving both structure and appearance. Experiments on diverse scenes demonstrate that EvoScene achieves superior geometric stability, view-consistent textures, and unseen-region completion compared to strong baselines, producing ready-to-use 3D meshes for practical applications.
MorphoSim: An Interactive, Controllable, and Editable Language-guided 4D World Simulator
Oct 05, 2025



World models that support controllable and editable spatiotemporal environments are valuable for robotics, enabling scalable training data, repro ducible evaluation, and flexible task design. While recent text-to-video models generate realistic dynam ics, they are constrained to 2D views and offer limited interaction. We introduce MorphoSim, a language guided framework that generates 4D scenes with multi-view consistency and object-level controls. From natural language instructions, MorphoSim produces dynamic environments where objects can be directed, recolored, or removed, and scenes can be observed from arbitrary viewpoints. The framework integrates trajectory-guided generation with feature field dis tillation, allowing edits to be applied interactively without full re-generation. Experiments show that Mor phoSim maintains high scene fidelity while enabling controllability and editability. The code is available at https://github.com/eric-ai-lab/Morph4D.
GRIT: Teaching MLLMs to Think with Images
May 21, 2025Recent studies have demonstrated the efficacy of using Reinforcement Learning (RL) in building reasoning models that articulate chains of thoughts prior to producing final answers. However, despite ongoing advances that aim at enabling reasoning for vision-language tasks, existing open-source visual reasoning models typically generate reasoning content with pure natural language, lacking explicit integration of visual information. This limits their ability to produce clearly articulated and visually grounded reasoning chains. To this end, we propose Grounded Reasoning with Images and Texts (GRIT), a novel method for training MLLMs to think with images. GRIT introduces a grounded reasoning paradigm, in which models generate reasoning chains that interleave natural language and explicit bounding box coordinates. These coordinates point to regions of the input image that the model consults during its reasoning process. Additionally, GRIT is equipped with a reinforcement learning approach, GRPO-GR, built upon the GRPO algorithm. GRPO-GR employs robust rewards focused on the final answer accuracy and format of the grounded reasoning output, which eliminates the need for data with reasoning chain annotations or explicit bounding box labels. As a result, GRIT achieves exceptional data efficiency, requiring as few as 20 image-question-answer triplets from existing datasets. Comprehensive evaluations demonstrate that GRIT effectively trains MLLMs to produce coherent and visually grounded reasoning chains, showing a successful unification of reasoning and grounding abilities.
Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space
May 21, 2025Human cognition typically involves thinking through abstract, fluid concepts rather than strictly using discrete linguistic tokens. Current reasoning models, however, are constrained to reasoning within the boundaries of human language, processing discrete token embeddings that represent fixed points in the semantic space. This discrete constraint restricts the expressive power and upper potential of such reasoning models, often causing incomplete exploration of reasoning paths, as standard Chain-of-Thought (CoT) methods rely on sampling one token per step. In this work, we introduce Soft Thinking, a training-free method that emulates human-like "soft" reasoning by generating soft, abstract concept tokens in a continuous concept space. These concept tokens are created by the probability-weighted mixture of token embeddings, which form the continuous concept space, enabling smooth transitions and richer representations that transcend traditional discrete boundaries. In essence, each generated concept token encapsulates multiple meanings from related discrete tokens, implicitly exploring various reasoning paths to converge effectively toward the correct answer. Empirical evaluations on diverse mathematical and coding benchmarks consistently demonstrate the effectiveness and efficiency of Soft Thinking, improving pass@1 accuracy by up to 2.48 points while simultaneously reducing token usage by up to 22.4% compared to standard CoT. Qualitative analysis further reveals that Soft Thinking outputs remain highly interpretable and readable, highlighting the potential of Soft Thinking to break the inherent bottleneck of discrete language-based reasoning. Code is available at https://github.com/eric-ai-lab/Soft-Thinking.
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
Apr 29, 2025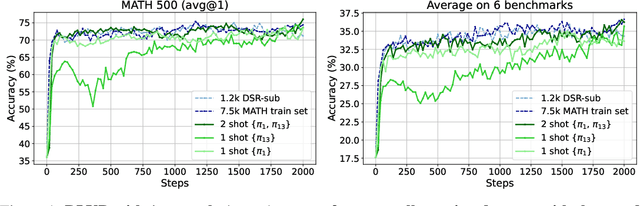
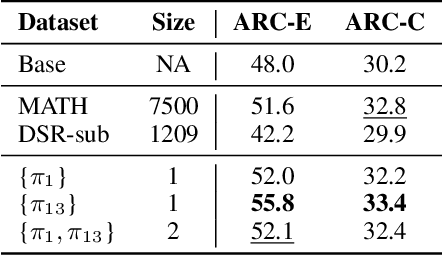
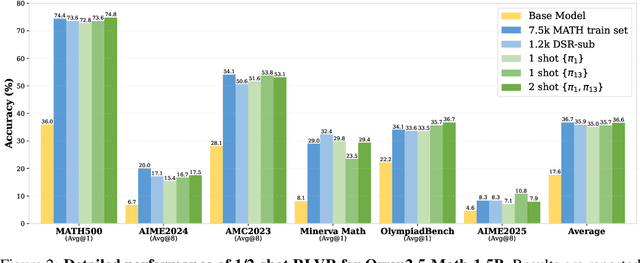

We show that reinforcement learning with verifiable reward using one training example (1-shot RLVR) is effective in incentivizing the math reasoning capabilities of large language models (LLMs). Applying RLVR to the base model Qwen2.5-Math-1.5B, we identify a single example that elevates model performance on MATH500 from 36.0% to 73.6%, and improves the average performance across six common mathematical reasoning benchmarks from 17.6% to 35.7%. This result matches the performance obtained using the 1.2k DeepScaleR subset (MATH500: 73.6%, average: 35.9%), which includes the aforementioned example. Similar substantial improvements are observed across various models (Qwen2.5-Math-7B, Llama3.2-3B-Instruct, DeepSeek-R1-Distill-Qwen-1.5B), RL algorithms (GRPO and PPO), and different math examples (many of which yield approximately 30% or greater improvement on MATH500 when employed as a single training example). In addition, we identify some interesting phenomena during 1-shot RLVR, including cross-domain generalization, increased frequency of self-reflection, and sustained test performance improvement even after the training accuracy has saturated, a phenomenon we term post-saturation generalization. Moreover, we verify that the effectiveness of 1-shot RLVR primarily arises from the policy gradient loss, distinguishing it from the "grokking" phenomenon. We also show the critical role of promoting exploration (e.g., by adding entropy loss with an appropriate coefficient) in 1-shot RLVR training. As a bonus, we observe that applying entropy loss alone, without any outcome reward, significantly enhances Qwen2.5-Math-1.5B's performance on MATH500 by 27.4%. These findings can inspire future work on RLVR data efficiency and encourage a re-examination of both recent progress and the underlying mechanisms in RLVR. Our code, model, and data are open source at https://github.com/ypwang61/One-Shot-RLVR
Is Your World Simulator a Good Story Presenter? A Consecutive Events-Based Benchmark for Future Long Video Generation
Dec 17, 2024
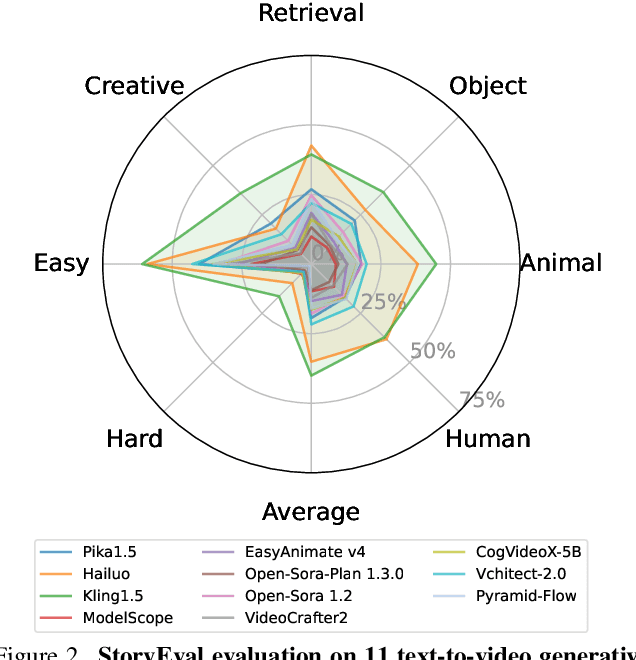


The current state-of-the-art video generative models can produce commercial-grade videos with highly realistic details. However, they still struggle to coherently present multiple sequential events in the stories specified by the prompts, which is foreseeable an essential capability for future long video generation scenarios. For example, top T2V generative models still fail to generate a video of the short simple story 'how to put an elephant into a refrigerator.' While existing detail-oriented benchmarks primarily focus on fine-grained metrics like aesthetic quality and spatial-temporal consistency, they fall short of evaluating models' abilities to handle event-level story presentation. To address this gap, we introduce StoryEval, a story-oriented benchmark specifically designed to assess text-to-video (T2V) models' story-completion capabilities. StoryEval features 423 prompts spanning 7 classes, each representing short stories composed of 2-4 consecutive events. We employ advanced vision-language models, such as GPT-4V and LLaVA-OV-Chat-72B, to verify the completion of each event in the generated videos, applying a unanimous voting method to enhance reliability. Our methods ensure high alignment with human evaluations, and the evaluation of 11 models reveals its challenge, with none exceeding an average story-completion rate of 50%. StoryEval provides a new benchmark for advancing T2V models and highlights the challenges and opportunities in developing next-generation solutions for coherent story-driven video generation.
Mojito: Motion Trajectory and Intensity Control for Video Generation
Dec 12, 2024



Recent advancements in diffusion models have shown great promise in producing high-quality video content. However, efficiently training diffusion models capable of integrating directional guidance and controllable motion intensity remains a challenging and under-explored area. This paper introduces Mojito, a diffusion model that incorporates both \textbf{Mo}tion tra\textbf{j}ectory and \textbf{i}ntensi\textbf{t}y contr\textbf{o}l for text to video generation. Specifically, Mojito features a Directional Motion Control module that leverages cross-attention to efficiently direct the generated object's motion without additional training, alongside a Motion Intensity Modulator that uses optical flow maps generated from videos to guide varying levels of motion intensity. Extensive experiments demonstrate Mojito's effectiveness in achieving precise trajectory and intensity control with high computational efficiency, generating motion patterns that closely match specified directions and intensities, providing realistic dynamics that align well with natural motion in real-world scenarios.
EditRoom: LLM-parameterized Graph Diffusion for Composable 3D Room Layout Editing
Oct 03, 2024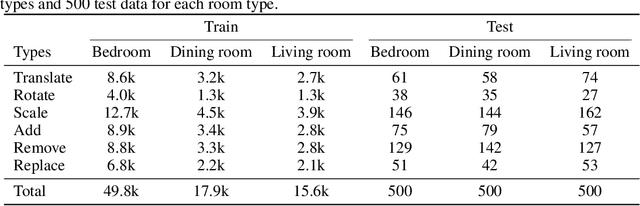
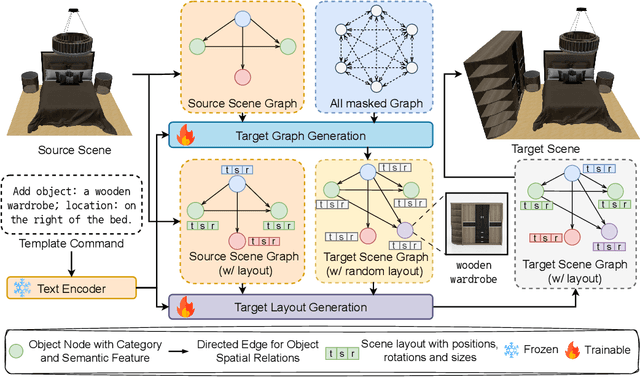

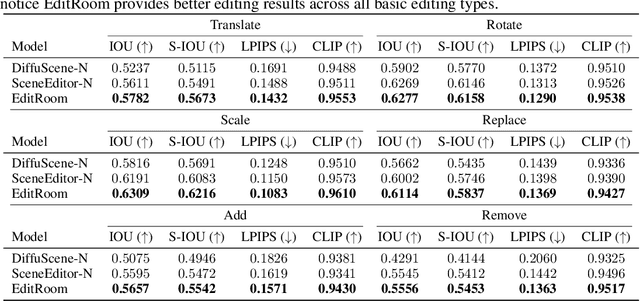
Given the steep learning curve of professional 3D software and the time-consuming process of managing large 3D assets, language-guided 3D scene editing has significant potential in fields such as virtual reality, augmented reality, and gaming. However, recent approaches to language-guided 3D scene editing either require manual interventions or focus only on appearance modifications without supporting comprehensive scene layout changes. In response, we propose Edit-Room, a unified framework capable of executing a variety of layout edits through natural language commands, without requiring manual intervention. Specifically, EditRoom leverages Large Language Models (LLMs) for command planning and generates target scenes using a diffusion-based method, enabling six types of edits: rotate, translate, scale, replace, add, and remove. To address the lack of data for language-guided 3D scene editing, we have developed an automatic pipeline to augment existing 3D scene synthesis datasets and introduced EditRoom-DB, a large-scale dataset with 83k editing pairs, for training and evaluation. Our experiments demonstrate that our approach consistently outperforms other baselines across all metrics, indicating higher accuracy and coherence in language-guided scene layout editing.
MMWorld: Towards Multi-discipline Multi-faceted World Model Evaluation in Videos
Jun 12, 2024



Multimodal Language Language Models (MLLMs) demonstrate the emerging abilities of "world models" -- interpreting and reasoning about complex real-world dynamics. To assess these abilities, we posit videos are the ideal medium, as they encapsulate rich representations of real-world dynamics and causalities. To this end, we introduce MMWorld, a new benchmark for multi-discipline, multi-faceted multimodal video understanding. MMWorld distinguishes itself from previous video understanding benchmarks with two unique advantages: (1) multi-discipline, covering various disciplines that often require domain expertise for comprehensive understanding; (2) multi-faceted reasoning, including explanation, counterfactual thinking, future prediction, etc. MMWorld consists of a human-annotated dataset to evaluate MLLMs with questions about the whole videos and a synthetic dataset to analyze MLLMs within a single modality of perception. Together, MMWorld encompasses 1,910 videos across seven broad disciplines and 69 subdisciplines, complete with 6,627 question-answer pairs and associated captions. The evaluation includes 2 proprietary and 10 open-source MLLMs, which struggle on MMWorld (e.g., GPT-4V performs the best with only 52.3\% accuracy), showing large room for improvement. Further ablation studies reveal other interesting findings such as models' different skill sets from humans. We hope MMWorld can serve as an essential step towards world model evaluation in videos.
Worse than Random? An Embarrassingly Simple Probing Evaluation of Large Multimodal Models in Medical VQA
May 30, 2024



Large Multimodal Models (LMMs) have shown remarkable progress in the field of medical Visual Question Answering (Med-VQA), achieving high accuracy on existing benchmarks. However, their reliability under robust evaluation is questionable. This study reveals that state-of-the-art models, when subjected to simple probing evaluation, perform worse than random guessing on medical diagnosis questions. To address this critical evaluation problem, we introduce the Probing Evaluation for Medical Diagnosis (ProbMed) dataset to rigorously assess LMM performance in medical imaging through probing evaluation and procedural diagnosis. Particularly, probing evaluation features pairing original questions with negation questions with hallucinated attributes, while procedural diagnosis requires reasoning across various diagnostic dimensions for each image, including modality recognition, organ identification, clinical findings, abnormalities, and positional grounding. Our evaluation reveals that top-performing models like GPT-4V and Gemini Pro perform worse than random guessing on specialized diagnostic questions, indicating significant limitations in handling fine-grained medical inquiries. Besides, models like LLaVA-Med struggle even with more general questions, and results from CheXagent demonstrate the transferability of expertise across different modalities of the same organ, showing that specialized domain knowledge is still crucial for improving performance. This study underscores the urgent need for more robust evaluation to ensure the reliability of LMMs in critical fields like medical diagnosis, and current LMMs are still far from applicable to those fields.