 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation
Paper and Code
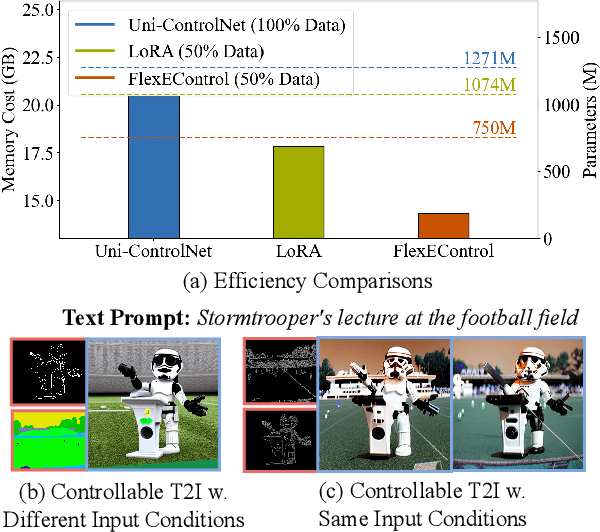

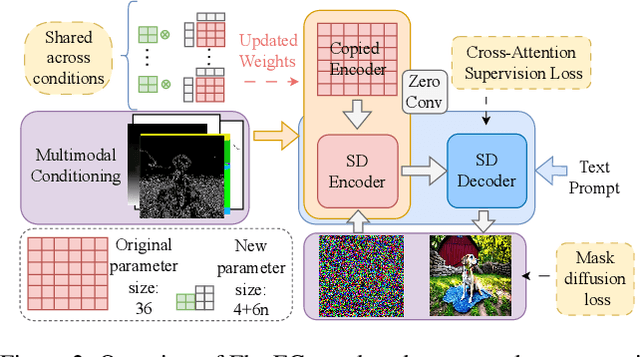
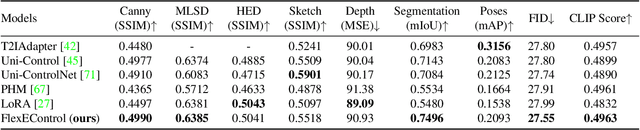
Controllable text-to-image (T2I) diffusion models generate images conditioned on both text prompts and semantic inputs of other modalities like edge maps. Nevertheless, current controllable T2I methods commonly face challenges related to efficiency and faithfulness, especially when conditioning on multiple inputs from either the same or diverse modalities. In this paper, we propose a novel Flexible and Efficient method, FlexEControl, for controllable T2I generation. At the core of FlexEControl is a unique weight decomposition strategy, which allows for streamlined integration of various input types. This approach not only enhances the faithfulness of the generated image to the control, but also significantly reduces the computational overhead typically associated with multimodal conditioning. Our approach achieves a reduction of 41% in trainable parameters and 30% in memory usage compared with Uni-ControlNet. Moreover, it doubles data efficiency and can flexibly generate images under the guidance of multiple input conditions of various modalities.