 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHECTOR: Hybrid Editable Compositional Object References for Video Generation
Mar 09, 2026Real-world videos naturally portray complex interactions among distinct physical objects, effectively forming dynamic compositions of visual elements. However, most current video generation models synthesize scenes holistically and therefore lack mechanisms for explicit compositional manipulation. To address this limitation, we propose HECTOR, a generative pipeline that enables fine-grained compositional control. In contrast to prior methods,HECTOR supports hybrid reference conditioning, allowing generation to be simultaneously guided by static images and/or dynamic videos. Moreover, users can explicitly specify the trajectory of each referenced element, precisely controlling its location, scale, and speed (see Figure1). This design allows the model to synthesize coherent videos that satisfy complex spatiotemporal constraints while preserving high-fidelity adherence to references. Extensive experiments demonstrate that HECTOR achieves superior visual quality, stronger reference preservation, and improved motion controllability compared with existing approaches.
StoryMem: Multi-shot Long Video Storytelling with Memory
Dec 22, 2025
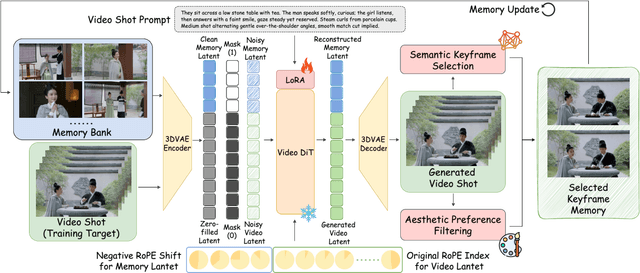

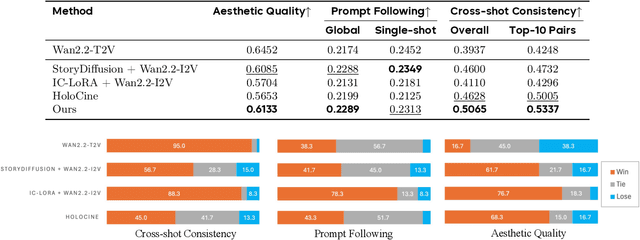
Visual storytelling requires generating multi-shot videos with cinematic quality and long-range consistency. Inspired by human memory, we propose StoryMem, a paradigm that reformulates long-form video storytelling as iterative shot synthesis conditioned on explicit visual memory, transforming pre-trained single-shot video diffusion models into multi-shot storytellers. This is achieved by a novel Memory-to-Video (M2V) design, which maintains a compact and dynamically updated memory bank of keyframes from historical generated shots. The stored memory is then injected into single-shot video diffusion models via latent concatenation and negative RoPE shifts with only LoRA fine-tuning. A semantic keyframe selection strategy, together with aesthetic preference filtering, further ensures informative and stable memory throughout generation. Moreover, the proposed framework naturally accommodates smooth shot transitions and customized story generation applications. To facilitate evaluation, we introduce ST-Bench, a diverse benchmark for multi-shot video storytelling. Extensive experiments demonstrate that StoryMem achieves superior cross-shot consistency over previous methods while preserving high aesthetic quality and prompt adherence, marking a significant step toward coherent minute-long video storytelling.
MAGREF: Masked Guidance for Any-Reference Video Generation
May 29, 2025Video generation has made substantial strides with the emergence of deep generative models, especially diffusion-based approaches. However, video generation based on multiple reference subjects still faces significant challenges in maintaining multi-subject consistency and ensuring high generation quality. In this paper, we propose MAGREF, a unified framework for any-reference video generation that introduces masked guidance to enable coherent multi-subject video synthesis conditioned on diverse reference images and a textual prompt. Specifically, we propose (1) a region-aware dynamic masking mechanism that enables a single model to flexibly handle various subject inference, including humans, objects, and backgrounds, without architectural changes, and (2) a pixel-wise channel concatenation mechanism that operates on the channel dimension to better preserve appearance features. Our model delivers state-of-the-art video generation quality, generalizing from single-subject training to complex multi-subject scenarios with coherent synthesis and precise control over individual subjects, outperforming existing open-source and commercial baselines. To facilitate evaluation, we also introduce a comprehensive multi-subject video benchmark. Extensive experiments demonstrate the effectiveness of our approach, paving the way for scalable, controllable, and high-fidelity multi-subject video synthesis. Code and model can be found at: https://github.com/MAGREF-Video/MAGREF
ATI: Any Trajectory Instruction for Controllable Video Generation
May 28, 2025We propose a unified framework for motion control in video generation that seamlessly integrates camera movement, object-level translation, and fine-grained local motion using trajectory-based inputs. In contrast to prior methods that address these motion types through separate modules or task-specific designs, our approach offers a cohesive solution by projecting user-defined trajectories into the latent space of pre-trained image-to-video generation models via a lightweight motion injector. Users can specify keypoints and their motion paths to control localized deformations, entire object motion, virtual camera dynamics, or combinations of these. The injected trajectory signals guide the generative process to produce temporally consistent and semantically aligned motion sequences. Our framework demonstrates superior performance across multiple video motion control tasks, including stylized motion effects (e.g., motion brushes), dynamic viewpoint changes, and precise local motion manipulation. Experiments show that our method provides significantly better controllability and visual quality compared to prior approaches and commercial solutions, while remaining broadly compatible with various state-of-the-art video generation backbones. Project page: https://anytraj.github.io/.
CINEMA: Coherent Multi-Subject Video Generation via MLLM-Based Guidance
Mar 13, 2025Video generation has witnessed remarkable progress with the advent of deep generative models, particularly diffusion models. While existing methods excel in generating high-quality videos from text prompts or single images, personalized multi-subject video generation remains a largely unexplored challenge. This task involves synthesizing videos that incorporate multiple distinct subjects, each defined by separate reference images, while ensuring temporal and spatial consistency. Current approaches primarily rely on mapping subject images to keywords in text prompts, which introduces ambiguity and limits their ability to model subject relationships effectively. In this paper, we propose CINEMA, a novel framework for coherent multi-subject video generation by leveraging Multimodal Large Language Model (MLLM). Our approach eliminates the need for explicit correspondences between subject images and text entities, mitigating ambiguity and reducing annotation effort. By leveraging MLLM to interpret subject relationships, our method facilitates scalability, enabling the use of large and diverse datasets for training. Furthermore, our framework can be conditioned on varying numbers of subjects, offering greater flexibility in personalized content creation. Through extensive evaluations, we demonstrate that our approach significantly improves subject consistency, and overall video coherence, paving the way for advanced applications in storytelling, interactive media, and personalized video generation.
FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation
May 08, 2024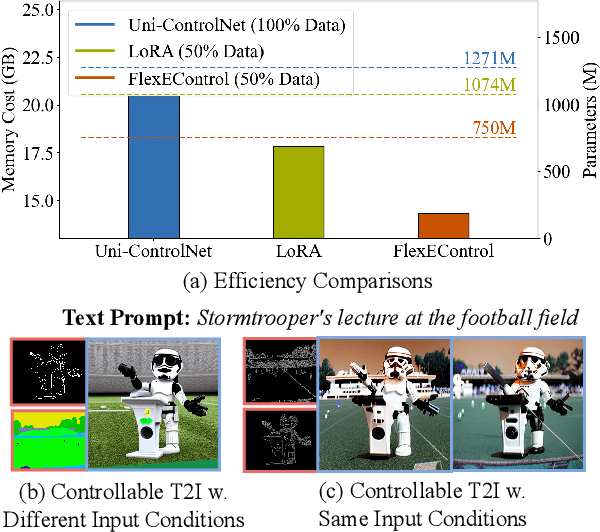

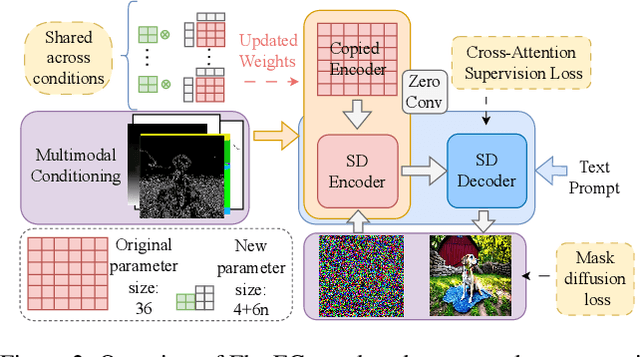
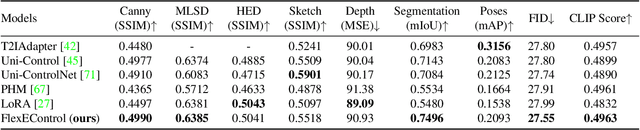
Controllable text-to-image (T2I) diffusion models generate images conditioned on both text prompts and semantic inputs of other modalities like edge maps. Nevertheless, current controllable T2I methods commonly face challenges related to efficiency and faithfulness, especially when conditioning on multiple inputs from either the same or diverse modalities. In this paper, we propose a novel Flexible and Efficient method, FlexEControl, for controllable T2I generation. At the core of FlexEControl is a unique weight decomposition strategy, which allows for streamlined integration of various input types. This approach not only enhances the faithfulness of the generated image to the control, but also significantly reduces the computational overhead typically associated with multimodal conditioning. Our approach achieves a reduction of 41% in trainable parameters and 30% in memory usage compared with Uni-ControlNet. Moreover, it doubles data efficiency and can flexibly generate images under the guidance of multiple input conditions of various modalities.
E-ViLM: Efficient Video-Language Model via Masked Video Modeling with Semantic Vector-Quantized Tokenizer
Nov 28, 2023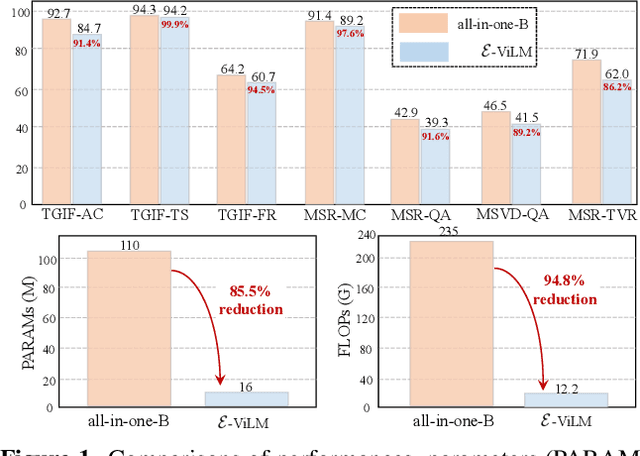
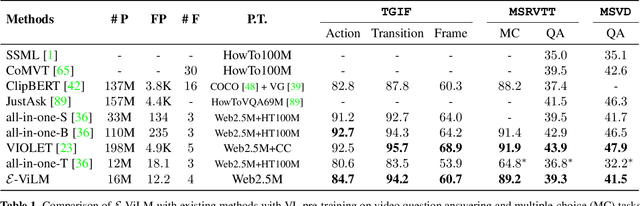
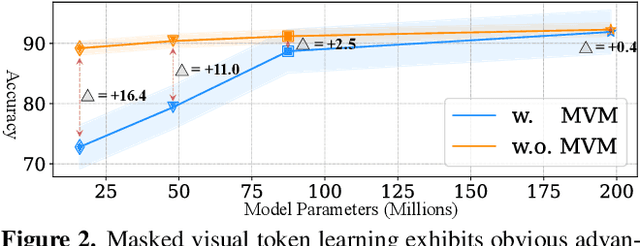
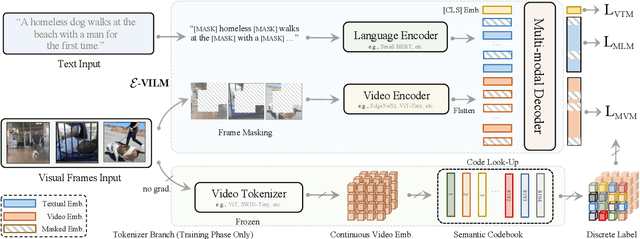
To build scalable models for challenging real-world tasks, it is important to learn from diverse, multi-modal data in various forms (e.g., videos, text, and images). Among the existing works, a plethora of them have focused on leveraging large but cumbersome cross-modal architectures. Regardless of their effectiveness, larger architectures unavoidably prevent the models from being extended to real-world applications, so building a lightweight VL architecture and an efficient learning schema is of great practical value. In this paper, we propose an Efficient Video-Language Model (dubbed as E-ViLM) and a masked video modeling (MVM) schema, assisted with a semantic vector-quantized tokenizer. In particular, our E-ViLM learns to reconstruct the semantic labels of masked video regions, produced by the pre-trained vector-quantized tokenizer, which discretizes the continuous visual signals into labels. We show that with our simple MVM task and regular VL pre-training modelings, our E-ViLM, despite its compactness, is able to learn expressive representations from Video-Language corpus and generalize well to extensive Video-Language tasks including video question answering, text-to-video retrieval, etc. In particular, our E-ViLM obtains obvious efficiency improvements by reaching competing performances with faster inference speed, i.e., our model reaches $39.3$% Top-$1$ accuracy on the MSRVTT benchmark, retaining $91.4$% of the accuracy of state-of-the-art larger VL architecture with only $15%$ parameters and $94.8%$ fewer GFLOPs. We also provide extensive ablative studies that validate the effectiveness of our proposed learning schema for E-ViLM.
Text-to-image Editing by Image Information Removal
May 27, 2023Diffusion models have demonstrated impressive performance in text-guided image generation. To leverage the knowledge of text-guided image generation models in image editing, current approaches either fine-tune the pretrained models using the input image (e.g., Imagic) or incorporate structure information as additional constraints into the pretrained models (e.g., ControlNet). However, fine-tuning large-scale diffusion models on a single image can lead to severe overfitting issues and lengthy inference time. The information leakage from pretrained models makes it challenging to preserve the text-irrelevant content of the input image while generating new features guided by language descriptions. On the other hand, methods that incorporate structural guidance (e.g., edge maps, semantic maps, keypoints) as additional constraints face limitations in preserving other attributes of the original image, such as colors or textures. A straightforward way to incorporate the original image is to directly use it as an additional control. However, since image editing methods are typically trained on the image reconstruction task, the incorporation can lead to the identical mapping issue, where the model learns to output an image identical to the input, resulting in limited editing capabilities. To address these challenges, we propose a text-to-image editing model with Image Information Removal module (IIR) to selectively erase color-related and texture-related information from the original image, allowing us to better preserve the text-irrelevant content and avoid the identical mapping issue. We evaluate our model on three benchmark datasets: CUB, Outdoor Scenes, and COCO. Our approach achieves the best editability-fidelity trade-off, and our edited images are approximately 35% more preferred by annotators than the prior-arts on COCO.