 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocal Guidance: Unlocking Controllability from Semantic-Weak Layers in Video Diffusion Models
Jan 12, 2026The task of Image-to-Video (I2V) generation aims to synthesize a video from a reference image and a text prompt. This requires diffusion models to reconcile high-frequency visual constraints and low-frequency textual guidance during the denoising process. However, while existing I2V models prioritize visual consistency, how to effectively couple this dual guidance to ensure strong adherence to the text prompt remains underexplored. In this work, we observe that in Diffusion Transformer (DiT)-based I2V models, certain intermediate layers exhibit weak semantic responses (termed Semantic-Weak Layers), as indicated by a measurable drop in text-visual similarity. We attribute this to a phenomenon called Condition Isolation, where attention to visual features becomes partially detached from text guidance and overly relies on learned visual priors. To address this, we propose Focal Guidance (FG), which enhances the controllability from Semantic-Weak Layers. FG comprises two mechanisms: (1) Fine-grained Semantic Guidance (FSG) leverages CLIP to identify key regions in the reference frame and uses them as anchors to guide Semantic-Weak Layers. (2) Attention Cache transfers attention maps from semantically responsive layers to Semantic-Weak Layers, injecting explicit semantic signals and alleviating their over-reliance on the model's learned visual priors, thereby enhancing adherence to textual instructions. To further validate our approach and address the lack of evaluation in this direction, we introduce a benchmark for assessing instruction following in I2V models. On this benchmark, Focal Guidance proves its effectiveness and generalizability, raising the total score on Wan2.1-I2V to 0.7250 (+3.97\%) and boosting the MMDiT-based HunyuanVideo-I2V to 0.5571 (+7.44\%).
MAGREF: Masked Guidance for Any-Reference Video Generation
May 29, 2025Video generation has made substantial strides with the emergence of deep generative models, especially diffusion-based approaches. However, video generation based on multiple reference subjects still faces significant challenges in maintaining multi-subject consistency and ensuring high generation quality. In this paper, we propose MAGREF, a unified framework for any-reference video generation that introduces masked guidance to enable coherent multi-subject video synthesis conditioned on diverse reference images and a textual prompt. Specifically, we propose (1) a region-aware dynamic masking mechanism that enables a single model to flexibly handle various subject inference, including humans, objects, and backgrounds, without architectural changes, and (2) a pixel-wise channel concatenation mechanism that operates on the channel dimension to better preserve appearance features. Our model delivers state-of-the-art video generation quality, generalizing from single-subject training to complex multi-subject scenarios with coherent synthesis and precise control over individual subjects, outperforming existing open-source and commercial baselines. To facilitate evaluation, we also introduce a comprehensive multi-subject video benchmark. Extensive experiments demonstrate the effectiveness of our approach, paving the way for scalable, controllable, and high-fidelity multi-subject video synthesis. Code and model can be found at: https://github.com/MAGREF-Video/MAGREF
Towards Precise Scaling Laws for Video Diffusion Transformers
Nov 25, 2024



Achieving optimal performance of video diffusion transformers within given data and compute budget is crucial due to their high training costs. This necessitates precisely determining the optimal model size and training hyperparameters before large-scale training. While scaling laws are employed in language models to predict performance, their existence and accurate derivation in visual generation models remain underexplored. In this paper, we systematically analyze scaling laws for video diffusion transformers and confirm their presence. Moreover, we discover that, unlike language models, video diffusion models are more sensitive to learning rate and batch size, two hyperparameters often not precisely modeled. To address this, we propose a new scaling law that predicts optimal hyperparameters for any model size and compute budget. Under these optimal settings, we achieve comparable performance and reduce inference costs by 40.1% compared to conventional scaling methods, within a compute budget of 1e10 TFlops. Furthermore, we establish a more generalized and precise relationship among validation loss, any model size, and compute budget. This enables performance prediction for non-optimal model sizes, which may also be appealed under practical inference cost constraints, achieving a better trade-off.
Beyond Sight: Towards Cognitive Alignment in LVLM via Enriched Visual Knowledge
Nov 25, 2024
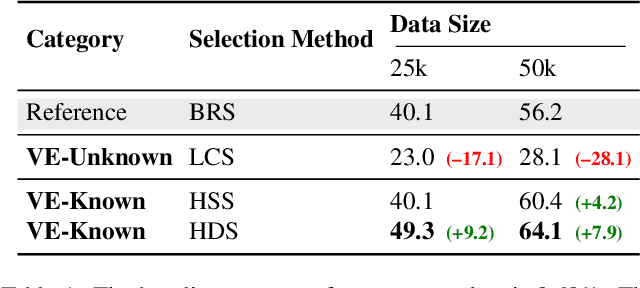
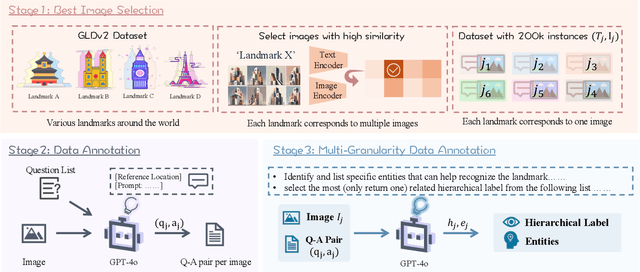

Does seeing always mean knowing? Large Vision-Language Models (LVLMs) integrate separately pre-trained vision and language components, often using CLIP-ViT as vision backbone. However, these models frequently encounter a core issue of "cognitive misalignment" between the vision encoder (VE) and the large language model (LLM). Specifically, the VE's representation of visual information may not fully align with LLM's cognitive framework, leading to a mismatch where visual features exceed the language model's interpretive range. To address this, we investigate how variations in VE representations influence LVLM comprehension, especially when the LLM faces VE-Unknown data-images whose ambiguous visual representations challenge the VE's interpretive precision. Accordingly, we construct a multi-granularity landmark dataset and systematically examine the impact of VE-Known and VE-Unknown data on interpretive abilities. Our results show that VE-Unknown data limits LVLM's capacity for accurate understanding, while VE-Known data, rich in distinctive features, helps reduce cognitive misalignment. Building on these insights, we propose Entity-Enhanced Cognitive Alignment (EECA), a method that employs multi-granularity supervision to generate visually enriched, well-aligned tokens that not only integrate within the LLM's embedding space but also align with the LLM's cognitive framework. This alignment markedly enhances LVLM performance in landmark recognition. Our findings underscore the challenges posed by VE-Unknown data and highlight the essential role of cognitive alignment in advancing multimodal systems.
SEA: Supervised Embedding Alignment for Token-Level Visual-Textual Integration in MLLMs
Aug 21, 2024Multimodal Large Language Models (MLLMs) have recently demonstrated remarkable perceptual and reasoning abilities, typically comprising a Vision Encoder, an Adapter, and a Large Language Model (LLM). The adapter serves as the critical bridge between the visual and language components. However, training adapters with image-level supervision often results in significant misalignment, undermining the LLMs' capabilities and limiting the potential of Multimodal LLMs. To address this, we introduce Supervised Embedding Alignment (SEA), a token-level alignment method that leverages vision-language pre-trained models, such as CLIP, to align visual tokens with the LLM's embedding space through contrastive learning. This approach ensures a more coherent integration of visual and language representations, enhancing the performance and interpretability of multimodal LLMs while preserving their inherent capabilities. Extensive experiments show that SEA effectively improves MLLMs, particularly for smaller models, without adding extra data or inference computation. SEA also lays the groundwork for developing more general and adaptable solutions to enhance multimodal systems.