 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaichuan-Audio: A Unified Framework for End-to-End Speech Interaction
Feb 24, 2025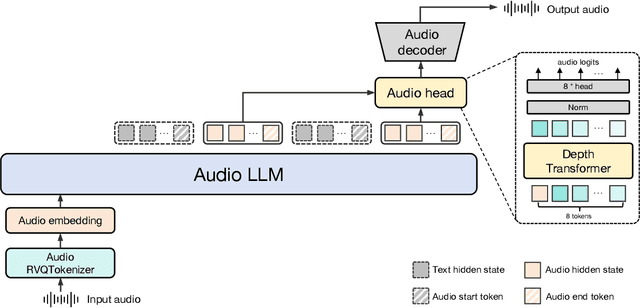
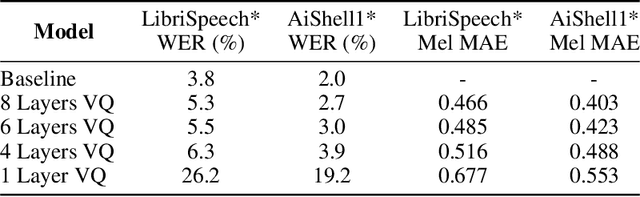
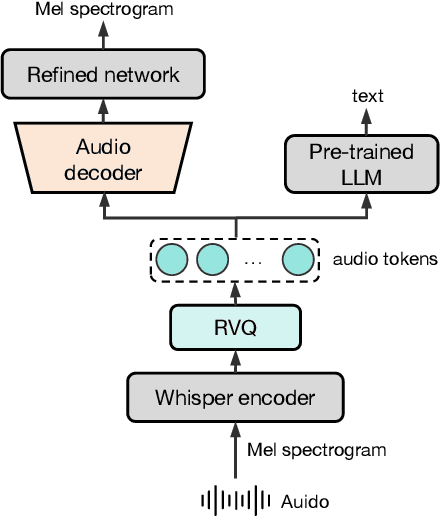
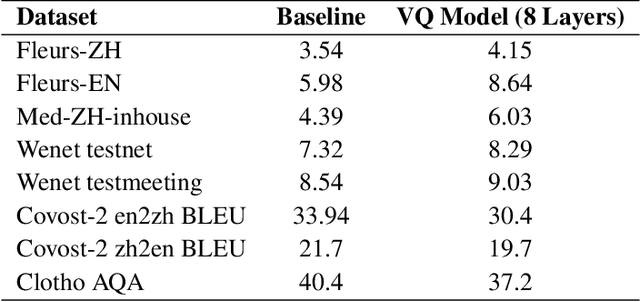
We introduce Baichuan-Audio, an end-to-end audio large language model that seamlessly integrates audio understanding and generation. It features a text-guided aligned speech generation mechanism, enabling real-time speech interaction with both comprehension and generation capabilities. Baichuan-Audio leverages a pre-trained ASR model, followed by multi-codebook discretization of speech at a frame rate of 12.5 Hz. This multi-codebook setup ensures that speech tokens retain both semantic and acoustic information. To further enhance modeling, an independent audio head is employed to process audio tokens, effectively capturing their unique characteristics. To mitigate the loss of intelligence during pre-training and preserve the original capabilities of the LLM, we propose a two-stage pre-training strategy that maintains language understanding while enhancing audio modeling. Following alignment, the model excels in real-time speech-based conversation and exhibits outstanding question-answering capabilities, demonstrating its versatility and efficiency. The proposed model demonstrates superior performance in real-time spoken dialogue and exhibits strong question-answering abilities. Our code, model and training data are available at https://github.com/baichuan-inc/Baichuan-Audio
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Ocean-OCR: Towards General OCR Application via a Vision-Language Model
Jan 26, 2025



Multimodal large language models (MLLMs) have shown impressive capabilities across various domains, excelling in processing and understanding information from multiple modalities. Despite the rapid progress made previously, insufficient OCR ability hinders MLLMs from excelling in text-related tasks. In this paper, we present \textbf{Ocean-OCR}, a 3B MLLM with state-of-the-art performance on various OCR scenarios and comparable understanding ability on general tasks. We employ Native Resolution ViT to enable variable resolution input and utilize a substantial collection of high-quality OCR datasets to enhance the model performance. We demonstrate the superiority of Ocean-OCR through comprehensive experiments on open-source OCR benchmarks and across various OCR scenarios. These scenarios encompass document understanding, scene text recognition, and handwritten recognition, highlighting the robust OCR capabilities of Ocean-OCR. Note that Ocean-OCR is the first MLLM to outperform professional OCR models such as TextIn and PaddleOCR.
Beyond Sight: Towards Cognitive Alignment in LVLM via Enriched Visual Knowledge
Nov 25, 2024
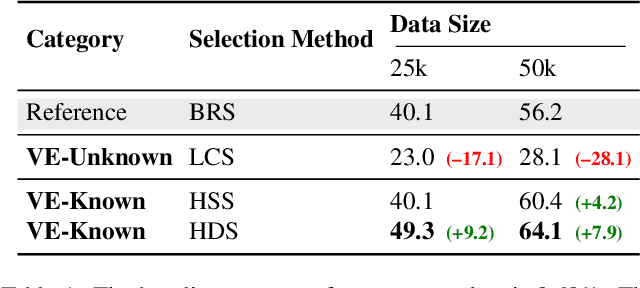
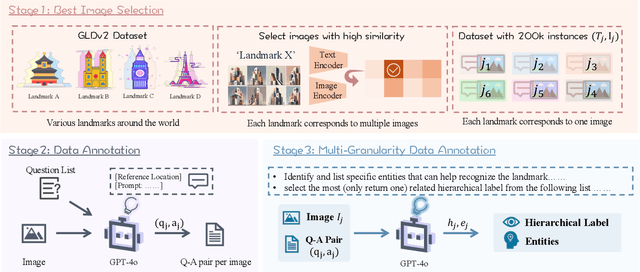

Does seeing always mean knowing? Large Vision-Language Models (LVLMs) integrate separately pre-trained vision and language components, often using CLIP-ViT as vision backbone. However, these models frequently encounter a core issue of "cognitive misalignment" between the vision encoder (VE) and the large language model (LLM). Specifically, the VE's representation of visual information may not fully align with LLM's cognitive framework, leading to a mismatch where visual features exceed the language model's interpretive range. To address this, we investigate how variations in VE representations influence LVLM comprehension, especially when the LLM faces VE-Unknown data-images whose ambiguous visual representations challenge the VE's interpretive precision. Accordingly, we construct a multi-granularity landmark dataset and systematically examine the impact of VE-Known and VE-Unknown data on interpretive abilities. Our results show that VE-Unknown data limits LVLM's capacity for accurate understanding, while VE-Known data, rich in distinctive features, helps reduce cognitive misalignment. Building on these insights, we propose Entity-Enhanced Cognitive Alignment (EECA), a method that employs multi-granularity supervision to generate visually enriched, well-aligned tokens that not only integrate within the LLM's embedding space but also align with the LLM's cognitive framework. This alignment markedly enhances LVLM performance in landmark recognition. Our findings underscore the challenges posed by VE-Unknown data and highlight the essential role of cognitive alignment in advancing multimodal systems.
Baichuan Alignment Technical Report
Oct 19, 2024



We introduce Baichuan Alignment, a detailed analysis of the alignment techniques employed in the Baichuan series of models. This represents the industry's first comprehensive account of alignment methodologies, offering valuable insights for advancing AI research. We investigate the critical components that enhance model performance during the alignment process, including optimization methods, data strategies, capability enhancements, and evaluation processes. The process spans three key stages: Prompt Augmentation System (PAS), Supervised Fine-Tuning (SFT), and Preference Alignment. The problems encountered, the solutions applied, and the improvements made are thoroughly recorded. Through comparisons across well-established benchmarks, we highlight the technological advancements enabled by Baichuan Alignment. Baichuan-Instruct is an internal model, while Qwen2-Nova-72B and Llama3-PBM-Nova-70B are instruct versions of the Qwen2-72B and Llama-3-70B base models, optimized through Baichuan Alignment. Baichuan-Instruct demonstrates significant improvements in core capabilities, with user experience gains ranging from 17% to 28%, and performs exceptionally well on specialized benchmarks. In open-source benchmark evaluations, both Qwen2-Nova-72B and Llama3-PBM-Nova-70B consistently outperform their respective official instruct versions across nearly all datasets. This report aims to clarify the key technologies behind the alignment process, fostering a deeper understanding within the community. Llama3-PBM-Nova-70B model is available at https://huggingface.co/PKU-Baichuan-MLSystemLab/Llama3-PBM-Nova-70B.
Baichuan-Omni Technical Report
Oct 11, 2024



The salient multimodal capabilities and interactive experience of GPT-4o highlight its critical role in practical applications, yet it lacks a high-performing open-source counterpart. In this paper, we introduce Baichuan-Omni, the first open-source 7B Multimodal Large Language Model (MLLM) adept at concurrently processing and analyzing modalities of image, video, audio, and text, while delivering an advanced multimodal interactive experience and strong performance. We propose an effective multimodal training schema starting with 7B model and proceeding through two stages of multimodal alignment and multitask fine-tuning across audio, image, video, and text modal. This approach equips the language model with the ability to handle visual and audio data effectively. Demonstrating strong performance across various omni-modal and multimodal benchmarks, we aim for this contribution to serve as a competitive baseline for the open-source community in advancing multimodal understanding and real-time interaction.
BaichuanSEED: Sharing the Potential of ExtensivE Data Collection and Deduplication by Introducing a Competitive Large Language Model Baseline
Aug 27, 2024
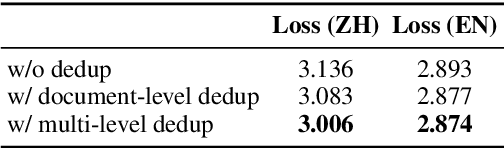

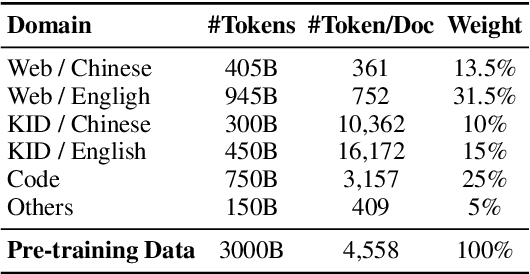
The general capabilities of Large Language Models (LLM) highly rely on the composition and selection on extensive pretraining datasets, treated as commercial secrets by several institutions. To mitigate this issue, we open-source the details of a universally applicable data processing pipeline and validate its effectiveness and potential by introducing a competitive LLM baseline. Specifically, the data processing pipeline consists of broad collection to scale up and reweighting to improve quality. We then pretrain a 7B model BaichuanSEED with 3T tokens processed by our pipeline without any deliberate downstream task-related optimization, followed by an easy but effective supervised fine-tuning stage. BaichuanSEED demonstrates consistency and predictability throughout training and achieves comparable performance on comprehensive benchmarks with several commercial advanced large language models, such as Qwen1.5 and Llama3. We also conduct several heuristic experiments to discuss the potential for further optimization of downstream tasks, such as mathematics and coding.
MathScape: Evaluating MLLMs in multimodal Math Scenarios through a Hierarchical Benchmark
Aug 15, 2024With the development of Multimodal Large Language Models (MLLMs), the evaluation of multimodal models in the context of mathematical problems has become a valuable research field. Multimodal visual-textual mathematical reasoning serves as a critical indicator for evaluating the comprehension and complex multi-step quantitative reasoning abilities of MLLMs. However, previous multimodal math benchmarks have not sufficiently integrated visual and textual information. To address this gap, we proposed MathScape, a new benchmark that emphasizes the understanding and application of combined visual and textual information. MathScape is designed to evaluate photo-based math problem scenarios, assessing the theoretical understanding and application ability of MLLMs through a categorical hierarchical approach. We conduct a multi-dimensional evaluation on 11 advanced MLLMs, revealing that our benchmark is challenging even for the most sophisticated models. By analyzing the evaluation results, we identify the limitations of MLLMs, offering valuable insights for enhancing model performance.
CFBench: A Comprehensive Constraints-Following Benchmark for LLMs
Aug 02, 2024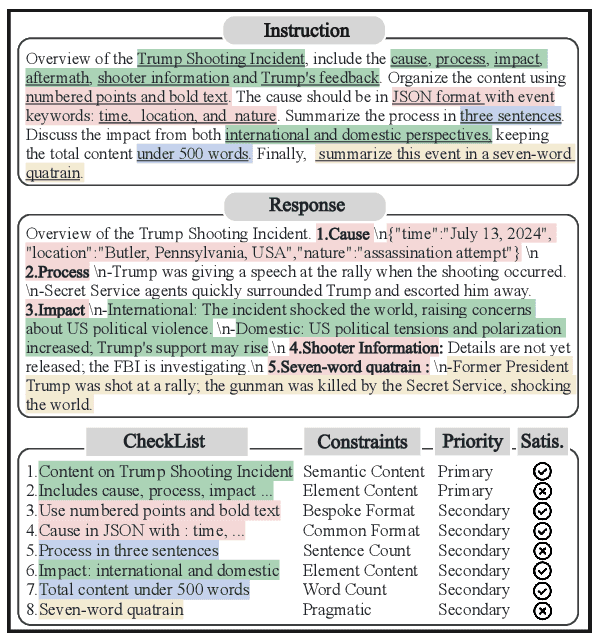


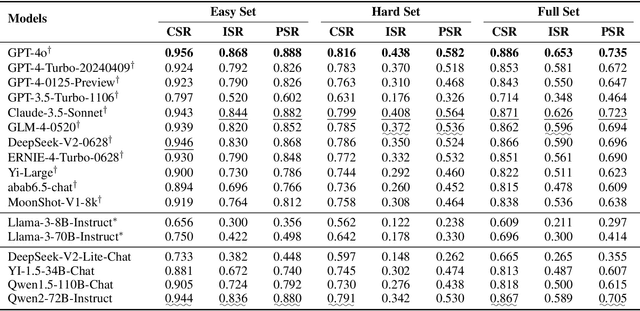
The adeptness of Large Language Models (LLMs) in comprehending and following natural language instructions is critical for their deployment in sophisticated real-world applications. Existing evaluations mainly focus on fragmented constraints or narrow scenarios, but they overlook the comprehensiveness and authenticity of constraints from the user's perspective. To bridge this gap, we propose CFBench, a large-scale Comprehensive Constraints Following Benchmark for LLMs, featuring 1,000 curated samples that cover more than 200 real-life scenarios and over 50 NLP tasks. CFBench meticulously compiles constraints from real-world instructions and constructs an innovative systematic framework for constraint types, which includes 10 primary categories and over 25 subcategories, and ensures each constraint is seamlessly integrated within the instructions. To make certain that the evaluation of LLM outputs aligns with user perceptions, we propose an advanced methodology that integrates multi-dimensional assessment criteria with requirement prioritization, covering various perspectives of constraints, instructions, and requirement fulfillment. Evaluating current leading LLMs on CFBench reveals substantial room for improvement in constraints following, and we further investigate influencing factors and enhancement strategies. The data and code are publicly available at https://github.com/PKU-Baichuan-MLSystemLab/CFBench
PAS: Data-Efficient Plug-and-Play Prompt Augmentation System
Jul 11, 2024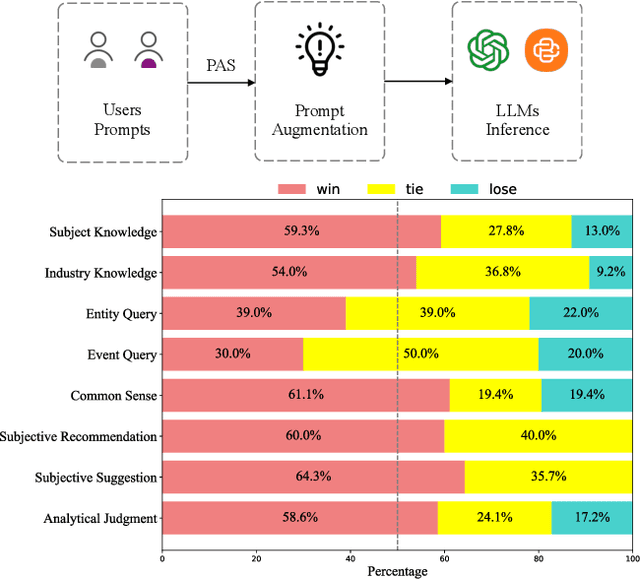
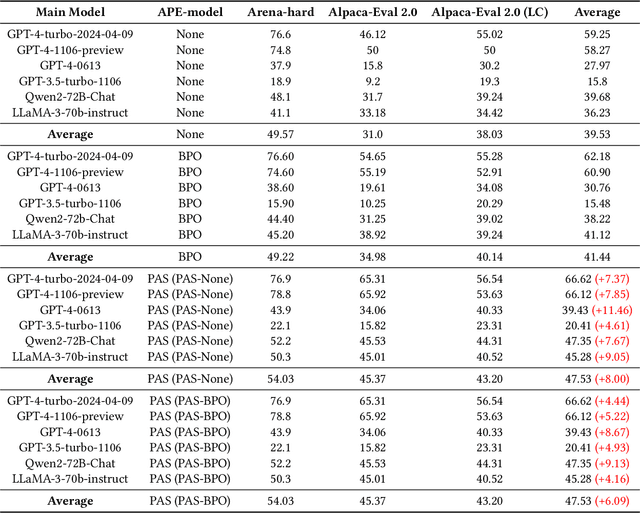

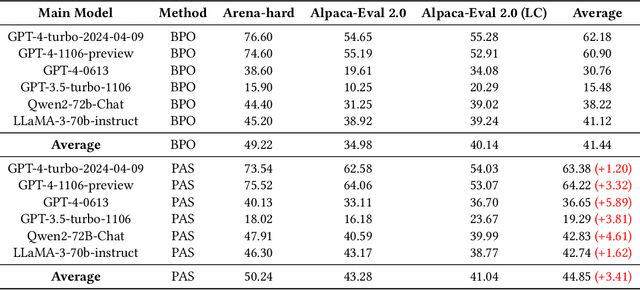
In recent years, the rise of Large Language Models (LLMs) has spurred a growing demand for plug-and-play AI systems. Among the various AI techniques, prompt engineering stands out as particularly significant. However, users often face challenges in writing prompts due to the steep learning curve and significant time investment, and existing automatic prompt engineering (APE) models can be difficult to use. To address this issue, we propose PAS, an LLM-based plug-and-play APE system. PAS utilizes LLMs trained on high-quality, automatically generated prompt complementary datasets, resulting in exceptional performance. In comprehensive benchmarks, PAS achieves state-of-the-art (SoTA) results compared to previous APE models, with an average improvement of 6.09 points. Moreover, PAS is highly efficient, achieving SoTA performance with only 9000 data points. Additionally, PAS can autonomously generate prompt augmentation data without requiring additional human labor. Its flexibility also allows it to be compatible with all existing LLMs and applicable to a wide range of tasks. PAS excels in human evaluations, underscoring its suitability as a plug-in for users. This combination of high performance, efficiency, and flexibility makes PAS a valuable system for enhancing the usability and effectiveness of LLMs through improved prompt engineering.