 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLASS: Geometry-aware Local Alignment and Structure Synchronization Network for 2D-3D Registration
Mar 27, 2026Image-to-point cloud registration methods typically follow a coarse-to-fine pipeline, extracting patch-level correspondences and refining them into dense pixel-to-point matches. However, in scenes with repetitive patterns, images often lack sufficient 3D structural cues and alignment with point clouds, leading to incorrect matches. Moreover, prior methods usually overlook structural consistency, limiting the full exploitation of correspondences. To address these issues, we propose two novel modules: the Local Geometry Enhancement (LGE) module and the Graph Distribution Consistency (GDC) module. LGE enhances both image and point cloud features with normal vectors, injecting geometric structure into image features to reduce mismatches. GDC constructs a graph from matched points to update features and explicitly constrain similarity distributions. Extensive experiments and ablations on two benchmarks, RGB-D Scenes v2 and 7-Scenes, demonstrate that our approach achieves state-of-the-art performance in image-to-point cloud registration.
VCR: Variance-Driven Channel Recalibration for Robust Low-Light Enhancement
Mar 10, 2026Most sRGB-based LLIE methods suffer from entangled luminance and color, while the HSV color space offers insufficient decoupling at the cost of introducing significant red and black noise artifacts. Recently, the HVI color space has been proposed to address these limitations by enhancing color fidelity through chrominance polarization and intensity compression. However, existing methods could suffer from channel-level inconsistency between luminance and chrominance, and misaligned color distribution may lead to unnatural enhancement results. To address these challenges, we propose the Variance-Driven Channel Recalibration for Robust Low-Light Enhancement (VCR), a novel framework for low-light image enhancement. VCR consists of two main components, including the Channel Adaptive Adjustment (CAA) module, which employs variance-guided feature filtering to enhance the model's focus on regions with high intensity and color distribution. And the Color Distribution Alignment (CDA) module, which enforces distribution alignment in the color feature space. These designs enhance perceptual quality under low-light conditions. Experimental results on several benchmark datasets demonstrate that the proposed method achieves state-of-the-art performance compared with existing methods.
Adaptive Agent Selection and Interaction Network for Image-to-point cloud Registration
Nov 08, 2025Typical detection-free methods for image-to-point cloud registration leverage transformer-based architectures to aggregate cross-modal features and establish correspondences. However, they often struggle under challenging conditions, where noise disrupts similarity computation and leads to incorrect correspondences. Moreover, without dedicated designs, it remains difficult to effectively select informative and correlated representations across modalities, thereby limiting the robustness and accuracy of registration. To address these challenges, we propose a novel cross-modal registration framework composed of two key modules: the Iterative Agents Selection (IAS) module and the Reliable Agents Interaction (RAI) module. IAS enhances structural feature awareness with phase maps and employs reinforcement learning principles to efficiently select reliable agents. RAI then leverages these selected agents to guide cross-modal interactions, effectively reducing mismatches and improving overall robustness. Extensive experiments on the RGB-D Scenes v2 and 7-Scenes benchmarks demonstrate that our method consistently achieves state-of-the-art performance.
CA-I2P: Channel-Adaptive Registration Network with Global Optimal Selection
Jun 26, 2025Detection-free methods typically follow a coarse-to-fine pipeline, extracting image and point cloud features for patch-level matching and refining dense pixel-to-point correspondences. However, differences in feature channel attention between images and point clouds may lead to degraded matching results, ultimately impairing registration accuracy. Furthermore, similar structures in the scene could lead to redundant correspondences in cross-modal matching. To address these issues, we propose Channel Adaptive Adjustment Module (CAA) and Global Optimal Selection Module (GOS). CAA enhances intra-modal features and suppresses cross-modal sensitivity, while GOS replaces local selection with global optimization. Experiments on RGB-D Scenes V2 and 7-Scenes demonstrate the superiority of our method, achieving state-of-the-art performance in image-to-point cloud registration.
Bridge 2D-3D: Uncertainty-aware Hierarchical Registration Network with Domain Alignment
Apr 02, 2025The method for image-to-point cloud registration typically determines the rigid transformation using a coarse-to-fine pipeline. However, directly and uniformly matching image patches with point cloud patches may lead to focusing on incorrect noise patches during matching while ignoring key ones. Moreover, due to the significant differences between image and point cloud modalities, it may be challenging to bridge the domain gap without specific improvements in design. To address the above issues, we innovatively propose the Uncertainty-aware Hierarchical Matching Module (UHMM) and the Adversarial Modal Alignment Module (AMAM). Within the UHMM, we model the uncertainty of critical information in image patches and facilitate multi-level fusion interactions between image and point cloud features. In the AMAM, we design an adversarial approach to reduce the domain gap between image and point cloud. Extensive experiments and ablation studies on RGB-D Scene V2 and 7-Scenes benchmarks demonstrate the superiority of our method, making it a state-of-the-art approach for image-to-point cloud registration tasks.
Beyond Sight: Towards Cognitive Alignment in LVLM via Enriched Visual Knowledge
Nov 25, 2024
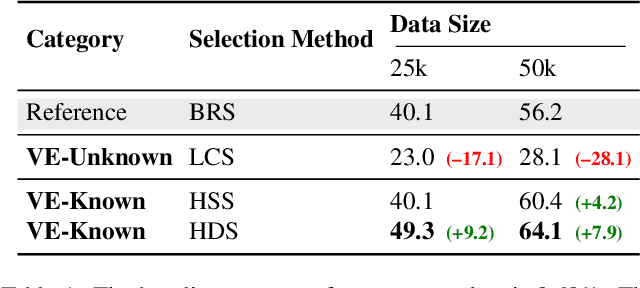
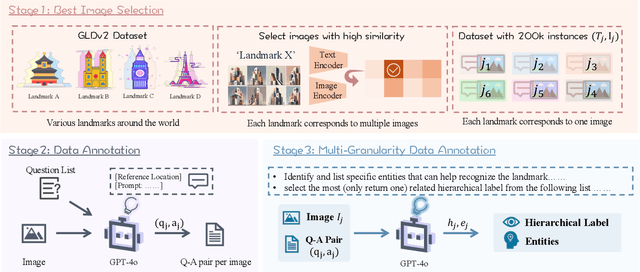

Does seeing always mean knowing? Large Vision-Language Models (LVLMs) integrate separately pre-trained vision and language components, often using CLIP-ViT as vision backbone. However, these models frequently encounter a core issue of "cognitive misalignment" between the vision encoder (VE) and the large language model (LLM). Specifically, the VE's representation of visual information may not fully align with LLM's cognitive framework, leading to a mismatch where visual features exceed the language model's interpretive range. To address this, we investigate how variations in VE representations influence LVLM comprehension, especially when the LLM faces VE-Unknown data-images whose ambiguous visual representations challenge the VE's interpretive precision. Accordingly, we construct a multi-granularity landmark dataset and systematically examine the impact of VE-Known and VE-Unknown data on interpretive abilities. Our results show that VE-Unknown data limits LVLM's capacity for accurate understanding, while VE-Known data, rich in distinctive features, helps reduce cognitive misalignment. Building on these insights, we propose Entity-Enhanced Cognitive Alignment (EECA), a method that employs multi-granularity supervision to generate visually enriched, well-aligned tokens that not only integrate within the LLM's embedding space but also align with the LLM's cognitive framework. This alignment markedly enhances LVLM performance in landmark recognition. Our findings underscore the challenges posed by VE-Unknown data and highlight the essential role of cognitive alignment in advancing multimodal systems.
Towards Precise Scaling Laws for Video Diffusion Transformers
Nov 25, 2024



Achieving optimal performance of video diffusion transformers within given data and compute budget is crucial due to their high training costs. This necessitates precisely determining the optimal model size and training hyperparameters before large-scale training. While scaling laws are employed in language models to predict performance, their existence and accurate derivation in visual generation models remain underexplored. In this paper, we systematically analyze scaling laws for video diffusion transformers and confirm their presence. Moreover, we discover that, unlike language models, video diffusion models are more sensitive to learning rate and batch size, two hyperparameters often not precisely modeled. To address this, we propose a new scaling law that predicts optimal hyperparameters for any model size and compute budget. Under these optimal settings, we achieve comparable performance and reduce inference costs by 40.1% compared to conventional scaling methods, within a compute budget of 1e10 TFlops. Furthermore, we establish a more generalized and precise relationship among validation loss, any model size, and compute budget. This enables performance prediction for non-optimal model sizes, which may also be appealed under practical inference cost constraints, achieving a better trade-off.
SEA: Supervised Embedding Alignment for Token-Level Visual-Textual Integration in MLLMs
Aug 21, 2024Multimodal Large Language Models (MLLMs) have recently demonstrated remarkable perceptual and reasoning abilities, typically comprising a Vision Encoder, an Adapter, and a Large Language Model (LLM). The adapter serves as the critical bridge between the visual and language components. However, training adapters with image-level supervision often results in significant misalignment, undermining the LLMs' capabilities and limiting the potential of Multimodal LLMs. To address this, we introduce Supervised Embedding Alignment (SEA), a token-level alignment method that leverages vision-language pre-trained models, such as CLIP, to align visual tokens with the LLM's embedding space through contrastive learning. This approach ensures a more coherent integration of visual and language representations, enhancing the performance and interpretability of multimodal LLMs while preserving their inherent capabilities. Extensive experiments show that SEA effectively improves MLLMs, particularly for smaller models, without adding extra data or inference computation. SEA also lays the groundwork for developing more general and adaptable solutions to enhance multimodal systems.
CBQ: Cross-Block Quantization for Large Language Models
Dec 13, 2023



Post-training quantization (PTQ) has driven attention to producing efficient large language models (LLMs) with ultra-low costs. Since hand-craft quantization parameters lead to low performance in low-bit quantization, recent methods optimize the quantization parameters through block-wise reconstruction between the floating-point and quantized models. However, these methods suffer from two challenges: accumulated errors from independent one-by-one block quantization and reconstruction difficulties from extreme weight and activation outliers. To address these two challenges, we propose CBQ, a cross-block reconstruction-based PTQ method for LLMs. To reduce error accumulation, we introduce a cross-block dependency with the aid of a homologous reconstruction scheme to build the long-range dependency between adjacent multi-blocks with overlapping. To reduce reconstruction difficulty, we design a coarse-to-fine pre-processing (CFP) to truncate weight outliers and dynamically scale activation outliers before optimization, and an adaptive rounding scheme, called LoRA-Rounding, with two low-rank learnable matrixes to further rectify weight quantization errors. Extensive experiments demonstrate that: (1) CBQ pushes both activation and weight quantization to low-bit settings W4A4, W4A8, and W2A16. (2) CBQ achieves better performance than the existing state-of-the-art methods on various LLMs and benchmark datasets.
Advanced Efficient Strategy for Detection of Dark Objects Based on Spiking Network with Multi-Box Detection
Oct 10, 2023Several deep learning algorithms have shown amazing performance for existing object detection tasks, but recognizing darker objects is the largest challenge. Moreover, those techniques struggled to detect or had a slow recognition rate, resulting in significant performance losses. As a result, an improved and accurate detection approach is required to address the above difficulty. The whole study proposes a combination of spiked and normal convolution layers as an energy-efficient and reliable object detector model. The proposed model is split into two sections. The first section is developed as a feature extractor, which utilizes pre-trained VGG16, and the second section of the proposal structure is the combination of spiked and normal Convolutional layers to detect the bounding boxes of images. We drew a pre-trained model for classifying detected objects. With state of the art Python libraries, spike layers can be trained efficiently. The proposed spike convolutional object detector (SCOD) has been evaluated on VOC and Ex-Dark datasets. SCOD reached 66.01% and 41.25% mAP for detecting 20 different objects in the VOC-12 and 12 objects in the Ex-Dark dataset. SCOD uses 14 Giga FLOPS for its forward path calculations. Experimental results indicated superior performance compared to Tiny YOLO, Spike YOLO, YOLO-LITE, Tinier YOLO and Center of loc+Xception based on mAP for the VOC dataset.