 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing the impact of synthetic native samples and multi-tasking strategies in Hindi-English code-mixed humour and sarcasm detection
Dec 17, 2024



In this paper, we reported our experiments with various strategies to improve code-mixed humour and sarcasm detection. We did all of our experiments for Hindi-English code-mixed scenario, as we have the linguistic expertise for the same. We experimented with three approaches, namely (i) native sample mixing, (ii) multi-task learning (MTL), and (iii) prompting very large multilingual language models (VMLMs). In native sample mixing, we added monolingual task samples in code-mixed training sets. In MTL learning, we relied on native and code-mixed samples of a semantically related task (hate detection in our case). Finally, in our third approach, we evaluated the efficacy of VMLMs via few-shot context prompting. Some interesting findings we got are (i) adding native samples improved humor (raising the F1-score up to 6.76%) and sarcasm (raising the F1-score up to 8.64%) detection, (ii) training MLMs in an MTL framework boosted performance for both humour (raising the F1-score up to 10.67%) and sarcasm (increment up to 12.35% in F1-score) detection, and (iii) prompting VMLMs couldn't outperform the other approaches. Finally, our ablation studies and error analysis discovered the cases where our model is yet to improve. We provided our code for reproducibility.
Improving code-mixed hate detection by native sample mixing: A case study for Hindi-English code-mixed scenario
May 31, 2024


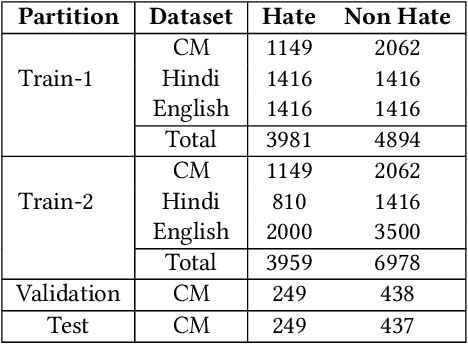
Hate detection has long been a challenging task for the NLP community. The task becomes complex in a code-mixed environment because the models must understand the context and the hate expressed through language alteration. Compared to the monolingual setup, we see very less work on code-mixed hate as large-scale annotated hate corpora are unavailable to make the study. To overcome this bottleneck, we propose using native language hate samples. We hypothesise that in the era of multilingual language models (MLMs), hate in code-mixed settings can be detected by majorly relying on the native language samples. Even though the NLP literature reports the effectiveness of MLMs on hate detection in many cross-lingual settings, their extensive evaluation in a code-mixed scenario is yet to be done. This paper attempts to fill this gap through rigorous empirical experiments. We considered the Hindi-English code-mixed setup as a case study as we have the linguistic expertise for the same. Some of the interesting observations we got are: (i) adding native hate samples in the code-mixed training set, even in small quantity, improved the performance of MLMs for code-mixed hate detection, (ii) MLMs trained with native samples alone observed to be detecting code-mixed hate to a large extent, (iii) The visualisation of attention scores revealed that, when native samples were included in training, MLMs could better focus on the hate emitting words in the code-mixed context, and (iv) finally, when hate is subjective or sarcastic, naively mixing native samples doesn't help much to detect code-mixed hate. We will release the data and code repository to reproduce the reported results.
Sparse Points to Dense Clouds: Enhancing 3D Detection with Limited LiDAR Data
Apr 10, 2024



3D detection is a critical task that enables machines to identify and locate objects in three-dimensional space. It has a broad range of applications in several fields, including autonomous driving, robotics and augmented reality. Monocular 3D detection is attractive as it requires only a single camera, however, it lacks the accuracy and robustness required for real world applications. High resolution LiDAR on the other hand, can be expensive and lead to interference problems in heavy traffic given their active transmissions. We propose a balanced approach that combines the advantages of monocular and point cloud-based 3D detection. Our method requires only a small number of 3D points, that can be obtained from a low-cost, low-resolution sensor. Specifically, we use only 512 points, which is just 1% of a full LiDAR frame in the KITTI dataset. Our method reconstructs a complete 3D point cloud from this limited 3D information combined with a single image. The reconstructed 3D point cloud and corresponding image can be used by any multi-modal off-the-shelf detector for 3D object detection. By using the proposed network architecture with an off-the-shelf multi-modal 3D detector, the accuracy of 3D detection improves by 20% compared to the state-of-the-art monocular detection methods and 6% to 9% compare to the baseline multi-modal methods on KITTI and JackRabbot datasets.
Advanced Efficient Strategy for Detection of Dark Objects Based on Spiking Network with Multi-Box Detection
Oct 10, 2023Several deep learning algorithms have shown amazing performance for existing object detection tasks, but recognizing darker objects is the largest challenge. Moreover, those techniques struggled to detect or had a slow recognition rate, resulting in significant performance losses. As a result, an improved and accurate detection approach is required to address the above difficulty. The whole study proposes a combination of spiked and normal convolution layers as an energy-efficient and reliable object detector model. The proposed model is split into two sections. The first section is developed as a feature extractor, which utilizes pre-trained VGG16, and the second section of the proposal structure is the combination of spiked and normal Convolutional layers to detect the bounding boxes of images. We drew a pre-trained model for classifying detected objects. With state of the art Python libraries, spike layers can be trained efficiently. The proposed spike convolutional object detector (SCOD) has been evaluated on VOC and Ex-Dark datasets. SCOD reached 66.01% and 41.25% mAP for detecting 20 different objects in the VOC-12 and 12 objects in the Ex-Dark dataset. SCOD uses 14 Giga FLOPS for its forward path calculations. Experimental results indicated superior performance compared to Tiny YOLO, Spike YOLO, YOLO-LITE, Tinier YOLO and Center of loc+Xception based on mAP for the VOC dataset.
Applying adversarial networks to increase the data efficiency and reliability of Self-Driving Cars
Feb 16, 2022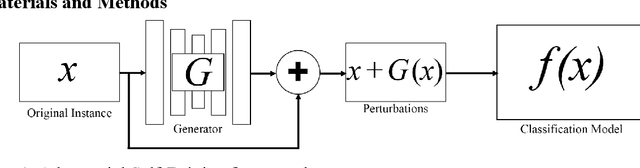

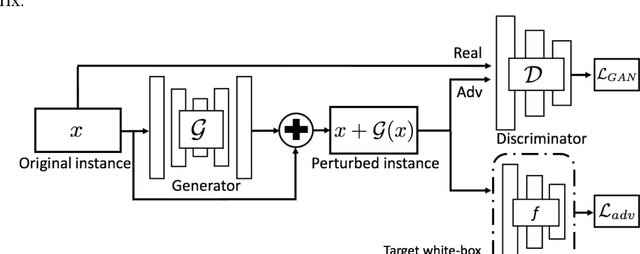
Convolutional Neural Networks (CNNs) are vulnerable to misclassifying images when small perturbations are present. With the increasing prevalence of CNNs in self-driving cars, it is vital to ensure these algorithms are robust to prevent collisions from occurring due to failure in recognizing a situation. In the Adversarial Self-Driving framework, a Generative Adversarial Network (GAN) is implemented to generate realistic perturbations in an image that cause a classifier CNN to misclassify data. This perturbed data is then used to train the classifier CNN further. The Adversarial Self-driving framework is applied to an image classification algorithm to improve the classification accuracy on perturbed images and is later applied to train a self-driving car to drive in a simulation. A small-scale self-driving car is also built to drive around a track and classify signs. The Adversarial Self-driving framework produces perturbed images through learning a dataset, as a result removing the need to train on significant amounts of data. Experiments demonstrate that the Adversarial Self-driving framework identifies situations where CNNs are vulnerable to perturbations and generates new examples of these situations for the CNN to train on. The additional data generated by the Adversarial Self-driving framework provides sufficient data for the CNN to generalize to the environment. Therefore, it is a viable tool to increase the resilience of CNNs to perturbations. Particularly, in the real-world self-driving car, the application of the Adversarial Self-Driving framework resulted in an 18 % increase in accuracy, and the simulated self-driving model had no collisions in 30 minutes of driving.
PC-DAN: Point Cloud based Deep Affinity Network for 3D Multi-Object Tracking
Jun 03, 2021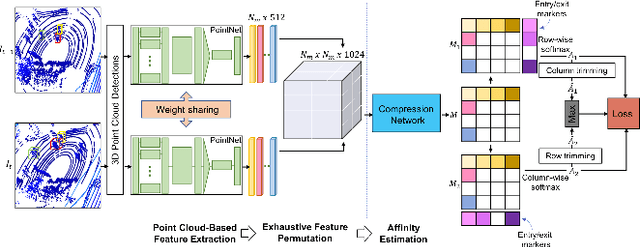
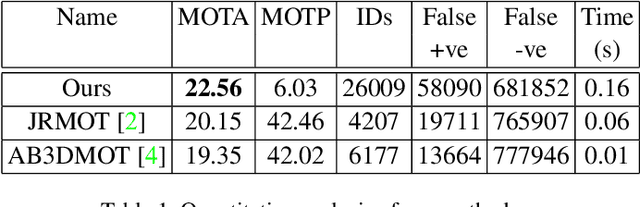
In recent times, the scope of LIDAR (Light Detection and Ranging) sensor-based technology has spread across numerous fields. It is popularly used to map terrain and navigation information into reliable 3D point cloud data, potentially revolutionizing the autonomous vehicles and assistive robotic industry. A point cloud is a dense compilation of spatial data in 3D coordinates. It plays a vital role in modeling complex real-world scenes since it preserves structural information and avoids perspective distortion, unlike image data, which is the projection of a 3D structure on a 2D plane. In order to leverage the intrinsic capabilities of the LIDAR data, we propose a PointNet-based approach for 3D Multi-Object Tracking (MOT).