 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeither Here Nor There: Cross-Lingual Representation Dynamics of Code-Mixed Text in Multilingual Encoders
Mar 20, 2026Multilingual encoder-based language models are widely adopted for code-mixed analysis tasks, yet we know surprisingly little about how they represent code-mixed inputs internally - or whether those representations meaningfully connect to the constituent languages being mixed. Using Hindi-English as a case study, we construct a unified trilingual corpus of parallel English, Hindi (Devanagari), and Romanized code-mixed sentences, and probe cross-lingual representation alignment across standard multilingual encoders and their code-mixed adapted variants via CKA, token-level saliency, and entropy-based uncertainty analysis. We find that while standard models align English and Hindi well, code-mixed inputs remain loosely connected to either language - and that continued pre-training on code-mixed data improves English-code-mixed alignment at the cost of English-Hindi alignment. Interpretability analyses further reveal a clear asymmetry: models process code-mixed text through an English-dominant semantic subspace, while native-script Hindi provides complementary signals that reduce representational uncertainty. Motivated by these findings, we introduce a trilingual post-training alignment objective that brings code-mixed representations closer to both constituent languages simultaneously, yielding more balanced cross-lingual alignment and downstream gains on sentiment analysis and hate speech detection - showing that grounding code-mixed representations in their constituent languages meaningfully helps cross-lingual understanding.
On VLMs for Diverse Tasks in Multimodal Meme Classification
May 27, 2025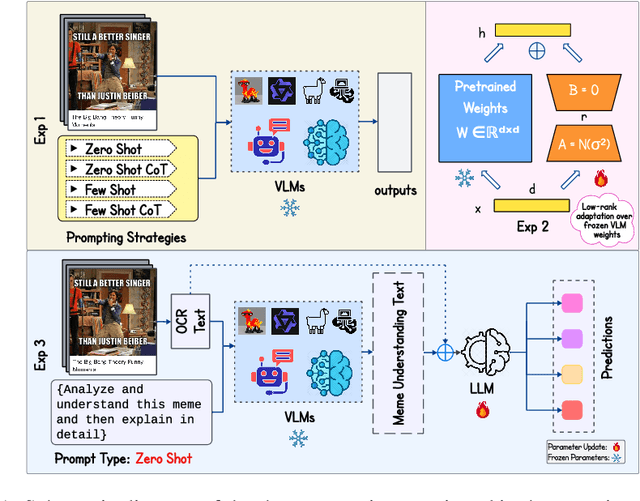



In this paper, we present a comprehensive and systematic analysis of vision-language models (VLMs) for disparate meme classification tasks. We introduced a novel approach that generates a VLM-based understanding of meme images and fine-tunes the LLMs on textual understanding of the embedded meme text for improving the performance. Our contributions are threefold: (1) Benchmarking VLMs with diverse prompting strategies purposely to each sub-task; (2) Evaluating LoRA fine-tuning across all VLM components to assess performance gains; and (3) Proposing a novel approach where detailed meme interpretations generated by VLMs are used to train smaller language models (LLMs), significantly improving classification. The strategy of combining VLMs with LLMs improved the baseline performance by 8.34%, 3.52% and 26.24% for sarcasm, offensive and sentiment classification, respectively. Our results reveal the strengths and limitations of VLMs and present a novel strategy for meme understanding.
Improving the fact-checking performance of language models by relying on their entailment ability
May 21, 2025Automated fact-checking is a crucial task in this digital age. To verify a claim, current approaches majorly follow one of two strategies i.e. (i) relying on embedded knowledge of language models, and (ii) fine-tuning them with evidence pieces. While the former can make systems to hallucinate, the later have not been very successful till date. The primary reason behind this is that fact verification is a complex process. Language models have to parse through multiple pieces of evidence before making a prediction. Further, the evidence pieces often contradict each other. This makes the reasoning process even more complex. We proposed a simple yet effective approach where we relied on entailment and the generative ability of language models to produce ''supporting'' and ''refuting'' justifications (for the truthfulness of a claim). We trained language models based on these justifications and achieved superior results. Apart from that, we did a systematic comparison of different prompting and fine-tuning strategies, as it is currently lacking in the literature. Some of our observations are: (i) training language models with raw evidence sentences registered an improvement up to 8.20% in macro-F1, over the best performing baseline for the RAW-FC dataset, (ii) similarly, training language models with prompted claim-evidence understanding (TBE-2) registered an improvement (with a margin up to 16.39%) over the baselines for the same dataset, (iii) training language models with entailed justifications (TBE-3) outperformed the baselines by a huge margin (up to 28.57% and 44.26% for LIAR-RAW and RAW-FC, respectively). We have shared our code repository to reproduce the results.
Revealing the impact of synthetic native samples and multi-tasking strategies in Hindi-English code-mixed humour and sarcasm detection
Dec 17, 2024



In this paper, we reported our experiments with various strategies to improve code-mixed humour and sarcasm detection. We did all of our experiments for Hindi-English code-mixed scenario, as we have the linguistic expertise for the same. We experimented with three approaches, namely (i) native sample mixing, (ii) multi-task learning (MTL), and (iii) prompting very large multilingual language models (VMLMs). In native sample mixing, we added monolingual task samples in code-mixed training sets. In MTL learning, we relied on native and code-mixed samples of a semantically related task (hate detection in our case). Finally, in our third approach, we evaluated the efficacy of VMLMs via few-shot context prompting. Some interesting findings we got are (i) adding native samples improved humor (raising the F1-score up to 6.76%) and sarcasm (raising the F1-score up to 8.64%) detection, (ii) training MLMs in an MTL framework boosted performance for both humour (raising the F1-score up to 10.67%) and sarcasm (increment up to 12.35% in F1-score) detection, and (iii) prompting VMLMs couldn't outperform the other approaches. Finally, our ablation studies and error analysis discovered the cases where our model is yet to improve. We provided our code for reproducibility.
Improving code-mixed hate detection by native sample mixing: A case study for Hindi-English code-mixed scenario
May 31, 2024


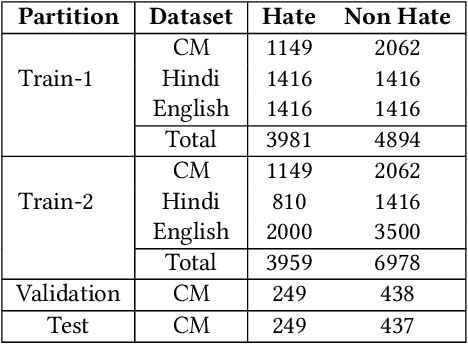
Hate detection has long been a challenging task for the NLP community. The task becomes complex in a code-mixed environment because the models must understand the context and the hate expressed through language alteration. Compared to the monolingual setup, we see very less work on code-mixed hate as large-scale annotated hate corpora are unavailable to make the study. To overcome this bottleneck, we propose using native language hate samples. We hypothesise that in the era of multilingual language models (MLMs), hate in code-mixed settings can be detected by majorly relying on the native language samples. Even though the NLP literature reports the effectiveness of MLMs on hate detection in many cross-lingual settings, their extensive evaluation in a code-mixed scenario is yet to be done. This paper attempts to fill this gap through rigorous empirical experiments. We considered the Hindi-English code-mixed setup as a case study as we have the linguistic expertise for the same. Some of the interesting observations we got are: (i) adding native hate samples in the code-mixed training set, even in small quantity, improved the performance of MLMs for code-mixed hate detection, (ii) MLMs trained with native samples alone observed to be detecting code-mixed hate to a large extent, (iii) The visualisation of attention scores revealed that, when native samples were included in training, MLMs could better focus on the hate emitting words in the code-mixed context, and (iv) finally, when hate is subjective or sarcastic, naively mixing native samples doesn't help much to detect code-mixed hate. We will release the data and code repository to reproduce the reported results.