 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the fact-checking performance of language models by relying on their entailment ability
May 21, 2025Automated fact-checking is a crucial task in this digital age. To verify a claim, current approaches majorly follow one of two strategies i.e. (i) relying on embedded knowledge of language models, and (ii) fine-tuning them with evidence pieces. While the former can make systems to hallucinate, the later have not been very successful till date. The primary reason behind this is that fact verification is a complex process. Language models have to parse through multiple pieces of evidence before making a prediction. Further, the evidence pieces often contradict each other. This makes the reasoning process even more complex. We proposed a simple yet effective approach where we relied on entailment and the generative ability of language models to produce ''supporting'' and ''refuting'' justifications (for the truthfulness of a claim). We trained language models based on these justifications and achieved superior results. Apart from that, we did a systematic comparison of different prompting and fine-tuning strategies, as it is currently lacking in the literature. Some of our observations are: (i) training language models with raw evidence sentences registered an improvement up to 8.20% in macro-F1, over the best performing baseline for the RAW-FC dataset, (ii) similarly, training language models with prompted claim-evidence understanding (TBE-2) registered an improvement (with a margin up to 16.39%) over the baselines for the same dataset, (iii) training language models with entailed justifications (TBE-3) outperformed the baselines by a huge margin (up to 28.57% and 44.26% for LIAR-RAW and RAW-FC, respectively). We have shared our code repository to reproduce the results.
Graph Transformers without Positional Encodings
Jan 31, 2024



Recently, Transformers for graph representation learning have become increasingly popular, achieving state-of-the-art performance on a wide-variety of datasets, either alone or in combination with message-passing graph neural networks (MP-GNNs). Infusing graph inductive-biases in the innately structure-agnostic transformer architecture in the form of structural or positional encodings (PEs) is key to achieving these impressive results. However, designing such encodings is tricky and disparate attempts have been made to engineer such encodings including Laplacian eigenvectors, relative random-walk probabilities (RRWP), spatial encodings, centrality encodings, edge encodings etc. In this work, we argue that such encodings may not be required at all, provided the attention mechanism itself incorporates information about the graph structure. We introduce Eigenformer, which uses a novel spectrum-aware attention mechanism cognizant of the Laplacian spectrum of the graph, and empirically show that it achieves performance comparable to SOTA MP-GNN architectures and Graph Transformers on a number of standard GNN benchmark datasets, even surpassing the SOTA on some datasets. We also find that our architecture is much faster to train in terms of number of epochs, presumably due to the innate graph inductive biases.
Towards Earlier Detection of Oral Diseases On Smartphones Using Oral and Dental RGB Images
Aug 30, 2023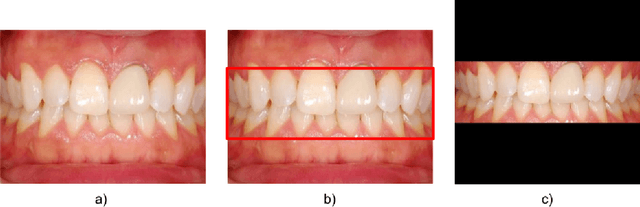

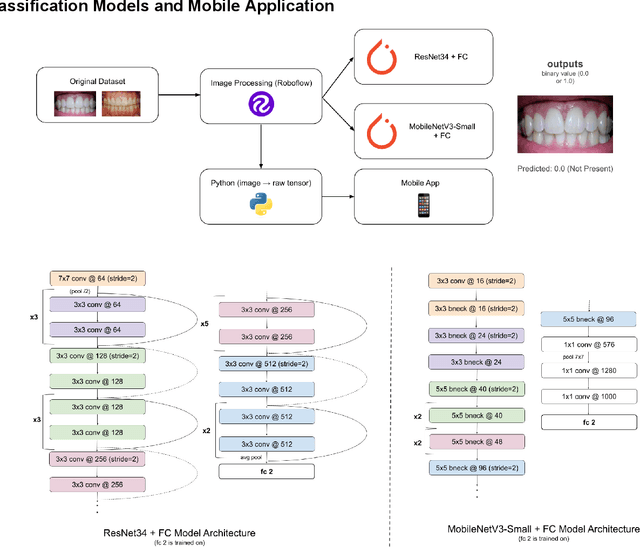

Oral diseases such as periodontal (gum) diseases and dental caries (cavities) affect billions of people across the world today. However, previous state-of-the-art models have relied on X-ray images to detect oral diseases, making them inaccessible to remote monitoring, developing countries, and telemedicine. To combat this overuse of X-ray imagery, we propose a lightweight machine learning model capable of detecting calculus (also known as hardened plaque or tartar) in RGB images while running efficiently on low-end devices. The model, a modified MobileNetV3-Small neural network transfer learned from ImageNet, achieved an accuracy of 72.73% (which is comparable to state-of-the-art solutions) while still being able to run on mobile devices due to its reduced memory requirements and processing times. A ResNet34-based model was also constructed and achieved an accuracy of 81.82%. Both of these models were tested on a mobile app, demonstrating their potential to limit the number of serious oral disease cases as their predictions can help patients schedule appointments earlier without the need to go to the clinic.
Towards efficient end-to-end speech recognition with biologically-inspired neural networks
Oct 04, 2021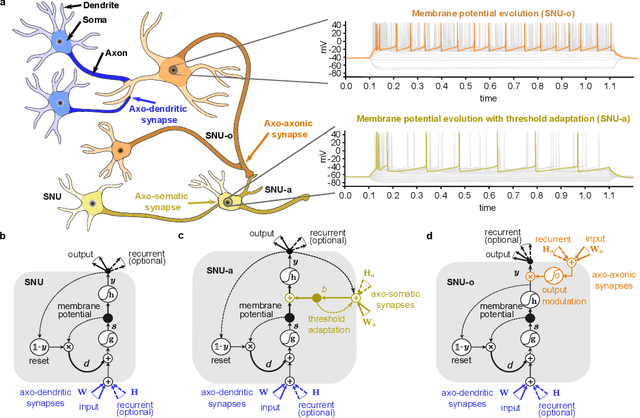


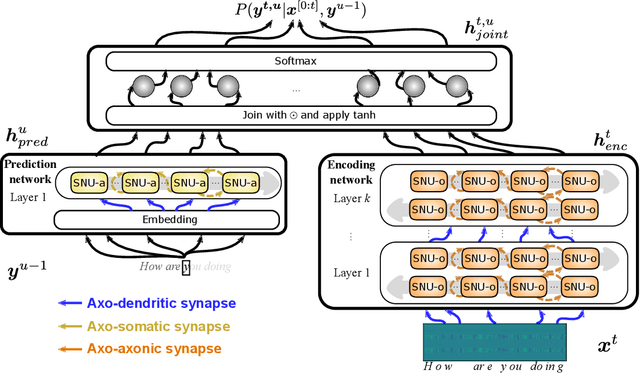
Automatic speech recognition (ASR) is a capability which enables a program to process human speech into a written form. Recent developments in artificial intelligence (AI) have led to high-accuracy ASR systems based on deep neural networks, such as the recurrent neural network transducer (RNN-T). However, the core components and the performed operations of these approaches depart from the powerful biological counterpart, i.e., the human brain. On the other hand, the current developments in biologically-inspired ASR models, based on spiking neural networks (SNNs), lag behind in terms of accuracy and focus primarily on small scale applications. In this work, we revisit the incorporation of biologically-plausible models into deep learning and we substantially enhance their capabilities, by taking inspiration from the diverse neural and synaptic dynamics found in the brain. In particular, we introduce neural connectivity concepts emulating the axo-somatic and the axo-axonic synapses. Based on this, we propose novel deep learning units with enriched neuro-synaptic dynamics and integrate them into the RNN-T architecture. We demonstrate for the first time, that a biologically realistic implementation of a large-scale ASR model can yield competitive performance levels compared to the existing deep learning models. Specifically, we show that such an implementation bears several advantages, such as a reduced computational cost and a lower latency, which are critical for speech recognition applications.
MIPE: A Metric Independent Pipeline for Effective Code-Mixed NLG Evaluation
Jul 24, 2021
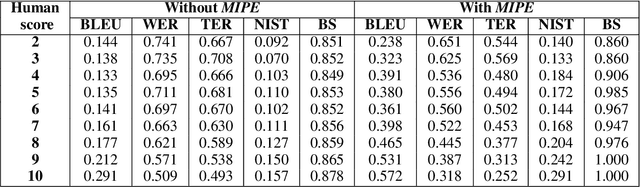
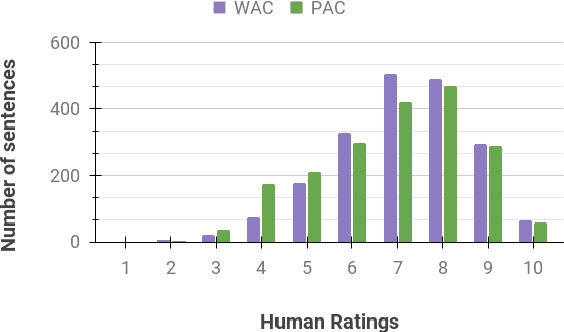
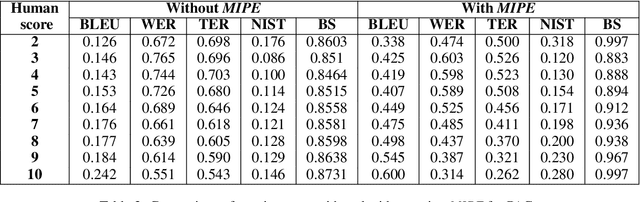
Code-mixing is a phenomenon of mixing words and phrases from two or more languages in a single utterance of speech and text. Due to the high linguistic diversity, code-mixing presents several challenges in evaluating standard natural language generation (NLG) tasks. Various widely popular metrics perform poorly with the code-mixed NLG tasks. To address this challenge, we present a metric independent evaluation pipeline MIPE that significantly improves the correlation between evaluation metrics and human judgments on the generated code-mixed text. As a use case, we demonstrate the performance of MIPE on the machine-generated Hinglish (code-mixing of Hindi and English languages) sentences from the HinGE corpus. We can extend the proposed evaluation strategy to other code-mixed language pairs, NLG tasks, and evaluation metrics with minimal to no effort.
SEAL: Scientific Keyphrase Extraction and Classification
Jun 05, 2020
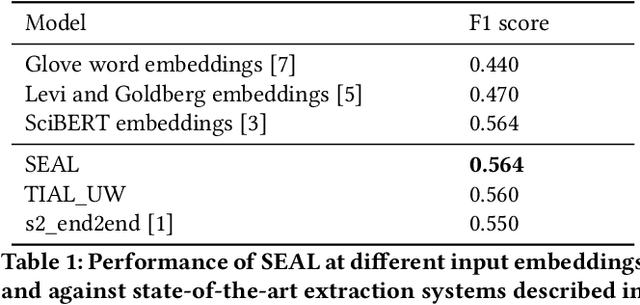

Automatic scientific keyphrase extraction is a challenging problem facilitating several downstream scholarly tasks like search, recommendation, and ranking. In this paper, we introduce SEAL, a scholarly tool for automatic keyphrase extraction and classification. The keyphrase extraction module comprises two-stage neural architecture composed of Bidirectional Long Short-Term Memory cells augmented with Conditional Random Fields. The classification module comprises of a Random Forest classifier. We extensively experiment to showcase the robustness of the system. We evaluate multiple state-of-the-art baselines and show a significant improvement. The current system is hosted at http://lingo.iitgn.ac.in:5000/.