 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKurTail : Kurtosis-based LLM Quantization
Mar 03, 2025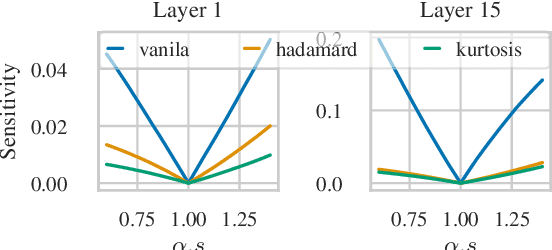
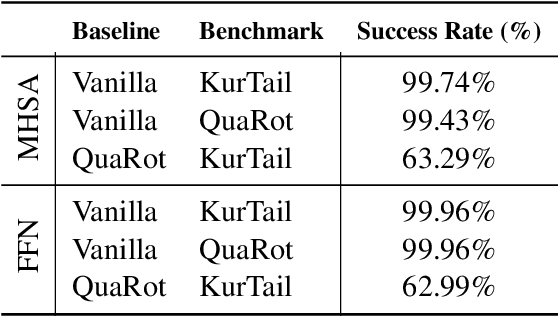
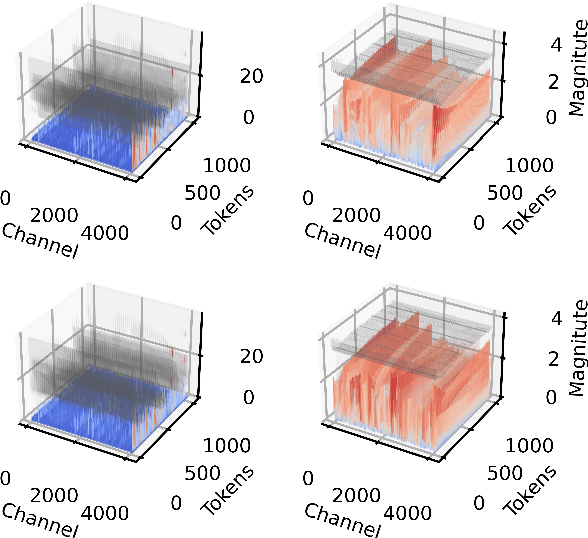
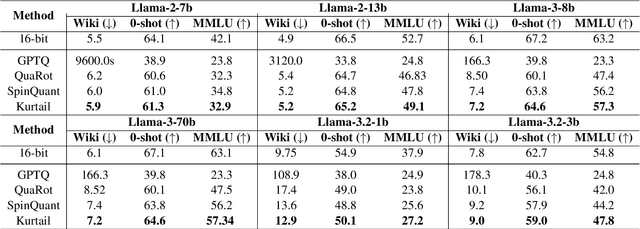
One of the challenges of quantizing a large language model (LLM) is the presence of outliers. Outliers often make uniform quantization schemes less effective, particularly in extreme cases such as 4-bit quantization. We introduce KurTail, a new post-training quantization (PTQ) scheme that leverages Kurtosis-based rotation to mitigate outliers in the activations of LLMs. Our method optimizes Kurtosis as a measure of tailedness. This approach enables the quantization of weights, activations, and the KV cache in 4 bits. We utilize layer-wise optimization, ensuring memory efficiency. KurTail outperforms existing quantization methods, offering a 13.3\% boost in MMLU accuracy and a 15.5\% drop in Wiki perplexity compared to QuaRot. It also outperforms SpinQuant with a 2.6\% MMLU gain and reduces perplexity by 2.9\%, all while reducing the training cost. For comparison, learning the rotation using SpinQuant for Llama3-70B requires at least four NVIDIA H100 80GB GPUs, whereas our method requires only a single GPU, making it a more accessible solution for consumer GPU.
EfQAT: An Efficient Framework for Quantization-Aware Training
Nov 17, 2024



Quantization-aware training (QAT) schemes have been shown to achieve near-full precision accuracy. They accomplish this by training a quantized model for multiple epochs. This is computationally expensive, mainly because of the full precision backward pass. On the other hand, post-training quantization (PTQ) schemes do not involve training and are therefore computationally cheap, but they usually result in a significant accuracy drop. We address these challenges by proposing EfQAT, which generalizes both schemes by optimizing only a subset of the parameters of a quantized model. EfQAT starts by applying a PTQ scheme to a pre-trained model and only updates the most critical network parameters while freezing the rest, accelerating the backward pass. We demonstrate the effectiveness of EfQAT on various CNNs and Transformer-based models using different GPUs. Specifically, we show that EfQAT is significantly more accurate than PTQ with little extra compute. Furthermore, EfQAT can accelerate the QAT backward pass between 1.44-1.64x while retaining most accuracy.
Differentiable Transportation Pruning
Jul 31, 2023Deep learning algorithms are increasingly employed at the edge. However, edge devices are resource constrained and thus require efficient deployment of deep neural networks. Pruning methods are a key tool for edge deployment as they can improve storage, compute, memory bandwidth, and energy usage. In this paper we propose a novel accurate pruning technique that allows precise control over the output network size. Our method uses an efficient optimal transportation scheme which we make end-to-end differentiable and which automatically tunes the exploration-exploitation behavior of the algorithm to find accurate sparse sub-networks. We show that our method achieves state-of-the-art performance compared to previous pruning methods on 3 different datasets, using 5 different models, across a wide range of pruning ratios, and with two types of sparsity budgets and pruning granularities.
On the visual analytic intelligence of neural networks
Sep 28, 2022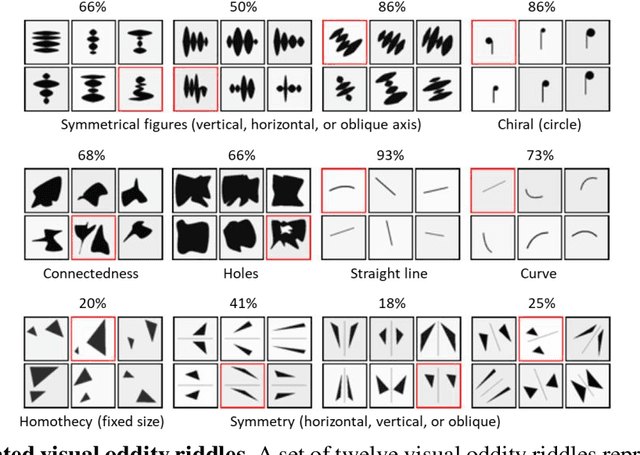
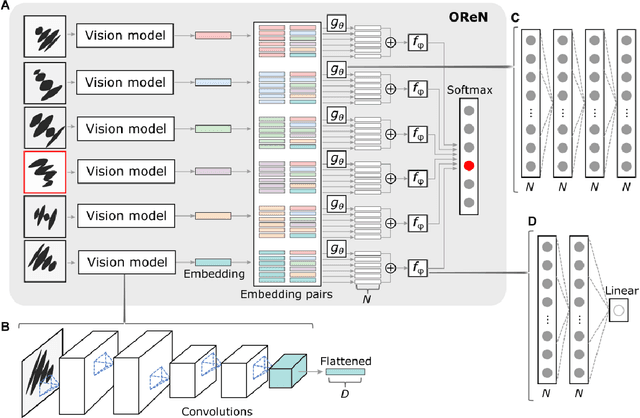
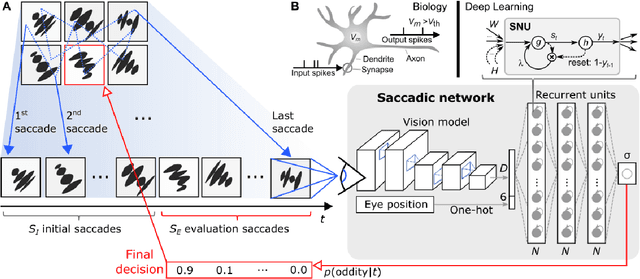
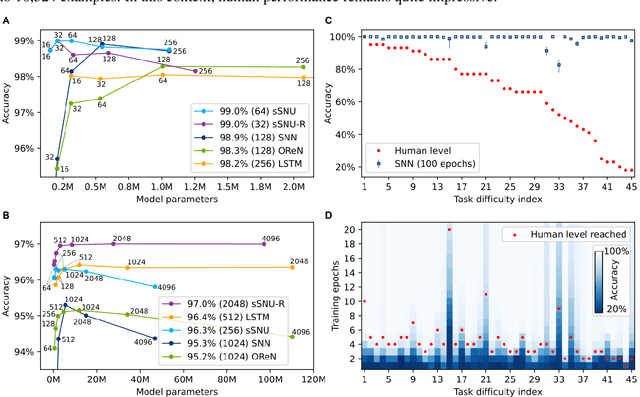
Visual oddity task was conceived as a universal ethnic-independent analytic intelligence test for humans. Advancements in artificial intelligence led to important breakthroughs, yet competing with humans on such analytic intelligence tasks remains challenging and typically resorts to non-biologically-plausible architectures. We present a biologically realistic system that receives inputs from synthetic eye movements - saccades, and processes them with neurons incorporating dynamics of neocortical neurons. We introduce a procedurally generated visual oddity dataset to train an architecture extending conventional relational networks and our proposed system. Both approaches surpass the human accuracy, and we uncover that both share the same essential underlying mechanism of reasoning. Finally, we show that the biologically inspired network achieves superior accuracy, learns faster and requires fewer parameters than the conventional network.
Towards efficient end-to-end speech recognition with biologically-inspired neural networks
Oct 04, 2021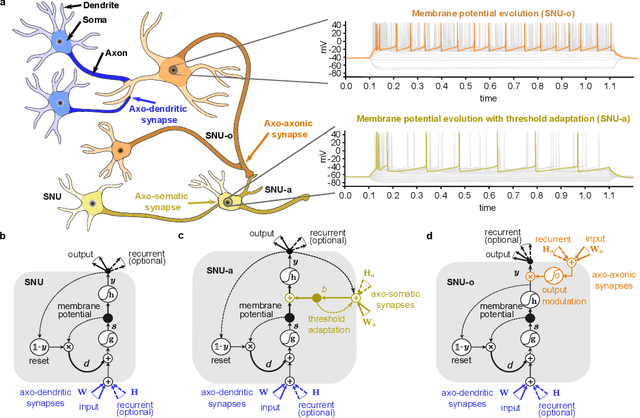


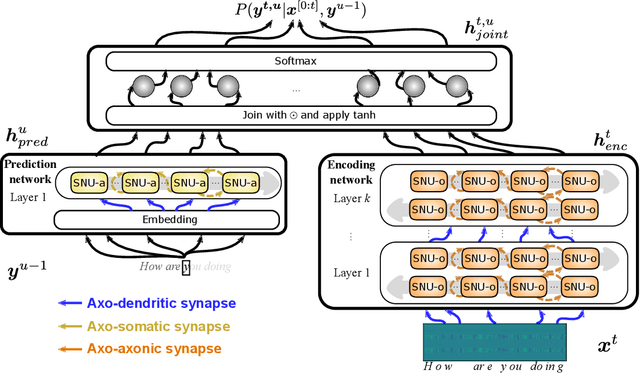
Automatic speech recognition (ASR) is a capability which enables a program to process human speech into a written form. Recent developments in artificial intelligence (AI) have led to high-accuracy ASR systems based on deep neural networks, such as the recurrent neural network transducer (RNN-T). However, the core components and the performed operations of these approaches depart from the powerful biological counterpart, i.e., the human brain. On the other hand, the current developments in biologically-inspired ASR models, based on spiking neural networks (SNNs), lag behind in terms of accuracy and focus primarily on small scale applications. In this work, we revisit the incorporation of biologically-plausible models into deep learning and we substantially enhance their capabilities, by taking inspiration from the diverse neural and synaptic dynamics found in the brain. In particular, we introduce neural connectivity concepts emulating the axo-somatic and the axo-axonic synapses. Based on this, we propose novel deep learning units with enriched neuro-synaptic dynamics and integrate them into the RNN-T architecture. We demonstrate for the first time, that a biologically realistic implementation of a large-scale ASR model can yield competitive performance levels compared to the existing deep learning models. Specifically, we show that such an implementation bears several advantages, such as a reduced computational cost and a lower latency, which are critical for speech recognition applications.
Learning in Deep Neural Networks Using a Biologically Inspired Optimizer
Apr 23, 2021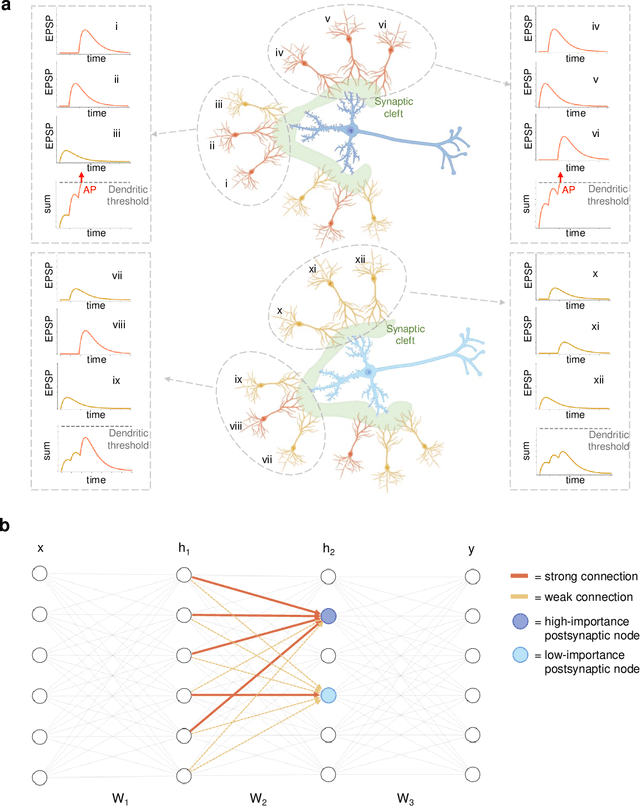
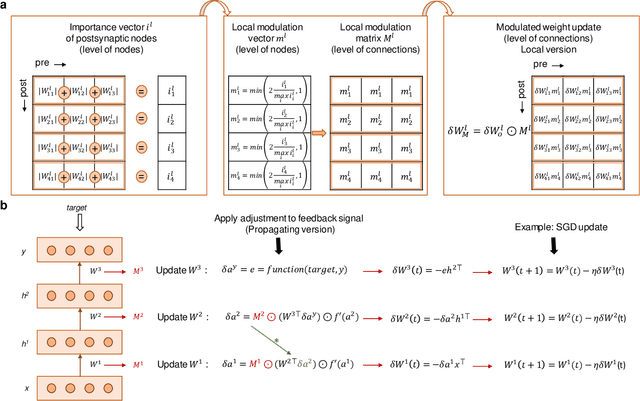
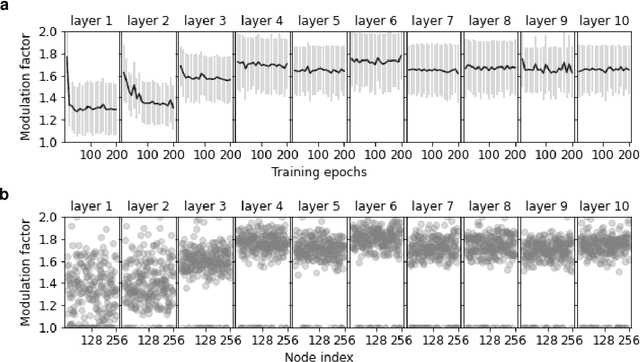
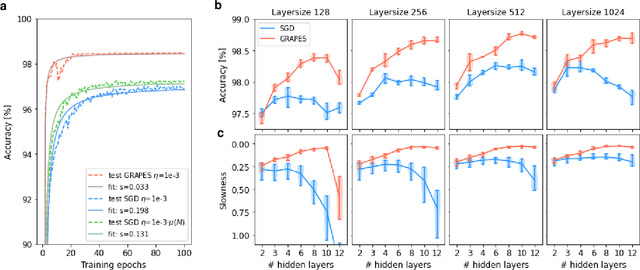
Plasticity circuits in the brain are known to be influenced by the distribution of the synaptic weights through the mechanisms of synaptic integration and local regulation of synaptic strength. However, the complex interplay of stimulation-dependent plasticity with local learning signals is disregarded by most of the artificial neural network training algorithms devised so far. Here, we propose a novel biologically inspired optimizer for artificial (ANNs) and spiking neural networks (SNNs) that incorporates key principles of synaptic integration observed in dendrites of cortical neurons: GRAPES (Group Responsibility for Adjusting the Propagation of Error Signals). GRAPES implements a weight-distribution dependent modulation of the error signal at each node of the neural network. We show that this biologically inspired mechanism leads to a systematic improvement of the convergence rate of the network, and substantially improves classification accuracy of ANNs and SNNs with both feedforward and recurrent architectures. Furthermore, we demonstrate that GRAPES supports performance scalability for models of increasing complexity and mitigates catastrophic forgetting by enabling networks to generalize to unseen tasks based on previously acquired knowledge. The local characteristics of GRAPES minimize the required memory resources, making it optimally suited for dedicated hardware implementations. Overall, our work indicates that reconciling neurophysiology insights with machine intelligence is key to boosting the performance of neural networks.
Short-term synaptic plasticity optimally models continuous environments
Sep 15, 2020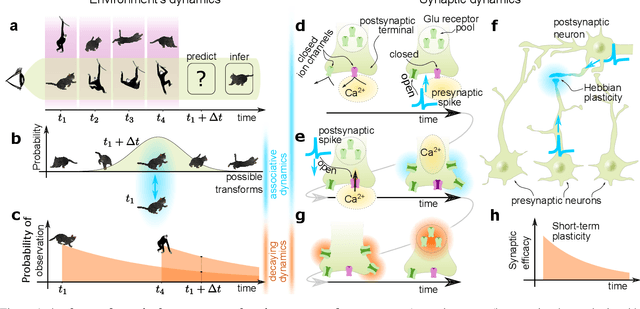
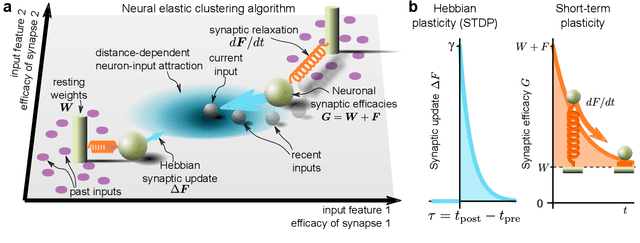
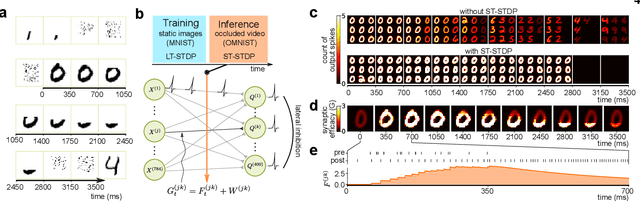
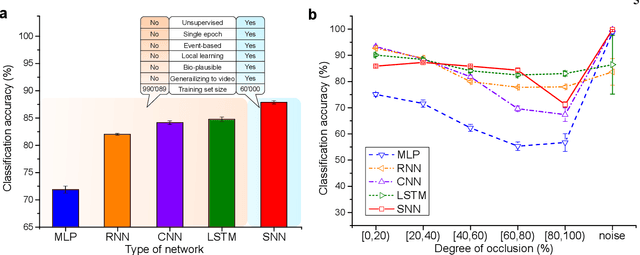
Biological neural networks operate with extraordinary energy efficiency, owing to properties such as spike-based communication and synaptic plasticity driven by local activity. When emulated in silico, such properties also enable highly energy-efficient machine learning and inference systems. However, it is unclear whether these mechanisms only trade off performance for efficiency or rather they are partly responsible for the superiority of biological intelligence. Here, we first address this theoretically, proving rigorously that indeed the optimal prediction and inference of randomly but continuously transforming environments, a common natural setting, relies on adaptivity through short-term spike-timing dependent plasticity, a hallmark of biological neural networks. Secondly, we assess this theoretical optimality via simulations and also demonstrate improved artificial intelligence (AI). For the first time, a largely biologically modelled spiking neural network (SNN) surpasses state-of-the-art artificial neural networks (ANNs) in all relevant aspects, in an example task of recognizing video frames transformed by moving occlusions. The SNN recognizes the frames more accurately, even if trained on few, still, and untransformed images, with unsupervised and synaptically-local learning, binary spikes, and a single layer of neurons - all in contrast to the deep-learning-trained ANNs. These results indicate that on-line adaptivity and spike-based computation may optimize natural intelligence for natural environments. Moreover, this expands the goal of exploiting biological neuro-synaptic properties for AI, from mere efficiency, to computational supremacy altogether.
Online spatio-temporal learning in deep neural networks
Jul 24, 2020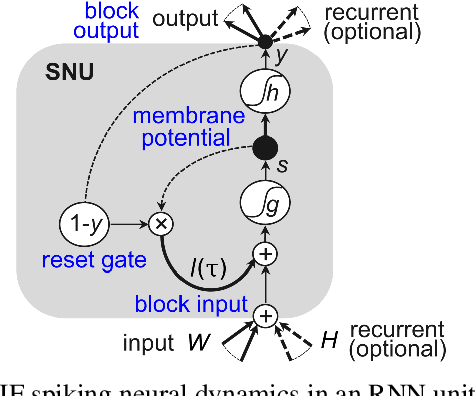
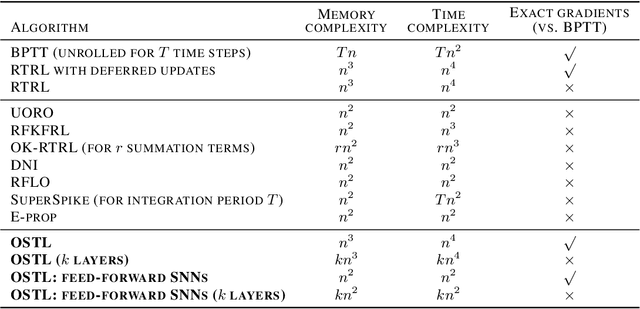
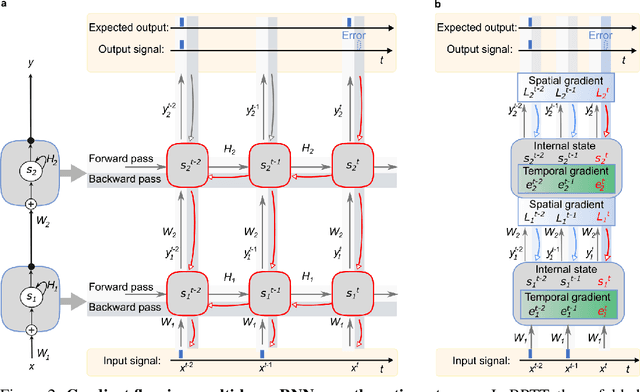
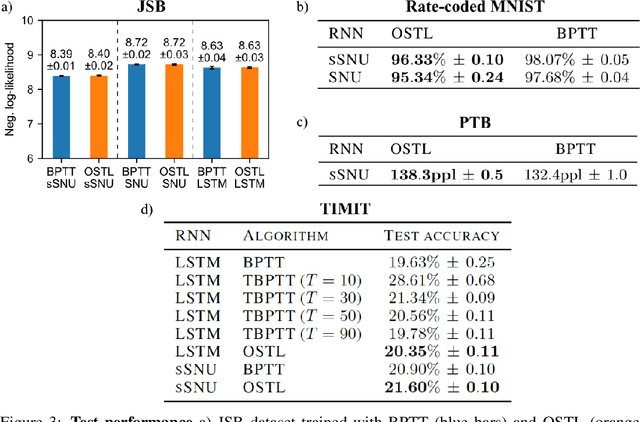
Biological neural networks are equipped with an inherent capability to continuously adapt through online learning. This aspect remains in stark contrast to learning with error backpropagation through time (BPTT) applied to recurrent neural networks (RNNs), or recently even to biologically-inspired spiking neural networks (SNNs), because the unrolling through time of BPTT leads to system-locking problems. Online learning has recently regained the attention of the research community, focusing either on approaches that approximate BPTT or on biologically-plausible schemes applied in SNNs. Here we present an alternative perspective that is based on a clear separation of spatial and temporal gradient components. Combined with insights from biology, we derive from first principles a novel online learning algorithm, called online spatio-temporal learning (OSTL), which is gradient-equivalent to BPTT for shallow networks. We apply OSTL to SNNs allowing them for the first time to be trained online with BPTT-equivalent gradients. In addition, the proposed formulation uncovers a class of SNN architectures trainable online at low complexity. Moreover, we extend OSTL to deep networks while maintaining its key characteristics. Besides SNNs, the generic form of OSTL is applicable to a wide range of network architectures, including networks comprising long short-term memory (LSTM) and gated recurrent units (GRU). We demonstrate the operation of our algorithm on various tasks from language modelling to speech recognition, and obtain results on par with the BPTT baselines. The proposed algorithm provides a framework for developing succinct and efficient online training approaches for SNNs and in general deep RNNs.
ESSOP: Efficient and Scalable Stochastic Outer Product Architecture for Deep Learning
Mar 25, 2020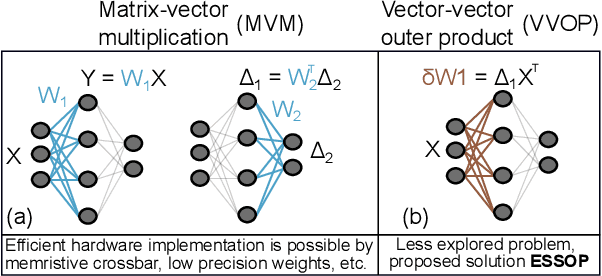
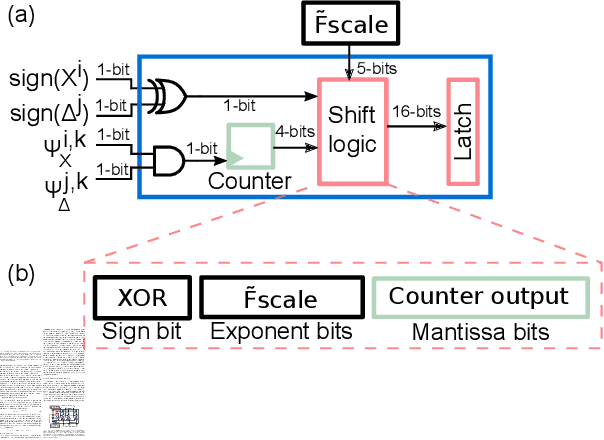
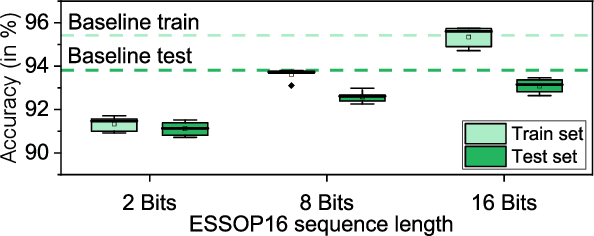
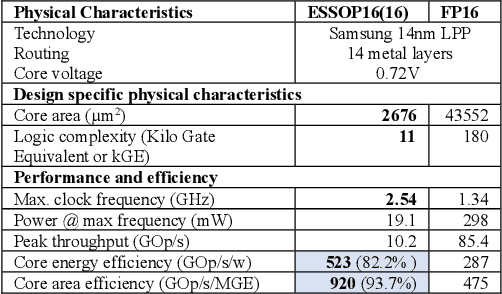
Deep neural networks (DNNs) have surpassed human-level accuracy in a variety of cognitive tasks but at the cost of significant memory/time requirements in DNN training. This limits their deployment in energy and memory limited applications that require real-time learning. Matrix-vector multiplications (MVM) and vector-vector outer product (VVOP) are the two most expensive operations associated with the training of DNNs. Strategies to improve the efficiency of MVM computation in hardware have been demonstrated with minimal impact on training accuracy. However, the VVOP computation remains a relatively less explored bottleneck even with the aforementioned strategies. Stochastic computing (SC) has been proposed to improve the efficiency of VVOP computation but on relatively shallow networks with bounded activation functions and floating-point (FP) scaling of activation gradients. In this paper, we propose ESSOP, an efficient and scalable stochastic outer product architecture based on the SC paradigm. We introduce efficient techniques to generalize SC for weight update computation in DNNs with the unbounded activation functions (e.g., ReLU), required by many state-of-the-art networks. Our architecture reduces the computational cost by re-using random numbers and replacing certain FP multiplication operations by bit shift scaling. We show that the ResNet-32 network with 33 convolution layers and a fully-connected layer can be trained with ESSOP on the CIFAR-10 dataset to achieve baseline comparable accuracy. Hardware design of ESSOP at 14nm technology node shows that, compared to a highly pipelined FP16 multiplier design, ESSOP is 82.2% and 93.7% better in energy and area efficiency respectively for outer product computation.
Compiling Neural Networks for a Computational Memory Accelerator
Mar 05, 2020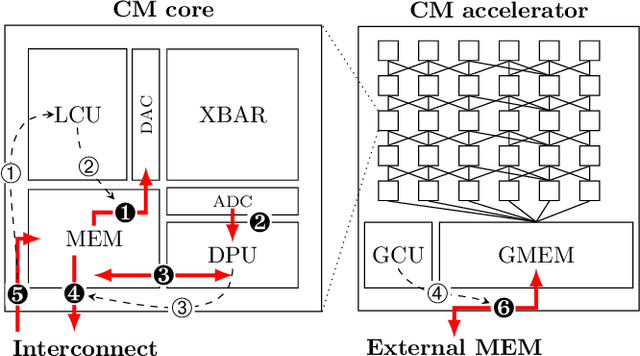

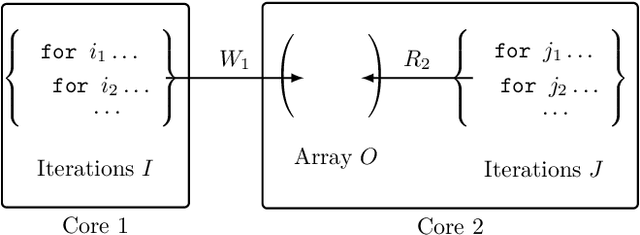
Computational memory (CM) is a promising approach for accelerating inference on neural networks (NN) by using enhanced memories that, in addition to storing data, allow computations on them. One of the main challenges of this approach is defining a hardware/software interface that allows a compiler to map NN models for efficient execution on the underlying CM accelerator. This is a non-trivial task because efficiency dictates that the CM accelerator is explicitly programmed as a dataflow engine where the execution of the different NN layers form a pipeline. In this paper, we present our work towards a software stack for executing ML models on such a multi-core CM accelerator. We describe an architecture for the hardware and software, and focus on the problem of implementing the appropriate control logic so that data dependencies are respected. We propose a solution to the latter that is based on polyhedral compilation.