 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESSOP: Efficient and Scalable Stochastic Outer Product Architecture for Deep Learning
Mar 25, 2020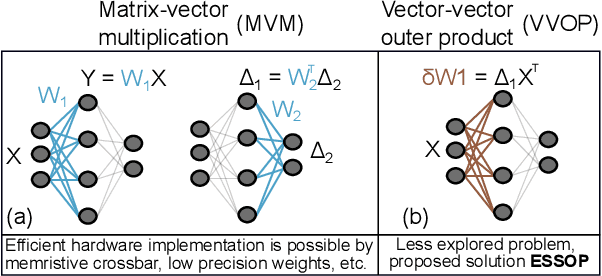
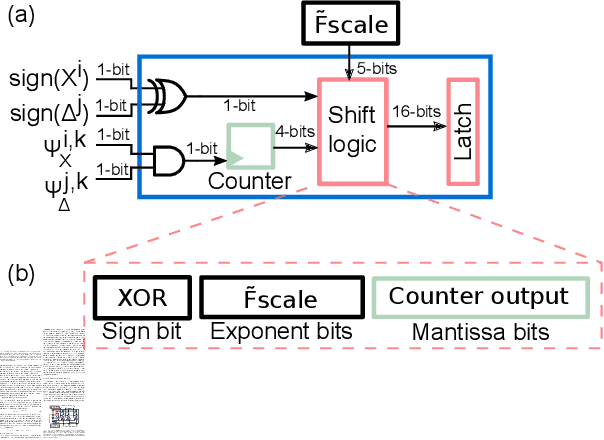
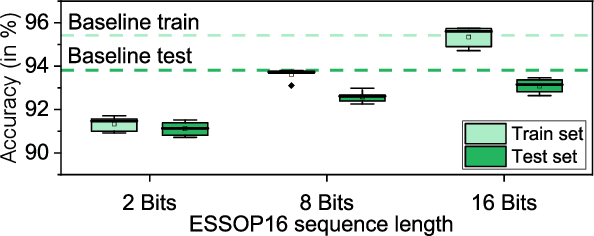
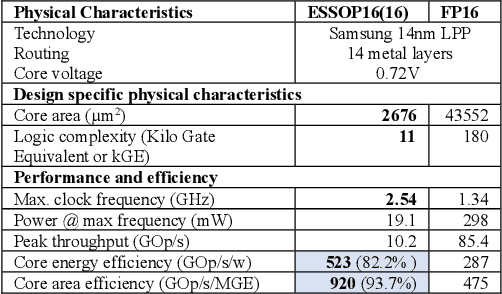
Deep neural networks (DNNs) have surpassed human-level accuracy in a variety of cognitive tasks but at the cost of significant memory/time requirements in DNN training. This limits their deployment in energy and memory limited applications that require real-time learning. Matrix-vector multiplications (MVM) and vector-vector outer product (VVOP) are the two most expensive operations associated with the training of DNNs. Strategies to improve the efficiency of MVM computation in hardware have been demonstrated with minimal impact on training accuracy. However, the VVOP computation remains a relatively less explored bottleneck even with the aforementioned strategies. Stochastic computing (SC) has been proposed to improve the efficiency of VVOP computation but on relatively shallow networks with bounded activation functions and floating-point (FP) scaling of activation gradients. In this paper, we propose ESSOP, an efficient and scalable stochastic outer product architecture based on the SC paradigm. We introduce efficient techniques to generalize SC for weight update computation in DNNs with the unbounded activation functions (e.g., ReLU), required by many state-of-the-art networks. Our architecture reduces the computational cost by re-using random numbers and replacing certain FP multiplication operations by bit shift scaling. We show that the ResNet-32 network with 33 convolution layers and a fully-connected layer can be trained with ESSOP on the CIFAR-10 dataset to achieve baseline comparable accuracy. Hardware design of ESSOP at 14nm technology node shows that, compared to a highly pipelined FP16 multiplier design, ESSOP is 82.2% and 93.7% better in energy and area efficiency respectively for outer product computation.