 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaDA: Training-free recipe for Decoding with Adaptive KV Cache Compression and Mean-centering
Jun 05, 2025The key-value (KV) cache in transformer models is a critical component for efficient decoding or inference, yet its memory demands scale poorly with sequence length, posing a major challenge for scalable deployment of large language models. Among several approaches to KV cache compression, quantization of key and value activations has been widely explored. Most KV cache quantization methods still need to manage sparse and noncontiguous outliers separately. To address this, we introduce TaDA, a training-free recipe for KV cache compression with quantization precision that adapts to error sensitivity across layers and a mean centering to eliminate separate outlier handling. Our approach yields substantial accuracy improvements for multiple models supporting various context lengths. Moreover, our approach does not need to separately manage outlier elements -- a persistent hurdle in most traditional quantization methods. Experiments on standard benchmarks demonstrate that our technique reduces KV cache memory footprint to 27% of the original 16-bit baseline while achieving comparable accuracy. Our method paves the way for scalable and high-performance reasoning in language models by potentially enabling inference for longer context length models, reasoning models, and longer chain of thoughts.
QCQA: Quality and Capacity-aware grouped Query Attention
Jun 08, 2024



Excessive memory requirements of key and value features (KV-cache) present significant challenges in the autoregressive inference of large language models (LLMs), restricting both the speed and length of text generation. Approaches such as Multi-Query Attention (MQA) and Grouped Query Attention (GQA) mitigate these challenges by grouping query heads and consequently reducing the number of corresponding key and value heads. However, MQA and GQA decrease the KV-cache size requirements at the expense of LLM accuracy (quality of text generation). These methods do not ensure an optimal tradeoff between KV-cache size and text generation quality due to the absence of quality-aware grouping of query heads. To address this issue, we propose Quality and Capacity-Aware Grouped Query Attention (QCQA), which identifies optimal query head groupings using an evolutionary algorithm with a computationally efficient and inexpensive fitness function. We demonstrate that QCQA achieves a significantly better tradeoff between KV-cache capacity and LLM accuracy compared to GQA. For the Llama2 $7\,$B model, QCQA achieves $\mathbf{20}$\% higher accuracy than GQA with similar KV-cache size requirements in the absence of fine-tuning. After fine-tuning both QCQA and GQA, for a similar KV-cache size, QCQA provides $\mathbf{10.55}\,$\% higher accuracy than GQA. Furthermore, QCQA requires $40\,$\% less KV-cache size than GQA to attain similar accuracy. The proposed quality and capacity-aware grouping of query heads can serve as a new paradigm for KV-cache optimization in autoregressive LLM inference.
Towards Joint Optimization for DNN Architecture and Configuration for Compute-In-Memory Hardware
Feb 19, 2024With the recent growth in demand for large-scale deep neural networks, compute in-memory (CiM) has come up as a prominent solution to alleviate bandwidth and on-chip interconnect bottlenecks that constrain Von-Neuman architectures. However, the construction of CiM hardware poses a challenge as any specific memory hierarchy in terms of cache sizes and memory bandwidth at different interfaces may not be ideally matched to any neural network's attributes such as tensor dimension and arithmetic intensity, thus leading to suboptimal and under-performing systems. Despite the success of neural architecture search (NAS) techniques in yielding efficient sub-networks for a given hardware metric budget (e.g., DNN execution time or latency), it assumes the hardware configuration to be frozen, often yielding sub-optimal sub-networks for a given budget. In this paper, we present CiMNet, a framework that jointly searches for optimal sub-networks and hardware configurations for CiM architectures creating a Pareto optimal frontier of downstream task accuracy and execution metrics (e.g., latency). The proposed framework can comprehend the complex interplay between a sub-network's performance and the CiM hardware configuration choices including bandwidth, processing element size, and memory size. Exhaustive experiments on different model architectures from both CNN and Transformer families demonstrate the efficacy of the CiMNet in finding co-optimized sub-networks and CiM hardware configurations. Specifically, for similar ImageNet classification accuracy as baseline ViT-B, optimizing only the model architecture increases performance (or reduces workload execution time) by 1.7x while optimizing for both the model architecture and hardware configuration increases it by 3.1x.
Hybrid In-memory Computing Architecture for the Training of Deep Neural Networks
Feb 10, 2021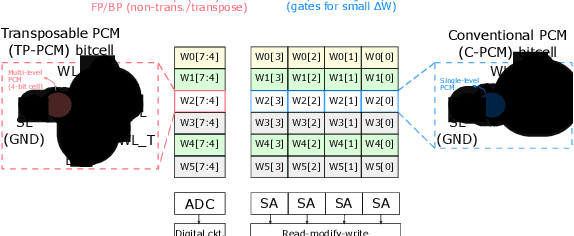



The cost involved in training deep neural networks (DNNs) on von-Neumann architectures has motivated the development of novel solutions for efficient DNN training accelerators. We propose a hybrid in-memory computing (HIC) architecture for the training of DNNs on hardware accelerators that results in memory-efficient inference and outperforms baseline software accuracy in benchmark tasks. We introduce a weight representation technique that exploits both binary and multi-level phase-change memory (PCM) devices, and this leads to a memory-efficient inference accelerator. Unlike previous in-memory computing-based implementations, we use a low precision weight update accumulator that results in more memory savings. We trained the ResNet-32 network to classify CIFAR-10 images using HIC. For a comparable model size, HIC-based training outperforms baseline network, trained in floating-point 32-bit (FP32) precision, by leveraging appropriate network width multiplier. Furthermore, we observe that HIC-based training results in about 50% less inference model size to achieve baseline comparable accuracy. We also show that the temporal drift in PCM devices has a negligible effect on post-training inference accuracy for extended periods (year). Finally, our simulations indicate HIC-based training naturally ensures that the number of write-erase cycles seen by the devices is a small fraction of the endurance limit of PCM, demonstrating the feasibility of this architecture for achieving hardware platforms that can learn in the field.
ESSOP: Efficient and Scalable Stochastic Outer Product Architecture for Deep Learning
Mar 25, 2020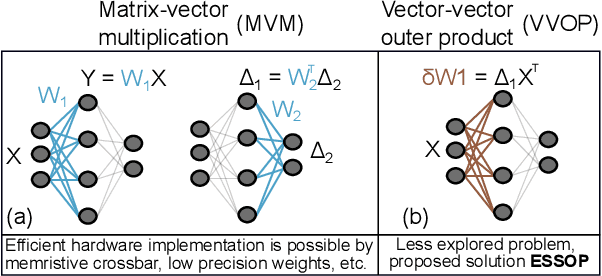
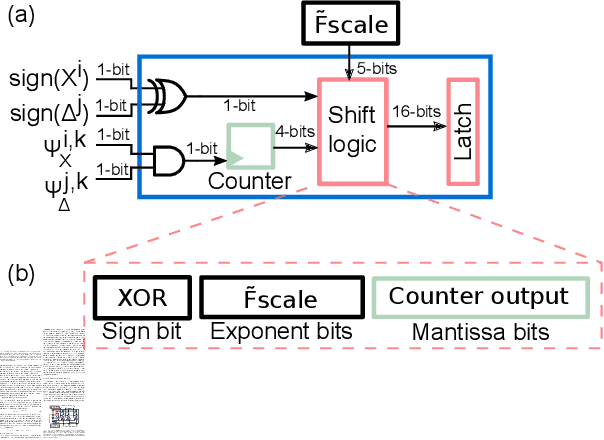
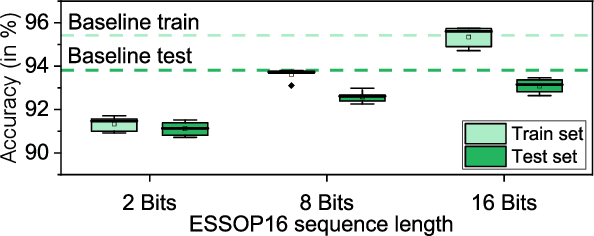
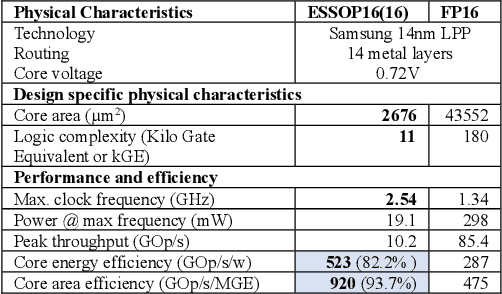
Deep neural networks (DNNs) have surpassed human-level accuracy in a variety of cognitive tasks but at the cost of significant memory/time requirements in DNN training. This limits their deployment in energy and memory limited applications that require real-time learning. Matrix-vector multiplications (MVM) and vector-vector outer product (VVOP) are the two most expensive operations associated with the training of DNNs. Strategies to improve the efficiency of MVM computation in hardware have been demonstrated with minimal impact on training accuracy. However, the VVOP computation remains a relatively less explored bottleneck even with the aforementioned strategies. Stochastic computing (SC) has been proposed to improve the efficiency of VVOP computation but on relatively shallow networks with bounded activation functions and floating-point (FP) scaling of activation gradients. In this paper, we propose ESSOP, an efficient and scalable stochastic outer product architecture based on the SC paradigm. We introduce efficient techniques to generalize SC for weight update computation in DNNs with the unbounded activation functions (e.g., ReLU), required by many state-of-the-art networks. Our architecture reduces the computational cost by re-using random numbers and replacing certain FP multiplication operations by bit shift scaling. We show that the ResNet-32 network with 33 convolution layers and a fully-connected layer can be trained with ESSOP on the CIFAR-10 dataset to achieve baseline comparable accuracy. Hardware design of ESSOP at 14nm technology node shows that, compared to a highly pipelined FP16 multiplier design, ESSOP is 82.2% and 93.7% better in energy and area efficiency respectively for outer product computation.