 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Joint Optimization for DNN Architecture and Configuration for Compute-In-Memory Hardware
Feb 19, 2024With the recent growth in demand for large-scale deep neural networks, compute in-memory (CiM) has come up as a prominent solution to alleviate bandwidth and on-chip interconnect bottlenecks that constrain Von-Neuman architectures. However, the construction of CiM hardware poses a challenge as any specific memory hierarchy in terms of cache sizes and memory bandwidth at different interfaces may not be ideally matched to any neural network's attributes such as tensor dimension and arithmetic intensity, thus leading to suboptimal and under-performing systems. Despite the success of neural architecture search (NAS) techniques in yielding efficient sub-networks for a given hardware metric budget (e.g., DNN execution time or latency), it assumes the hardware configuration to be frozen, often yielding sub-optimal sub-networks for a given budget. In this paper, we present CiMNet, a framework that jointly searches for optimal sub-networks and hardware configurations for CiM architectures creating a Pareto optimal frontier of downstream task accuracy and execution metrics (e.g., latency). The proposed framework can comprehend the complex interplay between a sub-network's performance and the CiM hardware configuration choices including bandwidth, processing element size, and memory size. Exhaustive experiments on different model architectures from both CNN and Transformer families demonstrate the efficacy of the CiMNet in finding co-optimized sub-networks and CiM hardware configurations. Specifically, for similar ImageNet classification accuracy as baseline ViT-B, optimizing only the model architecture increases performance (or reduces workload execution time) by 1.7x while optimizing for both the model architecture and hardware configuration increases it by 3.1x.
Robust 3D Scene Segmentation through Hierarchical and Learnable Part-Fusion
Nov 16, 2021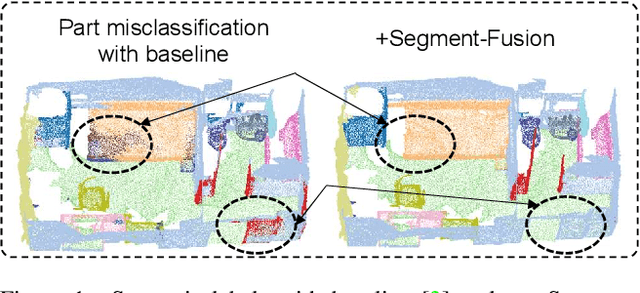
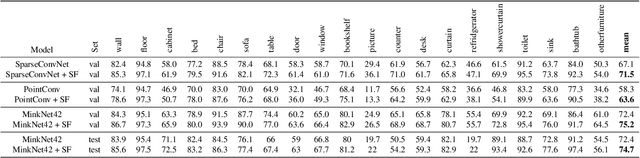
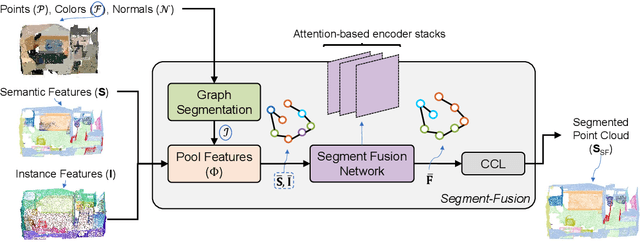
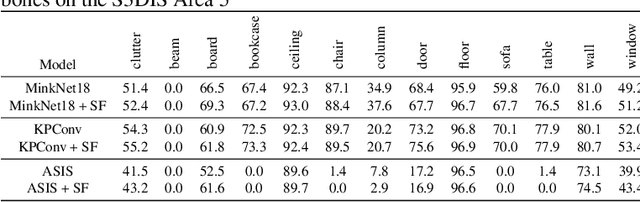
3D semantic segmentation is a fundamental building block for several scene understanding applications such as autonomous driving, robotics and AR/VR. Several state-of-the-art semantic segmentation models suffer from the part misclassification problem, wherein parts of the same object are labelled incorrectly. Previous methods have utilized hierarchical, iterative methods to fuse semantic and instance information, but they lack learnability in context fusion, and are computationally complex and heuristic driven. This paper presents Segment-Fusion, a novel attention-based method for hierarchical fusion of semantic and instance information to address the part misclassifications. The presented method includes a graph segmentation algorithm for grouping points into segments that pools point-wise features into segment-wise features, a learnable attention-based network to fuse these segments based on their semantic and instance features, and followed by a simple yet effective connected component labelling algorithm to convert segment features to instance labels. Segment-Fusion can be flexibly employed with any network architecture for semantic/instance segmentation. It improves the qualitative and quantitative performance of several semantic segmentation backbones by upto 5% when evaluated on the ScanNet and S3DIS datasets.