 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMesh2NeRF: Direct Mesh Supervision for Neural Radiance Field Representation and Generation
Mar 28, 2024We present Mesh2NeRF, an approach to derive ground-truth radiance fields from textured meshes for 3D generation tasks. Many 3D generative approaches represent 3D scenes as radiance fields for training. Their ground-truth radiance fields are usually fitted from multi-view renderings from a large-scale synthetic 3D dataset, which often results in artifacts due to occlusions or under-fitting issues. In Mesh2NeRF, we propose an analytic solution to directly obtain ground-truth radiance fields from 3D meshes, characterizing the density field with an occupancy function featuring a defined surface thickness, and determining view-dependent color through a reflection function considering both the mesh and environment lighting. Mesh2NeRF extracts accurate radiance fields which provides direct supervision for training generative NeRFs and single scene representation. We validate the effectiveness of Mesh2NeRF across various tasks, achieving a noteworthy 3.12dB improvement in PSNR for view synthesis in single scene representation on the ABO dataset, a 0.69 PSNR enhancement in the single-view conditional generation of ShapeNet Cars, and notably improved mesh extraction from NeRF in the unconditional generation of Objaverse Mugs.
Objects With Lighting: A Real-World Dataset for Evaluating Reconstruction and Rendering for Object Relighting
Jan 17, 2024



Reconstructing an object from photos and placing it virtually in a new environment goes beyond the standard novel view synthesis task as the appearance of the object has to not only adapt to the novel viewpoint but also to the new lighting conditions and yet evaluations of inverse rendering methods rely on novel view synthesis data or simplistic synthetic datasets for quantitative analysis. This work presents a real-world dataset for measuring the reconstruction and rendering of objects for relighting. To this end, we capture the environment lighting and ground truth images of the same objects in multiple environments allowing to reconstruct the objects from images taken in one environment and quantify the quality of the rendered views for the unseen lighting environments. Further, we introduce a simple baseline composed of off-the-shelf methods and test several state-of-the-art methods on the relighting task and show that novel view synthesis is not a reliable proxy to measure performance. Code and dataset are available at https://github.com/isl-org/objects-with-lighting .
Guaranteed Conservation of Momentum for Learning Particle-based Fluid Dynamics
Oct 12, 2022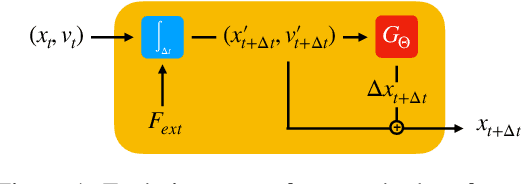
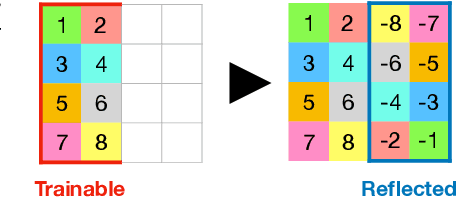
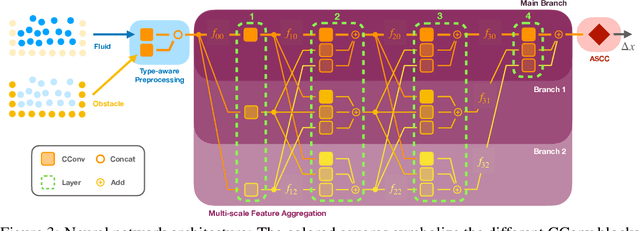
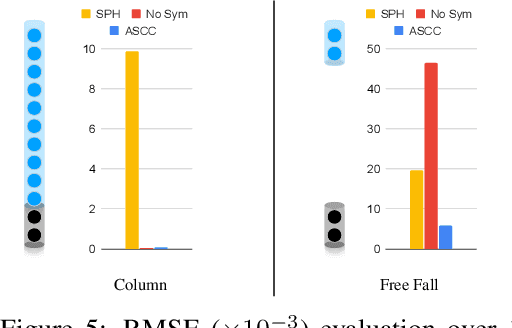
We present a novel method for guaranteeing linear momentum in learned physics simulations. Unlike existing methods, we enforce conservation of momentum with a hard constraint, which we realize via antisymmetrical continuous convolutional layers. We combine these strict constraints with a hierarchical network architecture, a carefully constructed resampling scheme, and a training approach for temporal coherence. In combination, the proposed method allows us to increase the physical accuracy of the learned simulator substantially. In addition, the induced physical bias leads to significantly better generalization performance and makes our method more reliable in unseen test cases. We evaluate our method on a range of different, challenging fluid scenarios. Among others, we demonstrate that our approach generalizes to new scenarios with up to one million particles. Our results show that the proposed algorithm can learn complex dynamics while outperforming existing approaches in generalization and training performance. An implementation of our approach is available at https://github.com/tum-pbs/DMCF.
Robust 3D Scene Segmentation through Hierarchical and Learnable Part-Fusion
Nov 16, 2021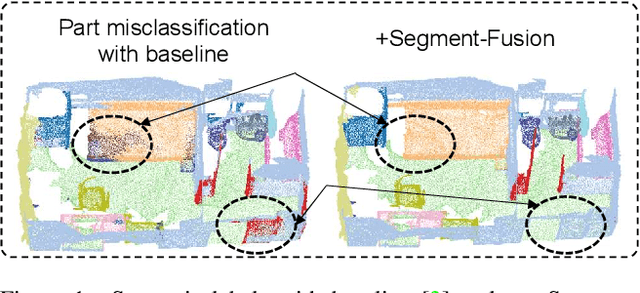
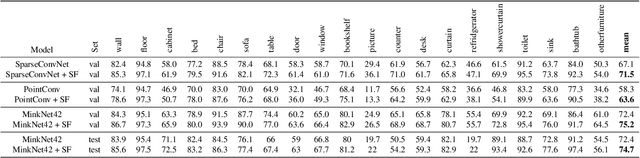
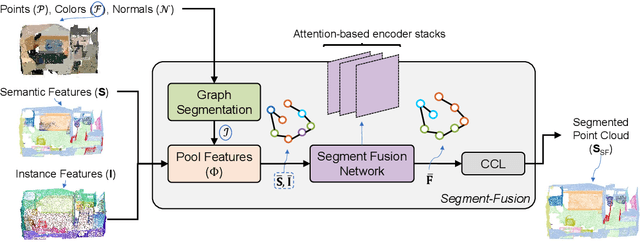
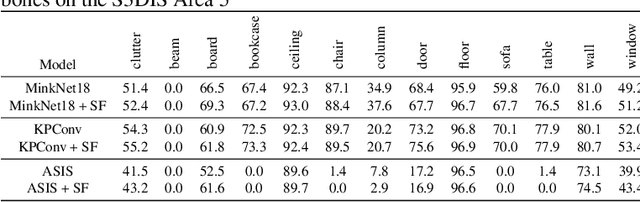
3D semantic segmentation is a fundamental building block for several scene understanding applications such as autonomous driving, robotics and AR/VR. Several state-of-the-art semantic segmentation models suffer from the part misclassification problem, wherein parts of the same object are labelled incorrectly. Previous methods have utilized hierarchical, iterative methods to fuse semantic and instance information, but they lack learnability in context fusion, and are computationally complex and heuristic driven. This paper presents Segment-Fusion, a novel attention-based method for hierarchical fusion of semantic and instance information to address the part misclassifications. The presented method includes a graph segmentation algorithm for grouping points into segments that pools point-wise features into segment-wise features, a learnable attention-based network to fuse these segments based on their semantic and instance features, and followed by a simple yet effective connected component labelling algorithm to convert segment features to instance labels. Segment-Fusion can be flexibly employed with any network architecture for semantic/instance segmentation. It improves the qualitative and quantitative performance of several semantic segmentation backbones by upto 5% when evaluated on the ScanNet and S3DIS datasets.
CAM-Convs: Camera-Aware Multi-Scale Convolutions for Single-View Depth
Apr 03, 2019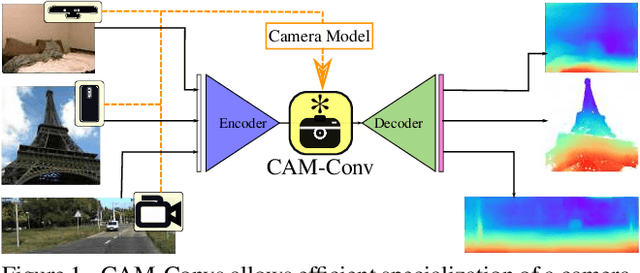

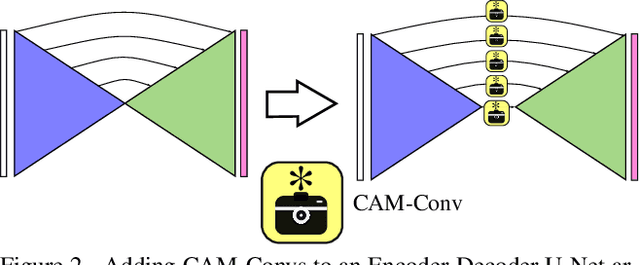
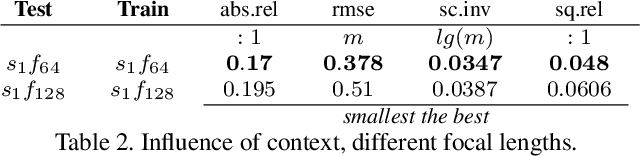
Single-view depth estimation suffers from the problem that a network trained on images from one camera does not generalize to images taken with a different camera model. Thus, changing the camera model requires collecting an entirely new training dataset. In this work, we propose a new type of convolution that can take the camera parameters into account, thus allowing neural networks to learn calibration-aware patterns. Experiments confirm that this improves the generalization capabilities of depth prediction networks considerably, and clearly outperforms the state of the art when the train and test images are acquired with different cameras.
DeepTAM: Deep Tracking and Mapping
Aug 07, 2018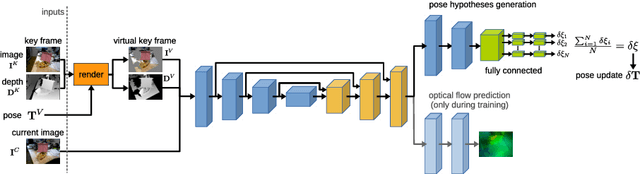

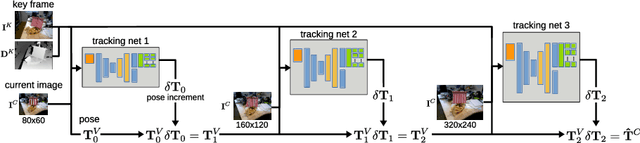

We present a system for keyframe-based dense camera tracking and depth map estimation that is entirely learned. For tracking, we estimate small pose increments between the current camera image and a synthetic viewpoint. This significantly simplifies the learning problem and alleviates the dataset bias for camera motions. Further, we show that generating a large number of pose hypotheses leads to more accurate predictions. For mapping, we accumulate information in a cost volume centered at the current depth estimate. The mapping network then combines the cost volume and the keyframe image to update the depth prediction, thereby effectively making use of depth measurements and image-based priors. Our approach yields state-of-the-art results with few images and is robust with respect to noisy camera poses. We demonstrate that the performance of our 6 DOF tracking competes with RGB-D tracking algorithms. We compare favorably against strong classic and deep learning powered dense depth algorithms.
DeMoN: Depth and Motion Network for Learning Monocular Stereo
Apr 11, 2017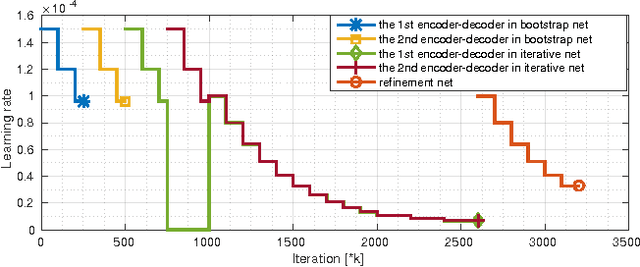


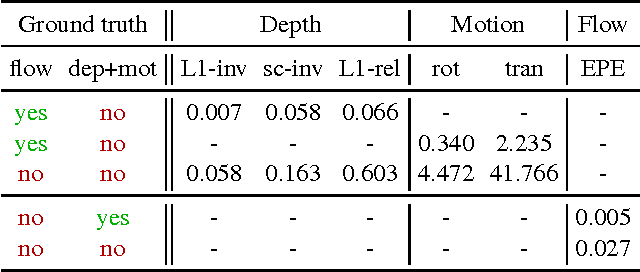
In this paper we formulate structure from motion as a learning problem. We train a convolutional network end-to-end to compute depth and camera motion from successive, unconstrained image pairs. The architecture is composed of multiple stacked encoder-decoder networks, the core part being an iterative network that is able to improve its own predictions. The network estimates not only depth and motion, but additionally surface normals, optical flow between the images and confidence of the matching. A crucial component of the approach is a training loss based on spatial relative differences. Compared to traditional two-frame structure from motion methods, results are more accurate and more robust. In contrast to the popular depth-from-single-image networks, DeMoN learns the concept of matching and, thus, better generalizes to structures not seen during training.