 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePix2NPHM: Learning to Regress NPHM Reconstructions From a Single Image
Dec 19, 2025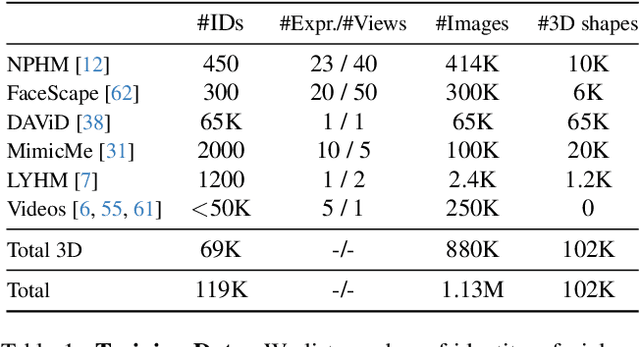

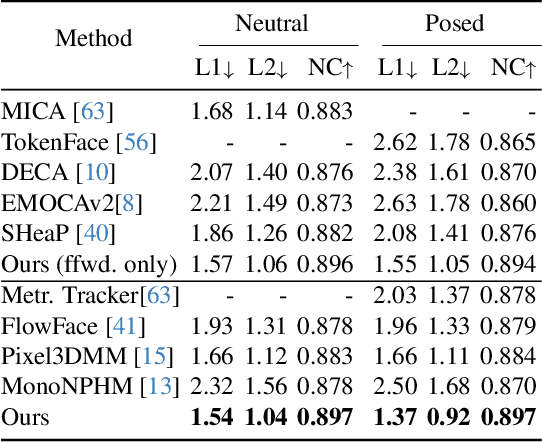
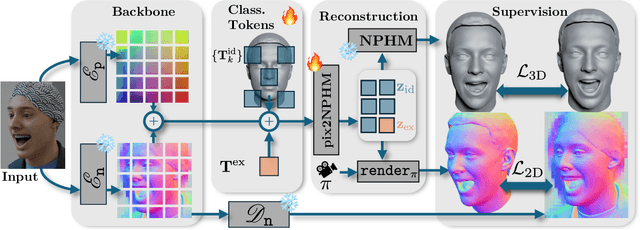
Neural Parametric Head Models (NPHMs) are a recent advancement over mesh-based 3d morphable models (3DMMs) to facilitate high-fidelity geometric detail. However, fitting NPHMs to visual inputs is notoriously challenging due to the expressive nature of their underlying latent space. To this end, we propose Pix2NPHM, a vision transformer (ViT) network that directly regresses NPHM parameters, given a single image as input. Compared to existing approaches, the neural parametric space allows our method to reconstruct more recognizable facial geometry and accurate facial expressions. For broad generalization, we exploit domain-specific ViTs as backbones, which are pretrained on geometric prediction tasks. We train Pix2NPHM on a mixture of 3D data, including a total of over 100K NPHM registrations that enable direct supervision in SDF space, and large-scale 2D video datasets, for which normal estimates serve as pseudo ground truth geometry. Pix2NPHM not only allows for 3D reconstructions at interactive frame rates, it is also possible to improve geometric fidelity by a subsequent inference-time optimization against estimated surface normals and canonical point maps. As a result, we achieve unprecedented face reconstruction quality that can run at scale on in-the-wild data.
FlexAvatar: Learning Complete 3D Head Avatars with Partial Supervision
Dec 17, 2025We introduce FlexAvatar, a method for creating high-quality and complete 3D head avatars from a single image. A core challenge lies in the limited availability of multi-view data and the tendency of monocular training to yield incomplete 3D head reconstructions. We identify the root cause of this issue as the entanglement between driving signal and target viewpoint when learning from monocular videos. To address this, we propose a transformer-based 3D portrait animation model with learnable data source tokens, so-called bias sinks, which enables unified training across monocular and multi-view datasets. This design leverages the strengths of both data sources during inference: strong generalization from monocular data and full 3D completeness from multi-view supervision. Furthermore, our training procedure yields a smooth latent avatar space that facilitates identity interpolation and flexible fitting to an arbitrary number of input observations. In extensive evaluations on single-view, few-shot, and monocular avatar creation tasks, we verify the efficacy of FlexAvatar. Many existing methods struggle with view extrapolation while FlexAvatar generates complete 3D head avatars with realistic facial animations. Website: https://tobias-kirschstein.github.io/flexavatar/
Intrinsic Image Fusion for Multi-View 3D Material Reconstruction
Dec 15, 2025We introduce Intrinsic Image Fusion, a method that reconstructs high-quality physically based materials from multi-view images. Material reconstruction is highly underconstrained and typically relies on analysis-by-synthesis, which requires expensive and noisy path tracing. To better constrain the optimization, we incorporate single-view priors into the reconstruction process. We leverage a diffusion-based material estimator that produces multiple, but often inconsistent, candidate decompositions per view. To reduce the inconsistency, we fit an explicit low-dimensional parametric function to the predictions. We then propose a robust optimization framework using soft per-view prediction selection together with confidence-based soft multi-view inlier set to fuse the most consistent predictions of the most confident views into a consistent parametric material space. Finally, we use inverse path tracing to optimize for the low-dimensional parameters. Our results outperform state-of-the-art methods in material disentanglement on both synthetic and real scenes, producing sharp and clean reconstructions suitable for high-quality relighting.
FactorPortrait: Controllable Portrait Animation via Disentangled Expression, Pose, and Viewpoint
Dec 12, 2025We introduce FactorPortrait, a video diffusion method for controllable portrait animation that enables lifelike synthesis from disentangled control signals of facial expressions, head movement, and camera viewpoints. Given a single portrait image, a driving video, and camera trajectories, our method animates the portrait by transferring facial expressions and head movements from the driving video while simultaneously enabling novel view synthesis from arbitrary viewpoints. We utilize a pre-trained image encoder to extract facial expression latents from the driving video as control signals for animation generation. Such latents implicitly capture nuanced facial expression dynamics with identity and pose information disentangled, and they are efficiently injected into the video diffusion transformer through our proposed expression controller. For camera and head pose control, we employ Plücker ray maps and normal maps rendered from 3D body mesh tracking. To train our model, we curate a large-scale synthetic dataset containing diverse combinations of camera viewpoints, head poses, and facial expression dynamics. Extensive experiments demonstrate that our method outperforms existing approaches in realism, expressiveness, control accuracy, and view consistency.
MeshRipple: Structured Autoregressive Generation of Artist-Meshes
Dec 09, 2025Meshes serve as a primary representation for 3D assets. Autoregressive mesh generators serialize faces into sequences and train on truncated segments with sliding-window inference to cope with memory limits. However, this mismatch breaks long-range geometric dependencies, producing holes and fragmented components. To address this critical limitation, we introduce MeshRipple, which expands a mesh outward from an active generation frontier, akin to a ripple on a surface. MeshRipple rests on three key innovations: a frontier-aware BFS tokenization that aligns the generation order with surface topology; an expansive prediction strategy that maintains coherent, connected surface growth; and a sparse-attention global memory that provides an effectively unbounded receptive field to resolve long-range topological dependencies. This integrated design enables MeshRipple to generate meshes with high surface fidelity and topological completeness, outperforming strong recent baselines.
HairGS: Hair Strand Reconstruction based on 3D Gaussian Splatting
Sep 09, 2025Human hair reconstruction is a challenging problem in computer vision, with growing importance for applications in virtual reality and digital human modeling. Recent advances in 3D Gaussians Splatting (3DGS) provide efficient and explicit scene representations that naturally align with the structure of hair strands. In this work, we extend the 3DGS framework to enable strand-level hair geometry reconstruction from multi-view images. Our multi-stage pipeline first reconstructs detailed hair geometry using a differentiable Gaussian rasterizer, then merges individual Gaussian segments into coherent strands through a novel merging scheme, and finally refines and grows the strands under photometric supervision. While existing methods typically evaluate reconstruction quality at the geometric level, they often neglect the connectivity and topology of hair strands. To address this, we propose a new evaluation metric that serves as a proxy for assessing topological accuracy in strand reconstruction. Extensive experiments on both synthetic and real-world datasets demonstrate that our method robustly handles a wide range of hairstyles and achieves efficient reconstruction, typically completing within one hour. The project page can be found at: https://yimin-pan.github.io/hair-gs/
LiteReality: Graphics-Ready 3D Scene Reconstruction from RGB-D Scans
Jul 03, 2025


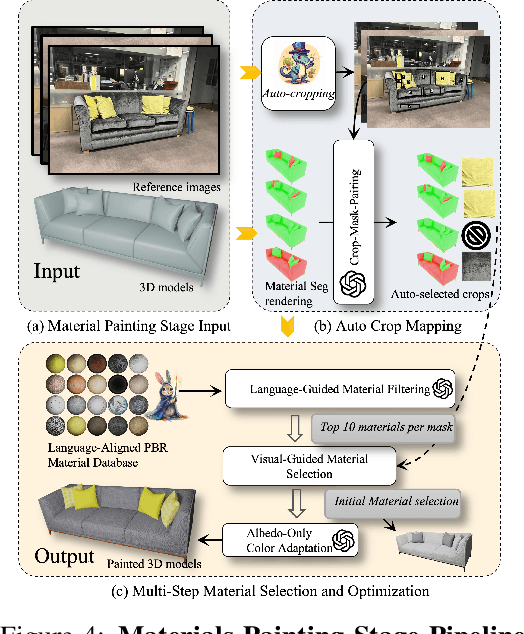
We propose LiteReality, a novel pipeline that converts RGB-D scans of indoor environments into compact, realistic, and interactive 3D virtual replicas. LiteReality not only reconstructs scenes that visually resemble reality but also supports key features essential for graphics pipelines -- such as object individuality, articulation, high-quality physically based rendering materials, and physically based interaction. At its core, LiteReality first performs scene understanding and parses the results into a coherent 3D layout and objects with the help of a structured scene graph. It then reconstructs the scene by retrieving the most visually similar 3D artist-crafted models from a curated asset database. Next, the Material Painting module enhances realism by recovering high-quality, spatially varying materials. Finally, the reconstructed scene is integrated into a simulation engine with basic physical properties to enable interactive behavior. The resulting scenes are compact, editable, and fully compatible with standard graphics pipelines, making them suitable for applications in AR/VR, gaming, robotics, and digital twins. In addition, LiteReality introduces a training-free object retrieval module that achieves state-of-the-art similarity performance on the Scan2CAD benchmark, along with a robust material painting module capable of transferring appearances from images of any style to 3D assets -- even under severe misalignment, occlusion, and poor lighting. We demonstrate the effectiveness of LiteReality on both real-life scans and public datasets. Project page: https://litereality.github.io; Video: https://www.youtube.com/watch?v=ecK9m3LXg2c
TUM2TWIN: Introducing the Large-Scale Multimodal Urban Digital Twin Benchmark Dataset
May 13, 2025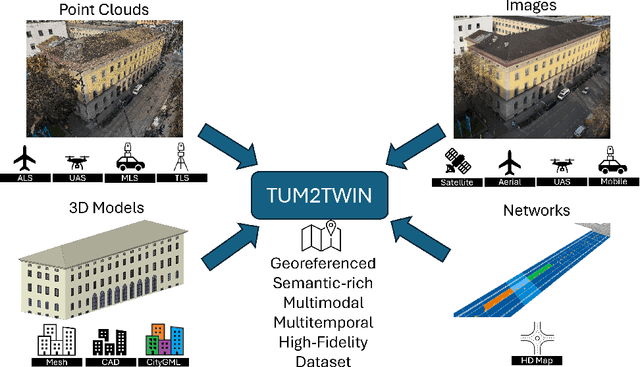
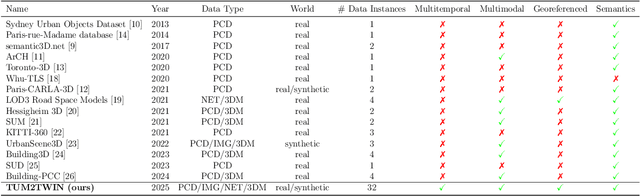

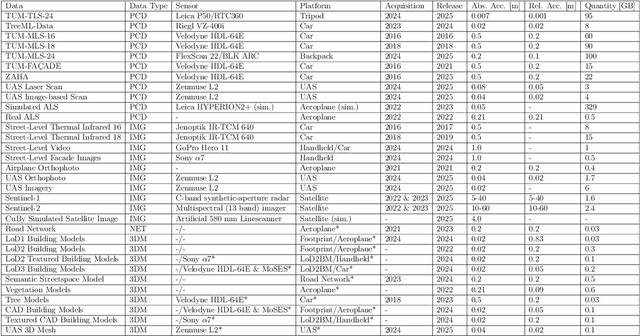
Urban Digital Twins (UDTs) have become essential for managing cities and integrating complex, heterogeneous data from diverse sources. Creating UDTs involves challenges at multiple process stages, including acquiring accurate 3D source data, reconstructing high-fidelity 3D models, maintaining models' updates, and ensuring seamless interoperability to downstream tasks. Current datasets are usually limited to one part of the processing chain, hampering comprehensive UDTs validation. To address these challenges, we introduce the first comprehensive multimodal Urban Digital Twin benchmark dataset: TUM2TWIN. This dataset includes georeferenced, semantically aligned 3D models and networks along with various terrestrial, mobile, aerial, and satellite observations boasting 32 data subsets over roughly 100,000 $m^2$ and currently 767 GB of data. By ensuring georeferenced indoor-outdoor acquisition, high accuracy, and multimodal data integration, the benchmark supports robust analysis of sensors and the development of advanced reconstruction methods. Additionally, we explore downstream tasks demonstrating the potential of TUM2TWIN, including novel view synthesis of NeRF and Gaussian Splatting, solar potential analysis, point cloud semantic segmentation, and LoD3 building reconstruction. We are convinced this contribution lays a foundation for overcoming current limitations in UDT creation, fostering new research directions and practical solutions for smarter, data-driven urban environments. The project is available under: https://tum2t.win
QuickSplat: Fast 3D Surface Reconstruction via Learned Gaussian Initialization
May 08, 2025Surface reconstruction is fundamental to computer vision and graphics, enabling applications in 3D modeling, mixed reality, robotics, and more. Existing approaches based on volumetric rendering obtain promising results, but optimize on a per-scene basis, resulting in a slow optimization that can struggle to model under-observed or textureless regions. We introduce QuickSplat, which learns data-driven priors to generate dense initializations for 2D gaussian splatting optimization of large-scale indoor scenes. This provides a strong starting point for the reconstruction, which accelerates the convergence of the optimization and improves the geometry of flat wall structures. We further learn to jointly estimate the densification and update of the scene parameters during each iteration; our proposed densifier network predicts new Gaussians based on the rendering gradients of existing ones, removing the needs of heuristics for densification. Extensive experiments on large-scale indoor scene reconstruction demonstrate the superiority of our data-driven optimization. Concretely, we accelerate runtime by 8x, while decreasing depth errors by up to 48% in comparison to state of the art methods.
Pixel3DMM: Versatile Screen-Space Priors for Single-Image 3D Face Reconstruction
May 01, 2025We address the 3D reconstruction of human faces from a single RGB image. To this end, we propose Pixel3DMM, a set of highly-generalized vision transformers which predict per-pixel geometric cues in order to constrain the optimization of a 3D morphable face model (3DMM). We exploit the latent features of the DINO foundation model, and introduce a tailored surface normal and uv-coordinate prediction head. We train our model by registering three high-quality 3D face datasets against the FLAME mesh topology, which results in a total of over 1,000 identities and 976K images. For 3D face reconstruction, we propose a FLAME fitting opitmization that solves for the 3DMM parameters from the uv-coordinate and normal estimates. To evaluate our method, we introduce a new benchmark for single-image face reconstruction, which features high diversity facial expressions, viewing angles, and ethnicities. Crucially, our benchmark is the first to evaluate both posed and neutral facial geometry. Ultimately, our method outperforms the most competitive baselines by over 15% in terms of geometric accuracy for posed facial expressions.