 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrueCity: Real and Simulated Urban Data for Cross-Domain 3D Scene Understanding
Nov 10, 2025
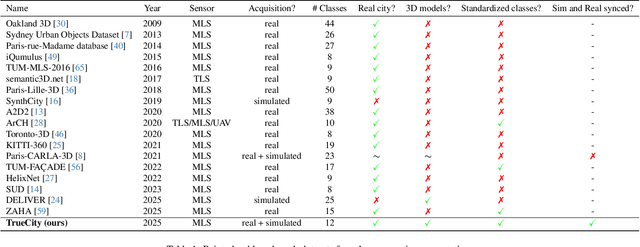
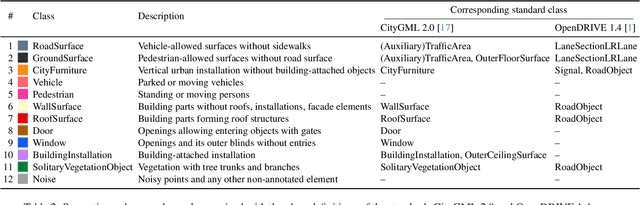
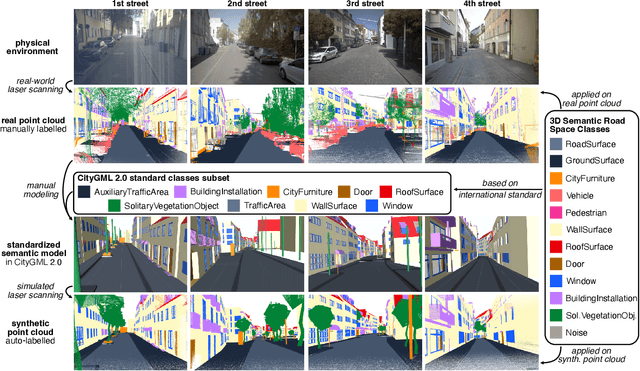
3D semantic scene understanding remains a long-standing challenge in the 3D computer vision community. One of the key issues pertains to limited real-world annotated data to facilitate generalizable models. The common practice to tackle this issue is to simulate new data. Although synthetic datasets offer scalability and perfect labels, their designer-crafted scenes fail to capture real-world complexity and sensor noise, resulting in a synthetic-to-real domain gap. Moreover, no benchmark provides synchronized real and simulated point clouds for segmentation-oriented domain shift analysis. We introduce TrueCity, the first urban semantic segmentation benchmark with cm-accurate annotated real-world point clouds, semantic 3D city models, and annotated simulated point clouds representing the same city. TrueCity proposes segmentation classes aligned with international 3D city modeling standards, enabling consistent evaluation of synthetic-to-real gap. Our extensive experiments on common baselines quantify domain shift and highlight strategies for exploiting synthetic data to enhance real-world 3D scene understanding. We are convinced that the TrueCity dataset will foster further development of sim-to-real gap quantification and enable generalizable data-driven models. The data, code, and 3D models are available online: https://tum-gis.github.io/TrueCity/
Mind the Domain Gap: Measuring the Domain Gap Between Real-World and Synthetic Point Clouds for Automated Driving Development
May 23, 2025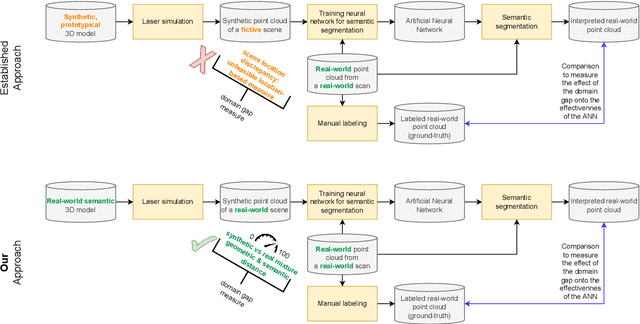

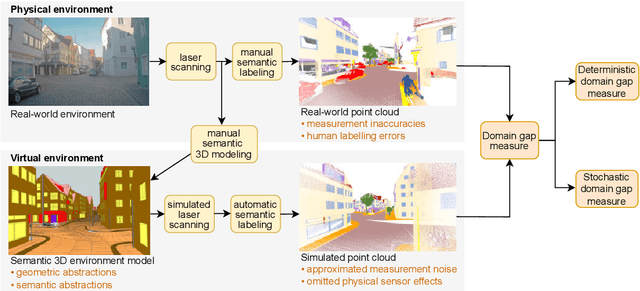
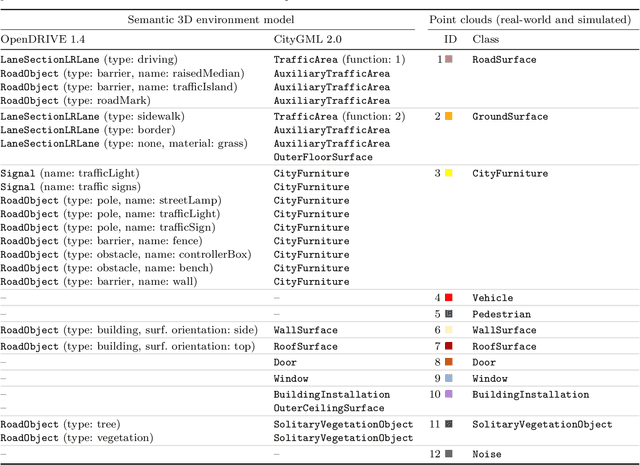
Owing to the typical long-tail data distribution issues, simulating domain-gap-free synthetic data is crucial in robotics, photogrammetry, and computer vision research. The fundamental challenge pertains to credibly measuring the difference between real and simulated data. Such a measure is vital for safety-critical applications, such as automated driving, where out-of-domain samples may impact a car's perception and cause fatal accidents. Previous work has commonly focused on simulating data on one scene and analyzing performance on a different, real-world scene, hampering the disjoint analysis of domain gap coming from networks' deficiencies, class definitions, and object representation. In this paper, we propose a novel approach to measuring the domain gap between the real world sensor observations and simulated data representing the same location, enabling comprehensive domain gap analysis. To measure such a domain gap, we introduce a novel metric DoGSS-PCL and evaluation assessing the geometric and semantic quality of the simulated point cloud. Our experiments corroborate that the introduced approach can be used to measure the domain gap. The tests also reveal that synthetic semantic point clouds may be used for training deep neural networks, maintaining the performance at the 50/50 real-to-synthetic ratio. We strongly believe that this work will facilitate research on credible data simulation and allow for at-scale deployment in automated driving testing and digital twinning.
TUM2TWIN: Introducing the Large-Scale Multimodal Urban Digital Twin Benchmark Dataset
May 13, 2025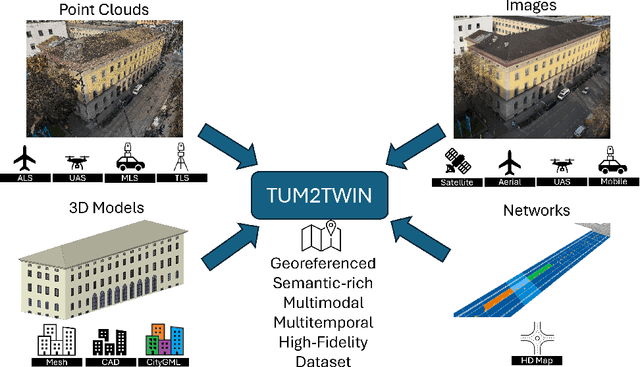
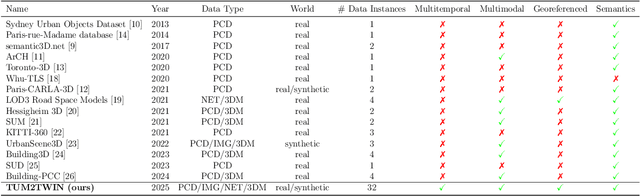

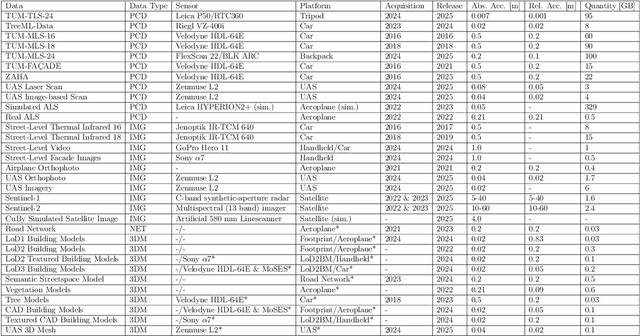
Urban Digital Twins (UDTs) have become essential for managing cities and integrating complex, heterogeneous data from diverse sources. Creating UDTs involves challenges at multiple process stages, including acquiring accurate 3D source data, reconstructing high-fidelity 3D models, maintaining models' updates, and ensuring seamless interoperability to downstream tasks. Current datasets are usually limited to one part of the processing chain, hampering comprehensive UDTs validation. To address these challenges, we introduce the first comprehensive multimodal Urban Digital Twin benchmark dataset: TUM2TWIN. This dataset includes georeferenced, semantically aligned 3D models and networks along with various terrestrial, mobile, aerial, and satellite observations boasting 32 data subsets over roughly 100,000 $m^2$ and currently 767 GB of data. By ensuring georeferenced indoor-outdoor acquisition, high accuracy, and multimodal data integration, the benchmark supports robust analysis of sensors and the development of advanced reconstruction methods. Additionally, we explore downstream tasks demonstrating the potential of TUM2TWIN, including novel view synthesis of NeRF and Gaussian Splatting, solar potential analysis, point cloud semantic segmentation, and LoD3 building reconstruction. We are convinced this contribution lays a foundation for overcoming current limitations in UDT creation, fostering new research directions and practical solutions for smarter, data-driven urban environments. The project is available under: https://tum2t.win
RADLER: Radar Object Detection Leveraging Semantic 3D City Models and Self-Supervised Radar-Image Learning
Apr 16, 2025Semantic 3D city models are worldwide easy-accessible, providing accurate, object-oriented, and semantic-rich 3D priors. To date, their potential to mitigate the noise impact on radar object detection remains under-explored. In this paper, we first introduce a unique dataset, RadarCity, comprising 54K synchronized radar-image pairs and semantic 3D city models. Moreover, we propose a novel neural network, RADLER, leveraging the effectiveness of contrastive self-supervised learning (SSL) and semantic 3D city models to enhance radar object detection of pedestrians, cyclists, and cars. Specifically, we first obtain the robust radar features via a SSL network in the radar-image pretext task. We then use a simple yet effective feature fusion strategy to incorporate semantic-depth features from semantic 3D city models. Having prior 3D information as guidance, RADLER obtains more fine-grained details to enhance radar object detection. We extensively evaluate RADLER on the collected RadarCity dataset and demonstrate average improvements of 5.46% in mean avarage precision (mAP) and 3.51% in mean avarage recall (mAR) over previous radar object detection methods. We believe this work will foster further research on semantic-guided and map-supported radar object detection. Our project page is publicly available athttps://gpp-communication.github.io/RADLER .
FacaDiffy: Inpainting Unseen Facade Parts Using Diffusion Models
Feb 20, 2025



High-detail semantic 3D building models are frequently utilized in robotics, geoinformatics, and computer vision. One key aspect of creating such models is employing 2D conflict maps that detect openings' locations in building facades. Yet, in reality, these maps are often incomplete due to obstacles encountered during laser scanning. To address this challenge, we introduce FacaDiffy, a novel method for inpainting unseen facade parts by completing conflict maps with a personalized Stable Diffusion model. Specifically, we first propose a deterministic ray analysis approach to derive 2D conflict maps from existing 3D building models and corresponding laser scanning point clouds. Furthermore, we facilitate the inpainting of unseen facade objects into these 2D conflict maps by leveraging the potential of personalizing a Stable Diffusion model. To complement the scarcity of real-world training data, we also develop a scalable pipeline to produce synthetic conflict maps using random city model generators and annotated facade images. Extensive experiments demonstrate that FacaDiffy achieves state-of-the-art performance in conflict map completion compared to various inpainting baselines and increases the detection rate by $22\%$ when applying the completed conflict maps for high-definition 3D semantic building reconstruction. The code is be publicly available in the corresponding GitHub repository: https://github.com/ThomasFroech/InpaintingofUnseenFacadeObjects