 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanism Design for Federated Learning with Non-Monotonic Network Effects
Jan 08, 2026Mechanism design is pivotal to federated learning (FL) for maximizing social welfare by coordinating self-interested clients. Existing mechanisms, however, often overlook the network effects of client participation and the diverse model performance requirements (i.e., generalization error) across applications, leading to suboptimal incentives and social welfare, or even inapplicability in real deployments. To address this gap, we explore incentive mechanism design for FL with network effects and application-specific requirements of model performance. We develop a theoretical model to quantify the impact of network effects on heterogeneous client participation, revealing the non-monotonic nature of such effects. Based on these insights, we propose a Model Trading and Sharing (MoTS) framework, which enables clients to obtain FL models through either participation or purchase. To further address clients' strategic behaviors, we design a Social Welfare maximization with Application-aware and Network effects (SWAN) mechanism, exploiting model customer payments for incentivization. Experimental results on a hardware prototype demonstrate that our SWAN mechanism outperforms existing FL mechanisms, improving social welfare by up to $352.42\%$ and reducing extra incentive costs by $93.07\%$.
Intriguing Frequency Interpretation of Adversarial Robustness for CNNs and ViTs
Jun 15, 2025Adversarial examples have attracted significant attention over the years, yet understanding their frequency-based characteristics remains insufficient. In this paper, we investigate the intriguing properties of adversarial examples in the frequency domain for the image classification task, with the following key findings. (1) As the high-frequency components increase, the performance gap between adversarial and natural examples becomes increasingly pronounced. (2) The model performance against filtered adversarial examples initially increases to a peak and declines to its inherent robustness. (3) In Convolutional Neural Networks, mid- and high-frequency components of adversarial examples exhibit their attack capabilities, while in Transformers, low- and mid-frequency components of adversarial examples are particularly effective. These results suggest that different network architectures have different frequency preferences and that differences in frequency components between adversarial and natural examples may directly influence model robustness. Based on our findings, we further conclude with three useful proposals that serve as a valuable reference to the AI model security community.
Temporal Saliency-Guided Distillation: A Scalable Framework for Distilling Video Datasets
May 27, 2025



Dataset distillation (DD) has emerged as a powerful paradigm for dataset compression, enabling the synthesis of compact surrogate datasets that approximate the training utility of large-scale ones. While significant progress has been achieved in distilling image datasets, extending DD to the video domain remains challenging due to the high dimensionality and temporal complexity inherent in video data. Existing video distillation (VD) methods often suffer from excessive computational costs and struggle to preserve temporal dynamics, as na\"ive extensions of image-based approaches typically lead to degraded performance. In this paper, we propose a novel uni-level video dataset distillation framework that directly optimizes synthetic videos with respect to a pre-trained model. To address temporal redundancy and enhance motion preservation, we introduce a temporal saliency-guided filtering mechanism that leverages inter-frame differences to guide the distillation process, encouraging the retention of informative temporal cues while suppressing frame-level redundancy. Extensive experiments on standard video benchmarks demonstrate that our method achieves state-of-the-art performance, bridging the gap between real and distilled video data and offering a scalable solution for video dataset compression.
RADLER: Radar Object Detection Leveraging Semantic 3D City Models and Self-Supervised Radar-Image Learning
Apr 16, 2025Semantic 3D city models are worldwide easy-accessible, providing accurate, object-oriented, and semantic-rich 3D priors. To date, their potential to mitigate the noise impact on radar object detection remains under-explored. In this paper, we first introduce a unique dataset, RadarCity, comprising 54K synchronized radar-image pairs and semantic 3D city models. Moreover, we propose a novel neural network, RADLER, leveraging the effectiveness of contrastive self-supervised learning (SSL) and semantic 3D city models to enhance radar object detection of pedestrians, cyclists, and cars. Specifically, we first obtain the robust radar features via a SSL network in the radar-image pretext task. We then use a simple yet effective feature fusion strategy to incorporate semantic-depth features from semantic 3D city models. Having prior 3D information as guidance, RADLER obtains more fine-grained details to enhance radar object detection. We extensively evaluate RADLER on the collected RadarCity dataset and demonstrate average improvements of 5.46% in mean avarage precision (mAP) and 3.51% in mean avarage recall (mAR) over previous radar object detection methods. We believe this work will foster further research on semantic-guided and map-supported radar object detection. Our project page is publicly available athttps://gpp-communication.github.io/RADLER .
Domain Generalization via Discrete Codebook Learning
Apr 09, 2025Domain generalization (DG) strives to address distribution shifts across diverse environments to enhance model's generalizability. Current DG approaches are confined to acquiring robust representations with continuous features, specifically training at the pixel level. However, this DG paradigm may struggle to mitigate distribution gaps in dealing with a large space of continuous features, rendering it susceptible to pixel details that exhibit spurious correlations or noise. In this paper, we first theoretically demonstrate that the domain gaps in continuous representation learning can be reduced by the discretization process. Based on this inspiring finding, we introduce a novel learning paradigm for DG, termed Discrete Domain Generalization (DDG). DDG proposes to use a codebook to quantize the feature map into discrete codewords, aligning semantic-equivalent information in a shared discrete representation space that prioritizes semantic-level information over pixel-level intricacies. By learning at the semantic level, DDG diminishes the number of latent features, optimizing the utilization of the representation space and alleviating the risks associated with the wide-ranging space of continuous features. Extensive experiments across widely employed benchmarks in DG demonstrate DDG's superior performance compared to state-of-the-art approaches, underscoring its potential to reduce the distribution gaps and enhance the model's generalizability.
Generative Classifier for Domain Generalization
Apr 03, 2025Domain generalization (DG) aims to improve the generalizability of computer vision models toward distribution shifts. The mainstream DG methods focus on learning domain invariance, however, such methods overlook the potential inherent in domain-specific information. While the prevailing practice of discriminative linear classifier has been tailored to domain-invariant features, it struggles when confronted with diverse domain-specific information, e.g., intra-class shifts, that exhibits multi-modality. To address these issues, we explore the theoretical implications of relying on domain invariance, revealing the crucial role of domain-specific information in mitigating the target risk for DG. Drawing from these insights, we propose Generative Classifier-driven Domain Generalization (GCDG), introducing a generative paradigm for the DG classifier based on Gaussian Mixture Models (GMMs) for each class across domains. GCDG consists of three key modules: Heterogeneity Learning Classifier~(HLC), Spurious Correlation Blocking~(SCB), and Diverse Component Balancing~(DCB). Concretely, HLC attempts to model the feature distributions and thereby capture valuable domain-specific information via GMMs. SCB identifies the neural units containing spurious correlations and perturbs them, mitigating the risk of HLC learning spurious patterns. Meanwhile, DCB ensures a balanced contribution of components in HLC, preventing the underestimation or neglect of critical components. In this way, GCDG excels in capturing the nuances of domain-specific information characterized by diverse distributions. GCDG demonstrates the potential to reduce the target risk and encourage flat minima, improving the generalizability. Extensive experiments show GCDG's comparable performance on five DG benchmarks and one face anti-spoofing dataset, seamlessly integrating into existing DG methods with consistent improvements.
Hiformer: Hybrid Frequency Feature Enhancement Inverted Transformer for Long-Term Wind Power Prediction
Oct 17, 2024The increasing severity of climate change necessitates an urgent transition to renewable energy sources, making the large-scale adoption of wind energy crucial for mitigating environmental impact. However, the inherent uncertainty of wind power poses challenges for grid stability, underscoring the need for accurate wind energy prediction models to enable effective power system planning and operation. While many existing studies on wind power prediction focus on short-term forecasting, they often overlook the importance of long-term predictions. Long-term wind power forecasting is essential for effective power grid dispatch and market transactions, as it requires careful consideration of weather features such as wind speed and direction, which directly influence power output. Consequently, methods designed for short-term predictions may lead to inaccurate results and high computational costs in long-term settings. To adress these limitations, we propose a novel approach called Hybrid Frequency Feature Enhancement Inverted Transformer (Hiformer). Hiformer introduces a unique structure that integrates signal decomposition technology with weather feature extraction technique to enhance the modeling of correlations between meteorological conditions and wind power generation. Additionally, Hiformer employs an encoder-only architecture, which reduces the computational complexity associated with long-term wind power forecasting. Compared to the state-of-the-art methods, Hiformer: (i) can improve the prediction accuracy by up to 52.5\%; and (ii) can reduce computational time by up to 68.5\%.
Privacy-Preserving UCB Decision Process Verification via zk-SNARKs
Apr 18, 2024With the increasingly widespread application of machine learning, how to strike a balance between protecting the privacy of data and algorithm parameters and ensuring the verifiability of machine learning has always been a challenge. This study explores the intersection of reinforcement learning and data privacy, specifically addressing the Multi-Armed Bandit (MAB) problem with the Upper Confidence Bound (UCB) algorithm. We introduce zkUCB, an innovative algorithm that employs the Zero-Knowledge Succinct Non-Interactive Argument of Knowledge (zk-SNARKs) to enhance UCB. zkUCB is carefully designed to safeguard the confidentiality of training data and algorithmic parameters, ensuring transparent UCB decision-making. Experiments highlight zkUCB's superior performance, attributing its enhanced reward to judicious quantization bit usage that reduces information entropy in the decision-making process. zkUCB's proof size and verification time scale linearly with the execution steps of zkUCB. This showcases zkUCB's adept balance between data security and operational efficiency. This approach contributes significantly to the ongoing discourse on reinforcing data privacy in complex decision-making processes, offering a promising solution for privacy-sensitive applications.
DGMamba: Domain Generalization via Generalized State Space Model
Apr 11, 2024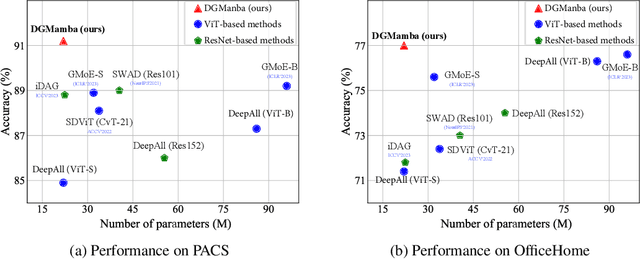
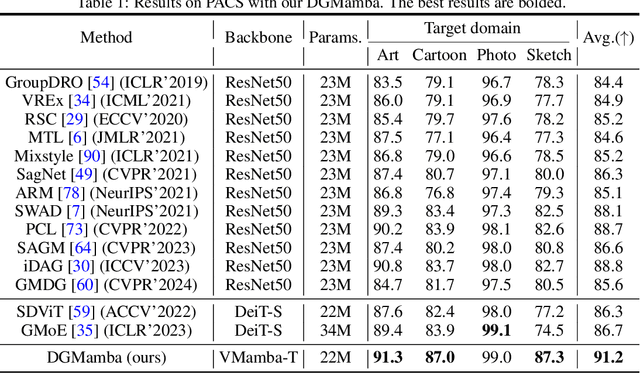
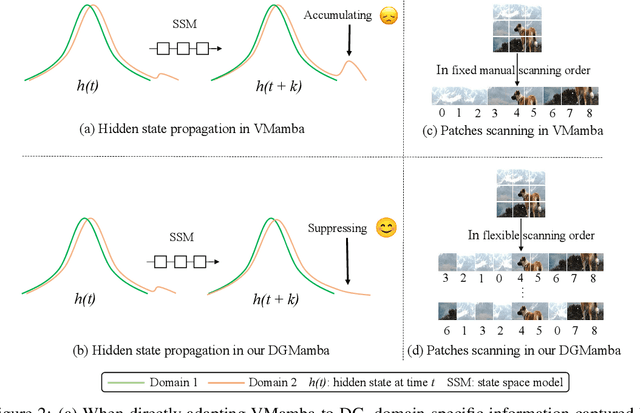

Domain generalization~(DG) aims at solving distribution shift problems in various scenes. Existing approaches are based on Convolution Neural Networks (CNNs) or Vision Transformers (ViTs), which suffer from limited receptive fields or quadratic complexities issues. Mamba, as an emerging state space model (SSM), possesses superior linear complexity and global receptive fields. Despite this, it can hardly be applied to DG to address distribution shifts, due to the hidden state issues and inappropriate scan mechanisms. In this paper, we propose a novel framework for DG, named DGMamba, that excels in strong generalizability toward unseen domains and meanwhile has the advantages of global receptive fields, and efficient linear complexity. Our DGMamba compromises two core components: Hidden State Suppressing~(HSS) and Semantic-aware Patch refining~(SPR). In particular, HSS is introduced to mitigate the influence of hidden states associated with domain-specific features during output prediction. SPR strives to encourage the model to concentrate more on objects rather than context, consisting of two designs: Prior-Free Scanning~(PFS), and Domain Context Interchange~(DCI). Concretely, PFS aims to shuffle the non-semantic patches within images, creating more flexible and effective sequences from images, and DCI is designed to regularize Mamba with the combination of mismatched non-semantic and semantic information by fusing patches among domains. Extensive experiments on four commonly used DG benchmarks demonstrate that the proposed DGMamba achieves remarkably superior results to state-of-the-art models. The code will be made publicly available.
Seeing is not always believing: The Space of Harmless Perturbations
Feb 03, 2024



In the context of deep neural networks, we expose the existence of a harmless perturbation space, where perturbations leave the network output entirely unaltered. Perturbations within this harmless perturbation space, regardless of their magnitude when applied to images, exhibit no impact on the network's outputs of the original images. Specifically, given any linear layer within the network, where the input dimension $n$ exceeds the output dimension $m$, we demonstrate the existence of a continuous harmless perturbation subspace with a dimension of $(n-m)$. Inspired by this, we solve for a family of general perturbations that consistently influence the network output, irrespective of their magnitudes. With these theoretical findings, we explore the application of harmless perturbations for privacy-preserving data usage. Our work reveals the difference between DNNs and human perception that the significant perturbations captured by humans may not affect the recognition of DNNs. As a result, we utilize this gap to design a type of harmless perturbation that is meaningless for humans while maintaining its recognizable features for DNNs.