 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semantically Enhanced Generative Foundation Model Improves Pathological Image Synthesis
Dec 16, 2025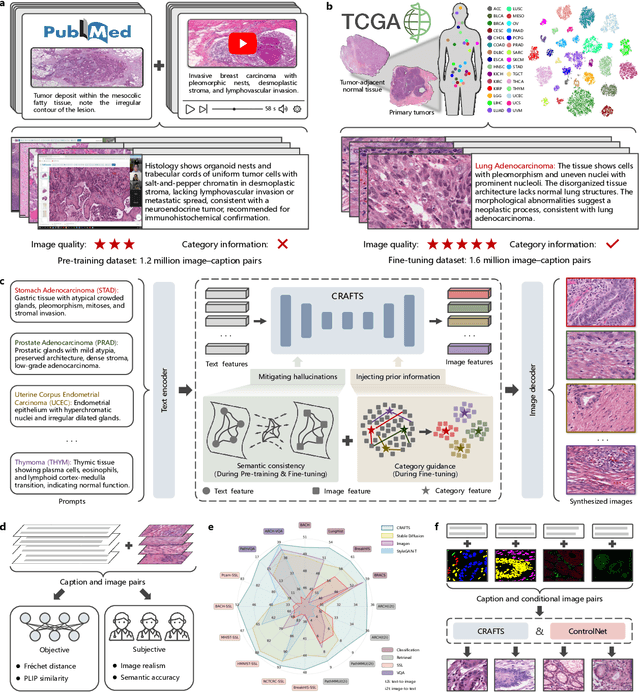
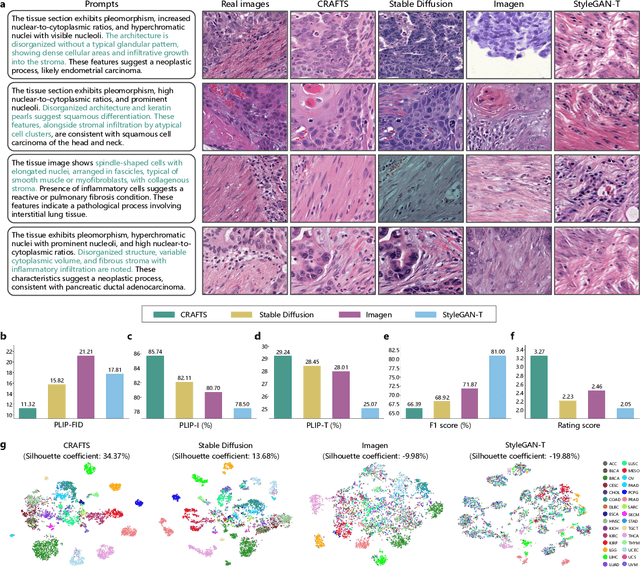
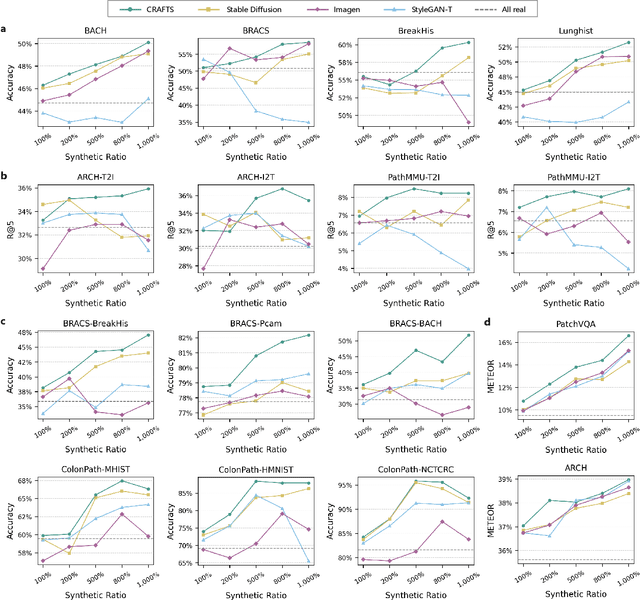
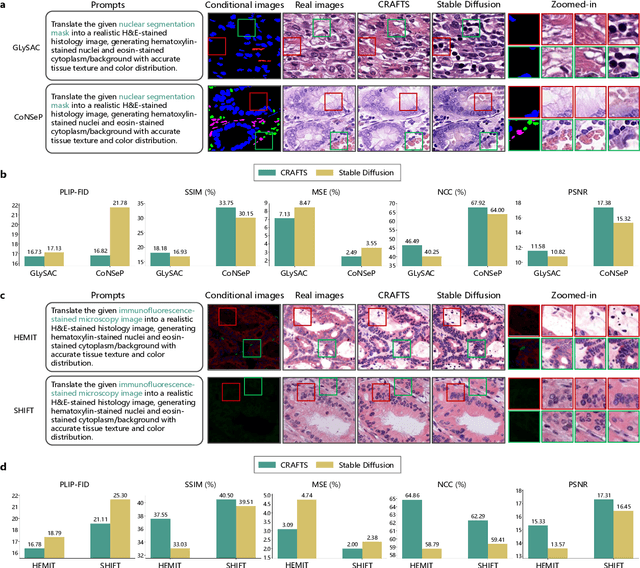
The development of clinical-grade artificial intelligence in pathology is limited by the scarcity of diverse, high-quality annotated datasets. Generative models offer a potential solution but suffer from semantic instability and morphological hallucinations that compromise diagnostic reliability. To address this challenge, we introduce a Correlation-Regulated Alignment Framework for Tissue Synthesis (CRAFTS), the first generative foundation model for pathology-specific text-to-image synthesis. By leveraging a dual-stage training strategy on approximately 2.8 million image-caption pairs, CRAFTS incorporates a novel alignment mechanism that suppresses semantic drift to ensure biological accuracy. This model generates diverse pathological images spanning 30 cancer types, with quality rigorously validated by objective metrics and pathologist evaluations. Furthermore, CRAFTS-augmented datasets enhance the performance across various clinical tasks, including classification, cross-modal retrieval, self-supervised learning, and visual question answering. In addition, coupling CRAFTS with ControlNet enables precise control over tissue architecture from inputs such as nuclear segmentation masks and fluorescence images. By overcoming the critical barriers of data scarcity and privacy concerns, CRAFTS provides a limitless source of diverse, annotated histology data, effectively unlocking the creation of robust diagnostic tools for rare and complex cancer phenotypes.
Continuous Vision-Language-Action Co-Learning with Semantic-Physical Alignment for Behavioral Cloning
Nov 18, 2025
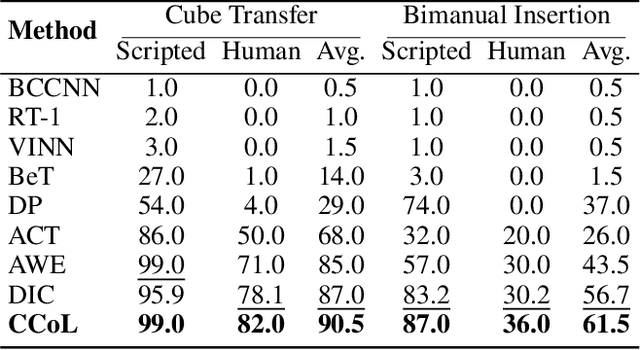


Language-conditioned manipulation facilitates human-robot interaction via behavioral cloning (BC), which learns control policies from human demonstrations and serves as a cornerstone of embodied AI. Overcoming compounding errors in sequential action decisions remains a central challenge to improving BC performance. Existing approaches mitigate compounding errors through data augmentation, expressive representation, or temporal abstraction. However, they suffer from physical discontinuities and semantic-physical misalignment, leading to inaccurate action cloning and intermittent execution. In this paper, we present Continuous vision-language-action Co-Learning with Semantic-Physical Alignment (CCoL), a novel BC framework that ensures temporally consistent execution and fine-grained semantic grounding. It generates robust and smooth action execution trajectories through continuous co-learning across vision, language, and proprioceptive inputs (e.g., robot internal states). Meanwhile, we anchor language semantics to visuomotor representations by a bidirectional cross-attention to learn contextual information for action generation, successfully overcoming the problem of semantic-physical misalignment. Extensive experiments show that CCoL achieves an average 8.0% relative improvement across three simulation suites, with up to 19.2% relative gain in human-demonstrated bimanual insertion tasks. Real-world tests on a 7-DoF robot further confirm CCoL's generalization under unseen and noisy object states.
Adaptive Blind Super-Resolution Network for Spatial-Specific and Spatial-Agnostic Degradations
Jun 09, 2025Prior methodologies have disregarded the diversities among distinct degradation types during image reconstruction, employing a uniform network model to handle multiple deteriorations. Nevertheless, we discover that prevalent degradation modalities, including sampling, blurring, and noise, can be roughly categorized into two classes. We classify the first class as spatial-agnostic dominant degradations, less affected by regional changes in image space, such as downsampling and noise degradation. The second class degradation type is intimately associated with the spatial position of the image, such as blurring, and we identify them as spatial-specific dominant degradations. We introduce a dynamic filter network integrating global and local branches to address these two degradation types. This network can greatly alleviate the practical degradation problem. Specifically, the global dynamic filtering layer can perceive the spatial-agnostic dominant degradation in different images by applying weights generated by the attention mechanism to multiple parallel standard convolution kernels, enhancing the network's representation ability. Meanwhile, the local dynamic filtering layer converts feature maps of the image into a spatially specific dynamic filtering operator, which performs spatially specific convolution operations on the image features to handle spatial-specific dominant degradations. By effectively integrating both global and local dynamic filtering operators, our proposed method outperforms state-of-the-art blind super-resolution algorithms in both synthetic and real image datasets.
Temporal Saliency-Guided Distillation: A Scalable Framework for Distilling Video Datasets
May 27, 2025Dataset distillation (DD) has emerged as a powerful paradigm for dataset compression, enabling the synthesis of compact surrogate datasets that approximate the training utility of large-scale ones. While significant progress has been achieved in distilling image datasets, extending DD to the video domain remains challenging due to the high dimensionality and temporal complexity inherent in video data. Existing video distillation (VD) methods often suffer from excessive computational costs and struggle to preserve temporal dynamics, as na\"ive extensions of image-based approaches typically lead to degraded performance. In this paper, we propose a novel uni-level video dataset distillation framework that directly optimizes synthetic videos with respect to a pre-trained model. To address temporal redundancy and enhance motion preservation, we introduce a temporal saliency-guided filtering mechanism that leverages inter-frame differences to guide the distillation process, encouraging the retention of informative temporal cues while suppressing frame-level redundancy. Extensive experiments on standard video benchmarks demonstrate that our method achieves state-of-the-art performance, bridging the gap between real and distilled video data and offering a scalable solution for video dataset compression.
Collision Risk Quantification and Conflict Resolution in Trajectory Tracking for Acceleration-Actuated Multi-Robot Systems
Jan 07, 2025



One of the pivotal challenges in a multi-robot system is how to give attention to accuracy and efficiency while ensuring safety. Prior arts cannot strictly guarantee collision-free for an arbitrarily large number of robots or the results are considerably conservative. Smoothness of the avoidance trajectory also needs to be further optimized. This paper proposes an accelerationactuated simultaneous obstacle avoidance and trajectory tracking method for arbitrarily large teams of robots, that provides a nonconservative collision avoidance strategy and gives approaches for deadlock avoidance. We propose two ways of deadlock resolution, one involves incorporating an auxiliary velocity vector into the error function of the trajectory tracking module, which is proven to have no influence on global convergence of the tracking error. Furthermore, unlike the traditional methods that they address conflicts after a deadlock occurs, our decision-making mechanism avoids the near-zero velocity, which is much more safer and efficient in crowed environments. Extensive comparison show that the proposed method is superior to the existing studies when deployed in a large-scale robot system, with minimal invasiveness.
Channel and Spatial Relation-Propagation Network for RGB-Thermal Semantic Segmentation
Aug 24, 2023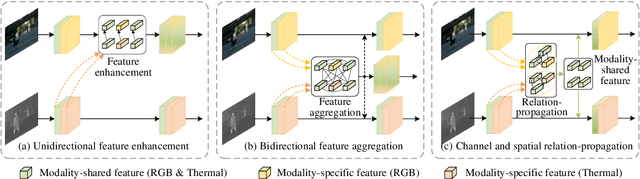
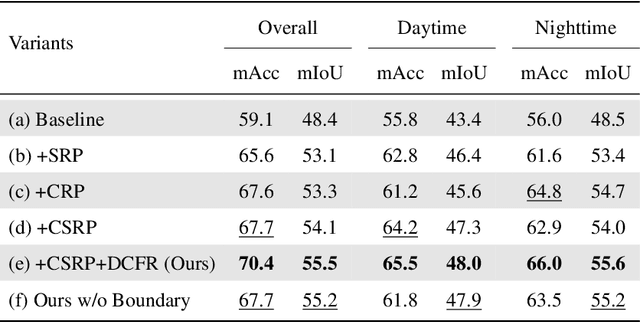
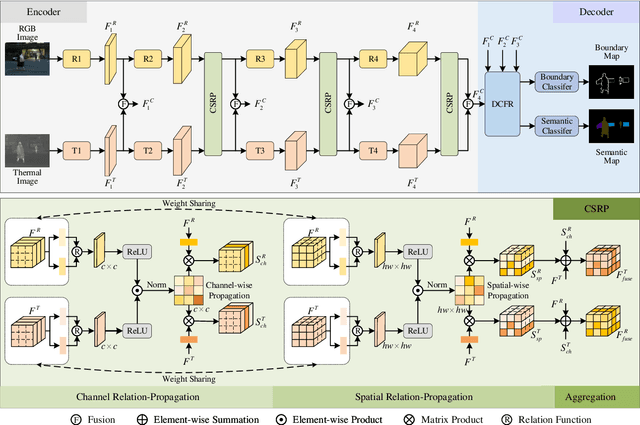

RGB-Thermal (RGB-T) semantic segmentation has shown great potential in handling low-light conditions where RGB-based segmentation is hindered by poor RGB imaging quality. The key to RGB-T semantic segmentation is to effectively leverage the complementarity nature of RGB and thermal images. Most existing algorithms fuse RGB and thermal information in feature space via concatenation, element-wise summation, or attention operations in either unidirectional enhancement or bidirectional aggregation manners. However, they usually overlook the modality gap between RGB and thermal images during feature fusion, resulting in modality-specific information from one modality contaminating the other. In this paper, we propose a Channel and Spatial Relation-Propagation Network (CSRPNet) for RGB-T semantic segmentation, which propagates only modality-shared information across different modalities and alleviates the modality-specific information contamination issue. Our CSRPNet first performs relation-propagation in channel and spatial dimensions to capture the modality-shared features from the RGB and thermal features. CSRPNet then aggregates the modality-shared features captured from one modality with the input feature from the other modality to enhance the input feature without the contamination issue. While being fused together, the enhanced RGB and thermal features will be also fed into the subsequent RGB or thermal feature extraction layers for interactive feature fusion, respectively. We also introduce a dual-path cascaded feature refinement module that aggregates multi-layer features to produce two refined features for semantic and boundary prediction. Extensive experimental results demonstrate that CSRPNet performs favorably against state-of-the-art algorithms.
Reliability-Hierarchical Memory Network for Scribble-Supervised Video Object Segmentation
Mar 25, 2023This paper aims to solve the video object segmentation (VOS) task in a scribble-supervised manner, in which VOS models are not only trained by the sparse scribble annotations but also initialized with the sparse target scribbles for inference. Thus, the annotation burdens for both training and initialization can be substantially lightened. The difficulties of scribble-supervised VOS lie in two aspects. On the one hand, it requires the powerful ability to learn from the sparse scribble annotations during training. On the other hand, it demands strong reasoning capability during inference given only a sparse initial target scribble. In this work, we propose a Reliability-Hierarchical Memory Network (RHMNet) to predict the target mask in a step-wise expanding strategy w.r.t. the memory reliability level. To be specific, RHMNet first only uses the memory in the high-reliability level to locate the region with high reliability belonging to the target, which is highly similar to the initial target scribble. Then it expands the located high-reliability region to the entire target conditioned on the region itself and the memories in all reliability levels. Besides, we propose a scribble-supervised learning mechanism to facilitate the learning of our model to predict dense results. It mines the pixel-level relation within the single frame and the frame-level relation within the sequence to take full advantage of the scribble annotations in sequence training samples. The favorable performance on two popular benchmarks demonstrates that our method is promising.
Global Tracking via Ensemble of Local Trackers
Mar 30, 2022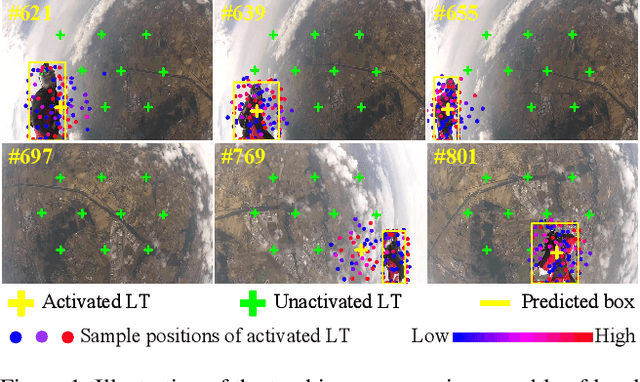
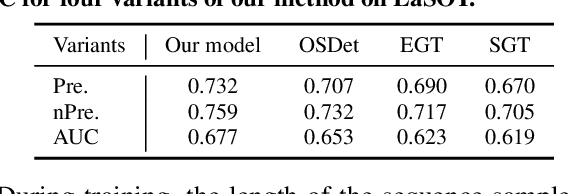
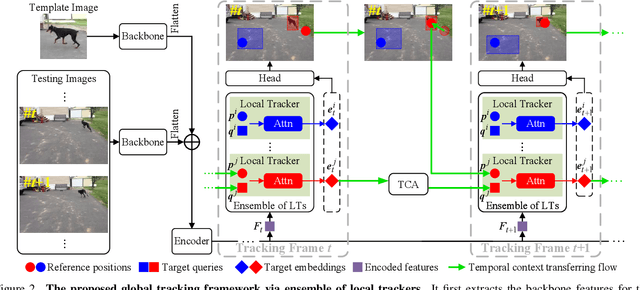
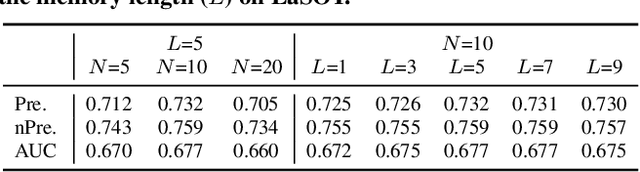
The crux of long-term tracking lies in the difficulty of tracking the target with discontinuous moving caused by out-of-view or occlusion. Existing long-term tracking methods follow two typical strategies. The first strategy employs a local tracker to perform smooth tracking and uses another re-detector to detect the target when the target is lost. While it can exploit the temporal context like historical appearances and locations of the target, a potential limitation of such strategy is that the local tracker tends to misidentify a nearby distractor as the target instead of activating the re-detector when the real target is out of view. The other long-term tracking strategy tracks the target in the entire image globally instead of local tracking based on the previous tracking results. Unfortunately, such global tracking strategy cannot leverage the temporal context effectively. In this work, we combine the advantages of both strategies: tracking the target in a global view while exploiting the temporal context. Specifically, we perform global tracking via ensemble of local trackers spreading the full image. The smooth moving of the target can be handled steadily by one local tracker. When the local tracker accidentally loses the target due to suddenly discontinuous moving, another local tracker close to the target is then activated and can readily take over the tracking to locate the target. While the activated local tracker performs tracking locally by leveraging the temporal context, the ensemble of local trackers renders our model the global view for tracking. Extensive experiments on six datasets demonstrate that our method performs favorably against state-of-the-art algorithms.
GroupTransNet: Group Transformer Network for RGB-D Salient Object Detection
Mar 21, 2022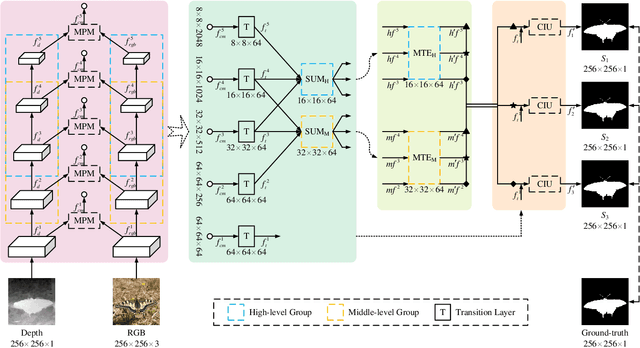
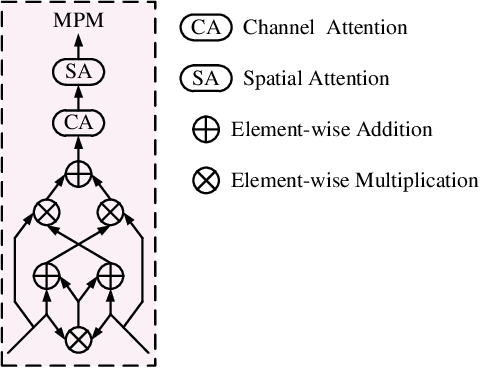
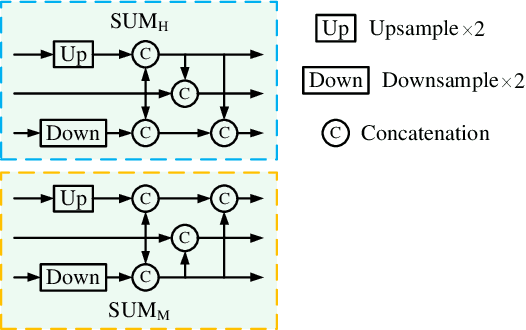
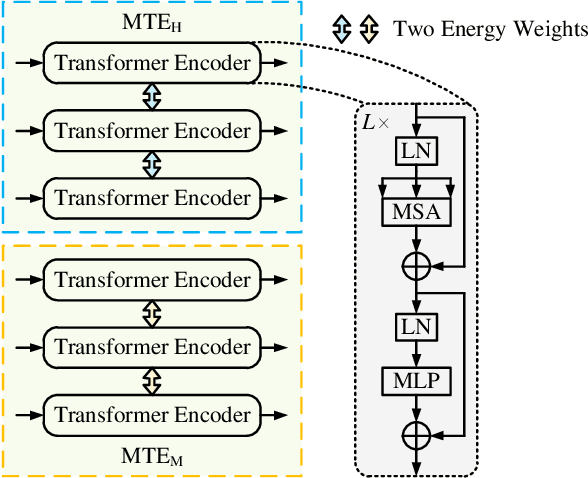
Salient object detection on RGB-D images is an active topic in computer vision. Although the existing methods have achieved appreciable performance, there are still some challenges. The locality of convolutional neural network requires that the model has a sufficiently deep global receptive field, which always leads to the loss of local details. To address the challenge, we propose a novel Group Transformer Network (GroupTransNet) for RGB-D salient object detection. This method is good at learning the long-range dependencies of cross layer features to promote more perfect feature expression. At the beginning, the features of the slightly higher classes of the middle three levels and the latter three levels are soft grouped to absorb the advantages of the high-level features. The input features are repeatedly purified and enhanced by the attention mechanism to purify the cross modal features of color modal and depth modal. The features of the intermediate process are first fused by the features of different layers, and then processed by several transformers in multiple groups, which not only makes the size of the features of each scale unified and interrelated, but also achieves the effect of sharing the weight of the features within the group. The output features in different groups complete the clustering staggered by two owing to the level difference, and combine with the low-level features. Extensive experiments demonstrate that GroupTransNet outperforms the comparison models and achieves the new state-of-the-art performance.
LC3Net: Ladder context correlation complementary network for salient object detection
Oct 21, 2021
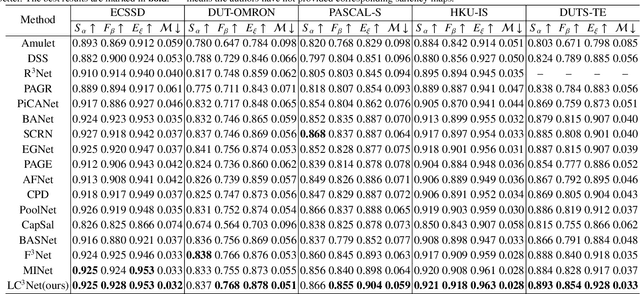
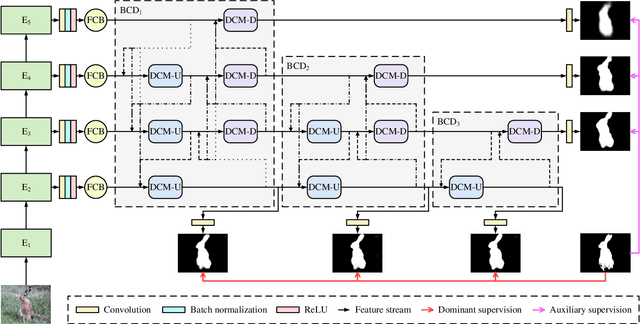
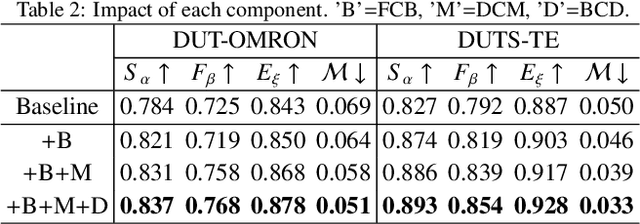
Currently, existing salient object detection methods based on convolutional neural networks commonly resort to constructing discriminative networks to aggregate high level and low level features. However, contextual information is always not fully and reasonably utilized, which usually causes either the absence of useful features or contamination of redundant features. To address these issues, we propose a novel ladder context correlation complementary network (LC3Net) in this paper, which is equipped with three crucial components. At the beginning, we propose a filterable convolution block (FCB) to assist the automatic collection of information on the diversity of initial features, and it is simple yet practical. Besides, we propose a dense cross module (DCM) to facilitate the intimate aggregation of different levels of features by validly integrating semantic information and detailed information of both adjacent and non-adjacent layers. Furthermore, we propose a bidirectional compression decoder (BCD) to help the progressive shrinkage of multi-scale features from coarse to fine by leveraging multiple pairs of alternating top-down and bottom-up feature interaction flows. Extensive experiments demonstrate the superiority of our method against 16 state-of-the-art methods.