 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHISA: Efficient Hierarchical Indexing for Fine-Grained Sparse Attention
Apr 01, 2026Token-level sparse attention mechanisms, exemplified by DeepSeek Sparse Attention (DSA), achieve fine-grained key selection by scoring every historical key for each query through a lightweight indexer, then computing attention only on the selected subset. While the downstream sparse attention itself scales favorably, the indexer must still scan the entire prefix for every query, introducing an per-layer bottleneck that grows prohibitively with context length. We propose HISA (Hierarchical Indexed Sparse Attention), a plug-and-play replacement for the indexer that rewrites the search path from a flat token scan into a two-stage hierarchical procedure: (1) a block-level coarse filtering stage that scores pooled block representations to discard irrelevant regions, followed by (2) a token-level refinement stage that applies the original indexer exclusively within the retained candidate blocks. HISA preserves the identical token-level top-sparse pattern consumed by the downstream Sparse MLA operator and requires no additional training. On kernel-level benchmarks, HISA achieves up to speedup at 64K context. On Needle-in-a-Haystack and LongBench, we directly replace the indexer in DeepSeek-V3.2 and GLM-5 with our HISA indexer, without any finetuning. HISA closely matches the original DSA in quality, while substantially outperforming block-sparse baselines.
Too Vivid to Be Real? Benchmarking and Calibrating Generative Color Fidelity
Mar 11, 2026Recent advances in text-to-image (T2I) generation have greatly improved visual quality, yet producing images that appear visually authentic to real-world photography remains challenging. This is partly due to biases in existing evaluation paradigms: human ratings and preference-trained metrics often favor visually vivid images with exaggerated saturation and contrast, which make generations often too vivid to be real even when prompted for realistic-style images. To address this issue, we present Color Fidelity Dataset (CFD) and Color Fidelity Metric (CFM) for objective evaluation of color fidelity in realistic-style generations. CFD contains over 1.3M real and synthetic images with ordered levels of color realism, while CFM employs a multimodal encoder to learn perceptual color fidelity. In addition, we propose a training-free Color Fidelity Refinement (CFR) that adaptively modulates spatial-temporal guidance scale in generation, thereby enhancing color authenticity. Together, CFD supports CFM for assessment, whose learned attention further guides CFR to refine T2I fidelity, forming a progressive framework for assessing and improving color fidelity in realistic-style T2I generation. The dataset and code are available at https://github.com/ZhengyaoFang/CFM.
Prune Redundancy, Preserve Essence: Vision Token Compression in VLMs via Synergistic Importance-Diversity
Mar 11, 2026Vision-language models (VLMs) face significant computational inefficiencies caused by excessive generation of visual tokens. While prior work shows that a large fraction of visual tokens are redundant, existing compression methods struggle to balance importance preservation and information diversity. To address this, we propose PruneSID, a training-free Synergistic Importance-Diversity approach featuring a two-stage pipeline: (1) Principal Semantic Components Analysis (PSCA) for clustering tokens into semantically coherent groups, ensuring comprehensive concept coverage, and (2) Intra-group Non-Maximum Suppression (NMS) for pruning redundant tokens while preserving key representative tokens within each group. Additionally, PruneSID incorporates an information-aware dynamic compression ratio mechanism that optimizes token compression rates based on image complexity, enabling more effective average information preservation across diverse scenes. Extensive experiments demonstrate state-of-the-art performance, achieving 96.3% accuracy on LLaVA-1.5 with only 11.1% token retention, and 92.8% accuracy at extreme compression rates (5.6%) on LLaVA-NeXT, outperforming prior methods by 2.5% with 7.8 $\times$ faster prefilling speed compared to the original model. Our framework generalizes across diverse VLMs and both image and video modalities, showcasing strong cross-modal versatility. Code is available at https://github.com/ZhengyaoFang/PruneSID.
DiffTrans: Differentiable Geometry-Materials Decomposition for Reconstructing Transparent Objects
Feb 28, 2026Reconstructing transparent objects from a set of multi-view images is a challenging task due to the complicated nature and indeterminate behavior of light propagation. Typical methods are primarily tailored to specific scenarios, such as objects following a uniform topology, exhibiting ideal transparency and surface specular reflections, or with only surface materials, which substantially constrains their practical applicability in real-world settings. In this work, we propose a differentiable rendering framework for transparent objects, dubbed DiffTrans, which allows for efficient decomposition and reconstruction of the geometry and materials of transparent objects, thereby reconstructing transparent objects accurately in intricate scenes with diverse topology and complex texture. Specifically, we first utilize FlexiCubes with dilation and smoothness regularization as the iso-surface representation to reconstruct an initial geometry efficiently from the multi-view object silhouette. Meanwhile, we employ the environment light radiance field to recover the environment of the scene. Then we devise a recursive differentiable ray tracer to further optimize the geometry, index of refraction and absorption rate simultaneously in a unified and end-to-end manner, leading to high-quality reconstruction of transparent objects in intricate scenes. A prominent advantage of the designed ray tracer is that it can be implemented in CUDA, enabling a significantly reduced computational cost. Extensive experiments on multiple benchmarks demonstrate the superior reconstruction performance of our DiffTrans compared with other methods, especially in intricate scenes involving transparent objects with diverse topology and complex texture. The code is available at https://github.com/lcp29/DiffTrans.
Breaking the Blocks: Continuous Low-Rank Decomposed Scaling for Unified LLM Quantization and Adaptation
Jan 30, 2026Current quantization methods for LLMs predominantly rely on block-wise structures to maintain efficiency, often at the cost of representational flexibility. In this work, we demonstrate that element-wise quantization can be made as efficient as block-wise scaling while providing strictly superior expressive power by modeling the scaling manifold as continuous low-rank matrices ($S = BA$). We propose Low-Rank Decomposed Scaling (LoRDS), a unified framework that rethinks quantization granularity through this low-rank decomposition. By "breaking the blocks" of spatial constraints, LoRDS establishes a seamless efficiency lifecycle: it provides high-fidelity PTQ initialization refined via iterative optimization, enables joint QAT of weights and scaling factors, and facilitates high-rank multiplicative PEFT adaptation. Unlike additive PEFT approaches such as QLoRA, LoRDS enables high-rank weight updates within a low-rank budget while incurring no additional inference overhead. Supported by highly optimized Triton kernels, LoRDS consistently outperforms state-of-the-art baselines across various model families in both quantization and downstream fine-tuning tasks. Notably, on Llama3-8B, our method achieves up to a 27.0% accuracy improvement at 3 bits over NormalFloat quantization and delivers a 1.5x inference speedup on NVIDIA RTX 4090 while enhancing PEFT performance by 9.6% on downstream tasks over 4bit QLoRA, offering a robust and integrated solution for unified compression and adaptation of LLMs.
Lightweight Joint Audio-Visual Deepfake Detection via Single-Stream Multi-Modal Learning Framework
Jun 09, 2025Deepfakes are AI-synthesized multimedia data that may be abused for spreading misinformation. Deepfake generation involves both visual and audio manipulation. To detect audio-visual deepfakes, previous studies commonly employ two relatively independent sub-models to learn audio and visual features, respectively, and fuse them subsequently for deepfake detection. However, this may underutilize the inherent correlations between audio and visual features. Moreover, utilizing two isolated feature learning sub-models can result in redundant neural layers, making the overall model inefficient and impractical for resource-constrained environments. In this work, we design a lightweight network for audio-visual deepfake detection via a single-stream multi-modal learning framework. Specifically, we introduce a collaborative audio-visual learning block to efficiently integrate multi-modal information while learning the visual and audio features. By iteratively employing this block, our single-stream network achieves a continuous fusion of multi-modal features across its layers. Thus, our network efficiently captures visual and audio features without the need for excessive block stacking, resulting in a lightweight network design. Furthermore, we propose a multi-modal classification module that can boost the dependence of the visual and audio classifiers on modality content. It also enhances the whole resistance of the video classifier against the mismatches between audio and visual modalities. We conduct experiments on the DF-TIMIT, FakeAVCeleb, and DFDC benchmark datasets. Compared to state-of-the-art audio-visual joint detection methods, our method is significantly lightweight with only 0.48M parameters, yet it achieves superiority in both uni-modal and multi-modal deepfakes, as well as in unseen types of deepfakes.
Learning Compatible Multi-Prize Subnetworks for Asymmetric Retrieval
Apr 16, 2025Asymmetric retrieval is a typical scenario in real-world retrieval systems, where compatible models of varying capacities are deployed on platforms with different resource configurations. Existing methods generally train pre-defined networks or subnetworks with capacities specifically designed for pre-determined platforms, using compatible learning. Nevertheless, these methods suffer from limited flexibility for multi-platform deployment. For example, when introducing a new platform into the retrieval systems, developers have to train an additional model at an appropriate capacity that is compatible with existing models via backward-compatible learning. In this paper, we propose a Prunable Network with self-compatibility, which allows developers to generate compatible subnetworks at any desired capacity through post-training pruning. Thus it allows the creation of a sparse subnetwork matching the resources of the new platform without additional training. Specifically, we optimize both the architecture and weight of subnetworks at different capacities within a dense network in compatible learning. We also design a conflict-aware gradient integration scheme to handle the gradient conflicts between the dense network and subnetworks during compatible learning. Extensive experiments on diverse benchmarks and visual backbones demonstrate the effectiveness of our method. Our code and model are available at https://github.com/Bunny-Black/PrunNet.
Prototype Perturbation for Relaxing Alignment Constraints in Backward-Compatible Learning
Mar 19, 2025The traditional paradigm to update retrieval models requires re-computing the embeddings of the gallery data, a time-consuming and computationally intensive process known as backfilling. To circumvent backfilling, Backward-Compatible Learning (BCL) has been widely explored, which aims to train a new model compatible with the old one. Many previous works focus on effectively aligning the embeddings of the new model with those of the old one to enhance the backward-compatibility. Nevertheless, such strong alignment constraints would compromise the discriminative ability of the new model, particularly when different classes are closely clustered and hard to distinguish in the old feature space. To address this issue, we propose to relax the constraints by introducing perturbations to the old feature prototypes. This allows us to align the new feature space with a pseudo-old feature space defined by these perturbed prototypes, thereby preserving the discriminative ability of the new model in backward-compatible learning. We have developed two approaches for calculating the perturbations: Neighbor-Driven Prototype Perturbation (NDPP) and Optimization-Driven Prototype Perturbation (ODPP). Particularly, they take into account the feature distributions of not only the old but also the new models to obtain proper perturbations along with new model updating. Extensive experiments on the landmark and commodity datasets demonstrate that our approaches perform favorably against state-of-the-art BCL algorithms.
Recognition-Synergistic Scene Text Editing
Mar 11, 2025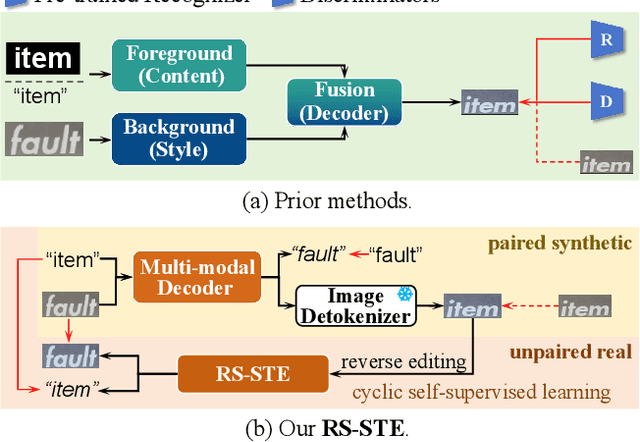
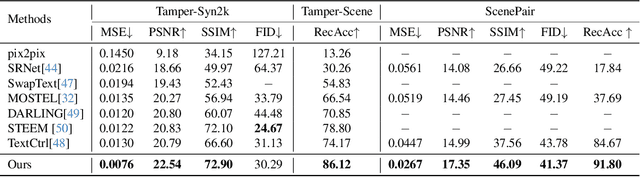
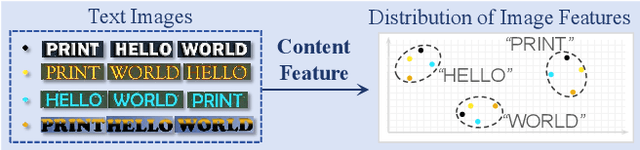
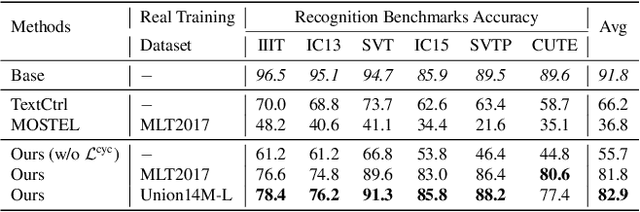
Scene text editing aims to modify text content within scene images while maintaining style consistency. Traditional methods achieve this by explicitly disentangling style and content from the source image and then fusing the style with the target content, while ensuring content consistency using a pre-trained recognition model. Despite notable progress, these methods suffer from complex pipelines, leading to suboptimal performance in complex scenarios. In this work, we introduce Recognition-Synergistic Scene Text Editing (RS-STE), a novel approach that fully exploits the intrinsic synergy of text recognition for editing. Our model seamlessly integrates text recognition with text editing within a unified framework, and leverages the recognition model's ability to implicitly disentangle style and content while ensuring content consistency. Specifically, our approach employs a multi-modal parallel decoder based on transformer architecture, which predicts both text content and stylized images in parallel. Additionally, our cyclic self-supervised fine-tuning strategy enables effective training on unpaired real-world data without ground truth, enhancing style and content consistency through a twice-cyclic generation process. Built on a relatively simple architecture, \mymodel achieves state-of-the-art performance on both synthetic and real-world benchmarks, and further demonstrates the effectiveness of leveraging the generated hard cases to boost the performance of downstream recognition tasks. Code is available at https://github.com/ZhengyaoFang/RS-STE.
WeCromCL: Weakly Supervised Cross-Modality Contrastive Learning for Transcription-only Supervised Text Spotting
Jul 28, 2024Transcription-only Supervised Text Spotting aims to learn text spotters relying only on transcriptions but no text boundaries for supervision, thus eliminating expensive boundary annotation. The crux of this task lies in locating each transcription in scene text images without location annotations. In this work, we formulate this challenging problem as a Weakly Supervised Cross-modality Contrastive Learning problem, and design a simple yet effective model dubbed WeCromCL that is able to detect each transcription in a scene image in a weakly supervised manner. Unlike typical methods for cross-modality contrastive learning that focus on modeling the holistic semantic correlation between an entire image and a text description, our WeCromCL conducts atomistic contrastive learning to model the character-wise appearance consistency between a text transcription and its correlated region in a scene image to detect an anchor point for the transcription in a weakly supervised manner. The detected anchor points by WeCromCL are further used as pseudo location labels to guide the learning of text spotting. Extensive experiments on four challenging benchmarks demonstrate the superior performance of our model over other methods. Code will be released.