 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Joint Audio-Visual Deepfake Detection via Single-Stream Multi-Modal Learning Framework
Jun 09, 2025Deepfakes are AI-synthesized multimedia data that may be abused for spreading misinformation. Deepfake generation involves both visual and audio manipulation. To detect audio-visual deepfakes, previous studies commonly employ two relatively independent sub-models to learn audio and visual features, respectively, and fuse them subsequently for deepfake detection. However, this may underutilize the inherent correlations between audio and visual features. Moreover, utilizing two isolated feature learning sub-models can result in redundant neural layers, making the overall model inefficient and impractical for resource-constrained environments. In this work, we design a lightweight network for audio-visual deepfake detection via a single-stream multi-modal learning framework. Specifically, we introduce a collaborative audio-visual learning block to efficiently integrate multi-modal information while learning the visual and audio features. By iteratively employing this block, our single-stream network achieves a continuous fusion of multi-modal features across its layers. Thus, our network efficiently captures visual and audio features without the need for excessive block stacking, resulting in a lightweight network design. Furthermore, we propose a multi-modal classification module that can boost the dependence of the visual and audio classifiers on modality content. It also enhances the whole resistance of the video classifier against the mismatches between audio and visual modalities. We conduct experiments on the DF-TIMIT, FakeAVCeleb, and DFDC benchmark datasets. Compared to state-of-the-art audio-visual joint detection methods, our method is significantly lightweight with only 0.48M parameters, yet it achieves superiority in both uni-modal and multi-modal deepfakes, as well as in unseen types of deepfakes.
Phoneme-Level Feature Discrepancies: A Key to Detecting Sophisticated Speech Deepfakes
Dec 17, 2024



Recent advancements in text-to-speech and speech conversion technologies have enabled the creation of highly convincing synthetic speech. While these innovations offer numerous practical benefits, they also cause significant security challenges when maliciously misused. Therefore, there is an urgent need to detect these synthetic speech signals. Phoneme features provide a powerful speech representation for deepfake detection. However, previous phoneme-based detection approaches typically focused on specific phonemes, overlooking temporal inconsistencies across the entire phoneme sequence. In this paper, we develop a new mechanism for detecting speech deepfakes by identifying the inconsistencies of phoneme-level speech features. We design an adaptive phoneme pooling technique that extracts sample-specific phoneme-level features from frame-level speech data. By applying this technique to features extracted by pre-trained audio models on previously unseen deepfake datasets, we demonstrate that deepfake samples often exhibit phoneme-level inconsistencies when compared to genuine speech. To further enhance detection accuracy, we propose a deepfake detector that uses a graph attention network to model the temporal dependencies of phoneme-level features. Additionally, we introduce a random phoneme substitution augmentation technique to increase feature diversity during training. Extensive experiments on four benchmark datasets demonstrate the superior performance of our method over existing state-of-the-art detection methods.
Robust AI-Synthesized Speech Detection Using Feature Decomposition Learning and Synthesizer Feature Augmentation
Nov 14, 2024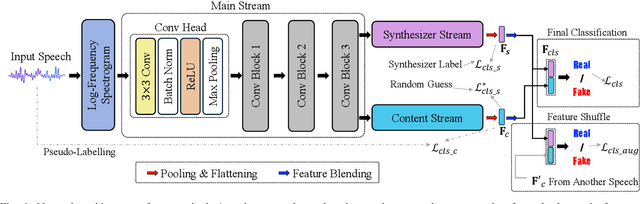
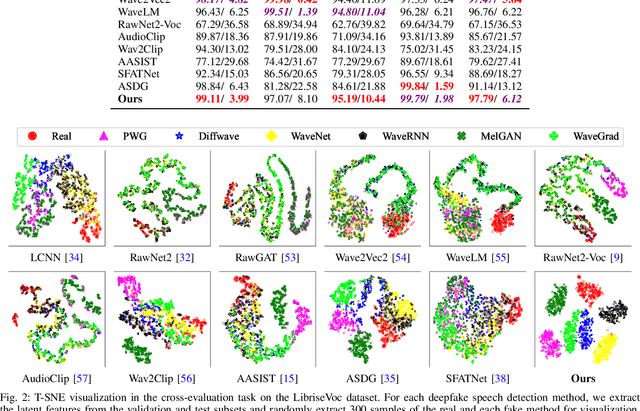
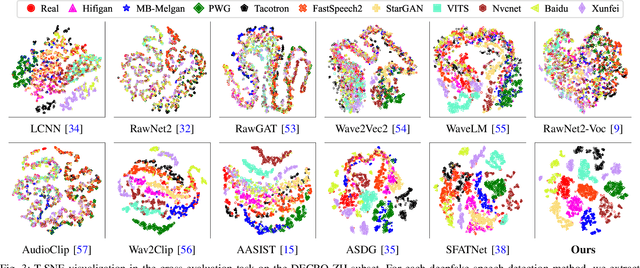
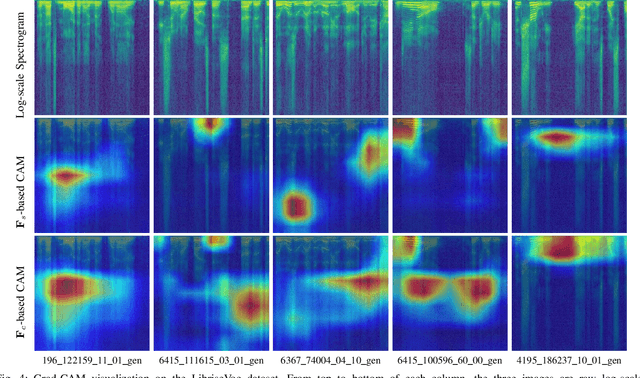
AI-synthesized speech, also known as deepfake speech, has recently raised significant concerns due to the rapid advancement of speech synthesis and speech conversion techniques. Previous works often rely on distinguishing synthesizer artifacts to identify deepfake speech. However, excessive reliance on these specific synthesizer artifacts may result in unsatisfactory performance when addressing speech signals created by unseen synthesizers. In this paper, we propose a robust deepfake speech detection method that employs feature decomposition to learn synthesizer-independent content features as complementary for detection. Specifically, we propose a dual-stream feature decomposition learning strategy that decomposes the learned speech representation using a synthesizer stream and a content stream. The synthesizer stream specializes in learning synthesizer features through supervised training with synthesizer labels. Meanwhile, the content stream focuses on learning synthesizer-independent content features, enabled by a pseudo-labeling-based supervised learning method. This method randomly transforms speech to generate speed and compression labels for training. Additionally, we employ an adversarial learning technique to reduce the synthesizer-related components in the content stream. The final classification is determined by concatenating the synthesizer and content features. To enhance the model's robustness to different synthesizer characteristics, we further propose a synthesizer feature augmentation strategy that randomly blends the characteristic styles within real and fake audio features and randomly shuffles the synthesizer features with the content features. This strategy effectively enhances the feature diversity and simulates more feature combinations.
Uformer-ICS: A Specialized U-Shaped Transformer for Image Compressive Sensing
Sep 05, 2022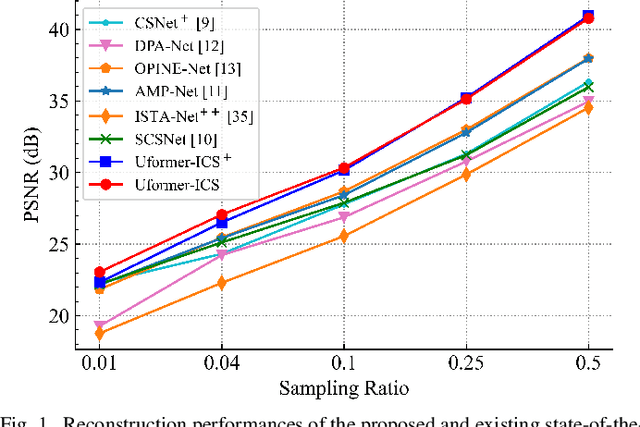
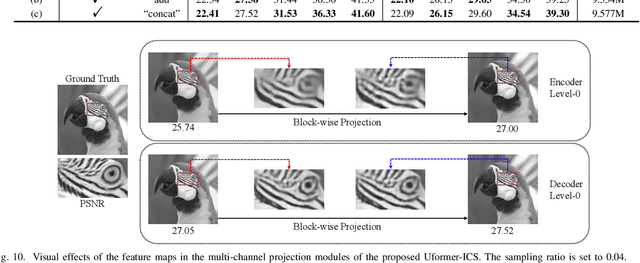
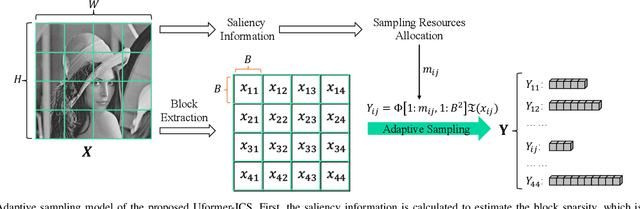

Recently, several studies have applied deep convolutional neural networks (CNNs) in image compressive sensing (CS) tasks to improve reconstruction quality. However, convolutional layers generally have a small receptive field; therefore, capturing long-range pixel correlations using CNNs is challenging, which limits their reconstruction performance in image CS tasks. Considering this limitation, we propose a U-shaped transformer for image CS tasks, called the Uformer-ICS. We develop a projection-based transformer block by integrating the prior projection knowledge of CS into the original transformer blocks, and then build a symmetrical reconstruction model using the projection-based transformer blocks and residual convolutional blocks. Compared with previous CNN-based CS methods that can only exploit local image features, the proposed reconstruction model can simultaneously utilize the local features and long-range dependencies of an image, and the prior projection knowledge of the CS theory. Additionally, we design an adaptive sampling model that can adaptively sample image blocks based on block sparsity, which can ensure that the compressed results retain the maximum possible information of the original image under a fixed sampling ratio. The proposed Uformer-ICS is an end-to-end framework that simultaneously learns the sampling and reconstruction processes. Experimental results demonstrate that it achieves significantly better reconstruction performance than existing state-of-the-art deep learning-based CS methods.