 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Semantic Logic Gaps: A Cognition-Inspired Multimodal Boundary-Preserving Network for Image Manipulation Localization
Aug 10, 2025The existing image manipulation localization (IML) models mainly relies on visual cues, but ignores the semantic logical relationships between content features. In fact, the content semantics conveyed by real images often conform to human cognitive laws. However, image manipulation technology usually destroys the internal relationship between content features, thus leaving semantic clues for IML. In this paper, we propose a cognition-inspired multimodal boundary-preserving network (CMB-Net). Specifically, CMB-Net utilizes large language models (LLMs) to analyze manipulated regions within images and generate prompt-based textual information to compensate for the lack of semantic relationships in the visual information. Considering that the erroneous texts induced by hallucination from LLMs will damage the accuracy of IML, we propose an image-text central ambiguity module (ITCAM). It assigns weights to the text features by quantifying the ambiguity between text and image features, thereby ensuring the beneficial impact of textual information. We also propose an image-text interaction module (ITIM) that aligns visual and text features using a correlation matrix for fine-grained interaction. Finally, inspired by invertible neural networks, we propose a restoration edge decoder (RED) that mutually generates input and output features to preserve boundary information in manipulated regions without loss. Extensive experiments show that CMB-Net outperforms most existing IML models.
Deep Robust Reversible Watermarking
Mar 04, 2025



Robust Reversible Watermarking (RRW) enables perfect recovery of cover images and watermarks in lossless channels while ensuring robust watermark extraction in lossy channels. Existing RRW methods, mostly non-deep learning-based, face complex designs, high computational costs, and poor robustness, limiting their practical use. This paper proposes Deep Robust Reversible Watermarking (DRRW), a deep learning-based RRW scheme. DRRW uses an Integer Invertible Watermark Network (iIWN) to map integer data distributions invertibly, addressing conventional RRW limitations. Unlike traditional RRW, which needs distortion-specific designs, DRRW employs an encoder-noise layer-decoder framework for adaptive robustness via end-to-end training. In inference, cover image and watermark map to an overflowed stego image and latent variables, compressed by arithmetic coding into a bitstream embedded via reversible data hiding for lossless recovery. We introduce an overflow penalty loss to reduce pixel overflow, shortening the auxiliary bitstream while enhancing robustness and stego image quality. An adaptive weight adjustment strategy avoids manual watermark loss weighting, improving training stability and performance. Experiments show DRRW outperforms state-of-the-art RRW methods, boosting robustness and cutting embedding, extraction, and recovery complexities by 55.14\(\times\), 5.95\(\times\), and 3.57\(\times\), respectively. The auxiliary bitstream shrinks by 43.86\(\times\), with reversible embedding succeeding on 16,762 PASCAL VOC 2012 images, advancing practical RRW. DRRW exceeds irreversible robust watermarking in robustness and quality while maintaining reversibility.
Deferred Poisoning: Making the Model More Vulnerable via Hessian Singularization
Nov 06, 2024Recent studies have shown that deep learning models are very vulnerable to poisoning attacks. Many defense methods have been proposed to address this issue. However, traditional poisoning attacks are not as threatening as commonly believed. This is because they often cause differences in how the model performs on the training set compared to the validation set. Such inconsistency can alert defenders that their data has been poisoned, allowing them to take the necessary defensive actions. In this paper, we introduce a more threatening type of poisoning attack called the Deferred Poisoning Attack. This new attack allows the model to function normally during the training and validation phases but makes it very sensitive to evasion attacks or even natural noise. We achieve this by ensuring the poisoned model's loss function has a similar value as a normally trained model at each input sample but with a large local curvature. A similar model loss ensures that there is no obvious inconsistency between the training and validation accuracy, demonstrating high stealthiness. On the other hand, the large curvature implies that a small perturbation may cause a significant increase in model loss, leading to substantial performance degradation, which reflects a worse robustness. We fulfill this purpose by making the model have singular Hessian information at the optimal point via our proposed Singularization Regularization term. We have conducted both theoretical and empirical analyses of the proposed method and validated its effectiveness through experiments on image classification tasks. Furthermore, we have confirmed the hazards of this form of poisoning attack under more general scenarios using natural noise, offering a new perspective for research in the field of security.
Text-Driven Traffic Anomaly Detection with Temporal High-Frequency Modeling in Driving Videos
Jan 07, 2024Traffic anomaly detection (TAD) in driving videos is critical for ensuring the safety of autonomous driving and advanced driver assistance systems. Previous single-stage TAD methods primarily rely on frame prediction, making them vulnerable to interference from dynamic backgrounds induced by the rapid movement of the dashboard camera. While two-stage TAD methods appear to be a natural solution to mitigate such interference by pre-extracting background-independent features (such as bounding boxes and optical flow) using perceptual algorithms, they are susceptible to the performance of first-stage perceptual algorithms and may result in error propagation. In this paper, we introduce TTHF, a novel single-stage method aligning video clips with text prompts, offering a new perspective on traffic anomaly detection. Unlike previous approaches, the supervised signal of our method is derived from languages rather than orthogonal one-hot vectors, providing a more comprehensive representation. Further, concerning visual representation, we propose to model the high frequency of driving videos in the temporal domain. This modeling captures the dynamic changes of driving scenes, enhances the perception of driving behavior, and significantly improves the detection of traffic anomalies. In addition, to better perceive various types of traffic anomalies, we carefully design an attentive anomaly focusing mechanism that visually and linguistically guides the model to adaptively focus on the visual context of interest, thereby facilitating the detection of traffic anomalies. It is shown that our proposed TTHF achieves promising performance, outperforming state-of-the-art competitors by +5.4% AUC on the DoTA dataset and achieving high generalization on the DADA dataset.
Multi-scale Target-Aware Framework for Constrained Image Splicing Detection and Localization
Aug 21, 2023Constrained image splicing detection and localization (CISDL) is a fundamental task of multimedia forensics, which detects splicing operation between two suspected images and localizes the spliced region on both images. Recent works regard it as a deep matching problem and have made significant progress. However, existing frameworks typically perform feature extraction and correlation matching as separate processes, which may hinder the model's ability to learn discriminative features for matching and can be susceptible to interference from ambiguous background pixels. In this work, we propose a multi-scale target-aware framework to couple feature extraction and correlation matching in a unified pipeline. In contrast to previous methods, we design a target-aware attention mechanism that jointly learns features and performs correlation matching between the probe and donor images. Our approach can effectively promote the collaborative learning of related patches, and perform mutual promotion of feature learning and correlation matching. Additionally, in order to handle scale transformations, we introduce a multi-scale projection method, which can be readily integrated into our target-aware framework that enables the attention process to be conducted between tokens containing information of varying scales. Our experiments demonstrate that our model, which uses a unified pipeline, outperforms state-of-the-art methods on several benchmark datasets and is robust against scale transformations.
Image Copy-Move Forgery Detection via Deep Cross-Scale PatchMatch
Aug 08, 2023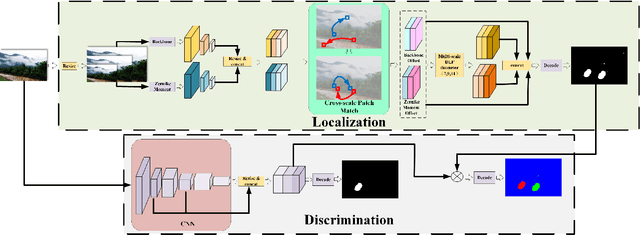
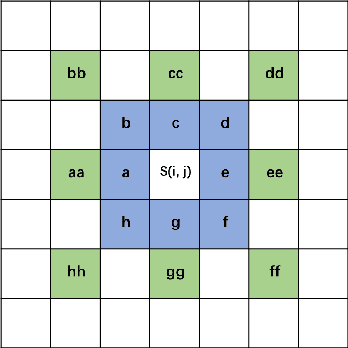
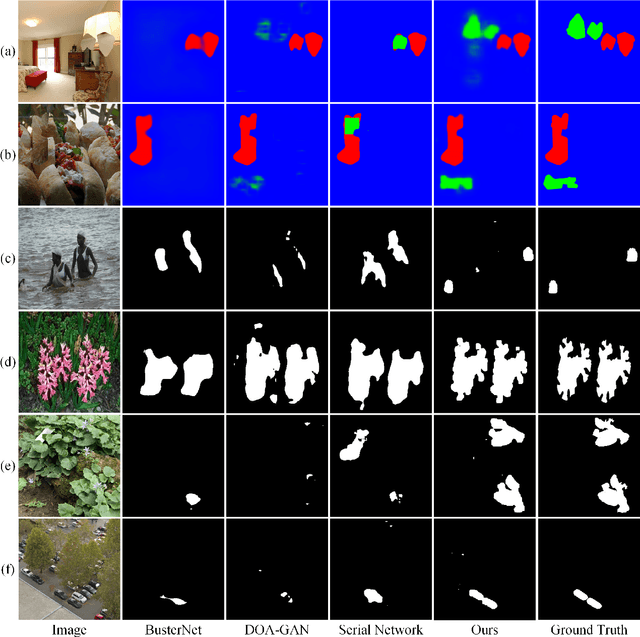
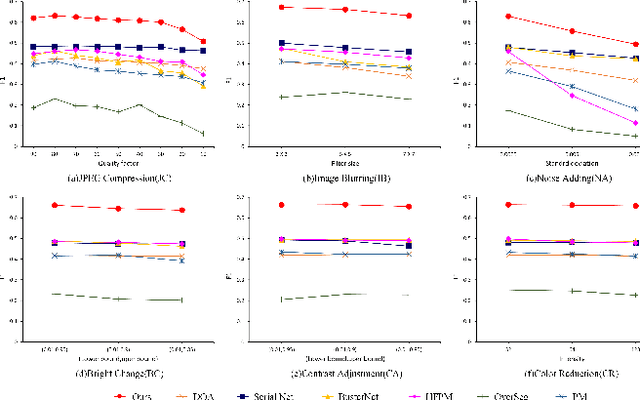
The recently developed deep algorithms achieve promising progress in the field of image copy-move forgery detection (CMFD). However, they have limited generalizability in some practical scenarios, where the copy-move objects may not appear in the training images or cloned regions are from the background. To address the above issues, in this work, we propose a novel end-to-end CMFD framework by integrating merits from both conventional and deep methods. Specifically, we design a deep cross-scale patchmatch method tailored for CMFD to localize copy-move regions. In contrast to existing deep models, our scheme aims to seek explicit and reliable point-to-point matching between source and target regions using features extracted from high-resolution scales. Further, we develop a manipulation region location branch for source/target separation. The proposed CMFD framework is completely differentiable and can be trained in an end-to-end manner. Extensive experimental results demonstrate the high generalizability of our method to different copy-move contents, and the proposed scheme achieves significantly better performance than existing approaches.
A Memory-Augmented Multi-Task Collaborative Framework for Unsupervised Traffic Accident Detection in Driving Videos
Jul 27, 2023



Identifying traffic accidents in driving videos is crucial to ensuring the safety of autonomous driving and driver assistance systems. To address the potential danger caused by the long-tailed distribution of driving events, existing traffic accident detection (TAD) methods mainly rely on unsupervised learning. However, TAD is still challenging due to the rapid movement of cameras and dynamic scenes in driving scenarios. Existing unsupervised TAD methods mainly rely on a single pretext task, i.e., an appearance-based or future object localization task, to detect accidents. However, appearance-based approaches are easily disturbed by the rapid movement of the camera and changes in illumination, which significantly reduce the performance of traffic accident detection. Methods based on future object localization may fail to capture appearance changes in video frames, making it difficult to detect ego-involved accidents (e.g., out of control of the ego-vehicle). In this paper, we propose a novel memory-augmented multi-task collaborative framework (MAMTCF) for unsupervised traffic accident detection in driving videos. Different from previous approaches, our method can more accurately detect both ego-involved and non-ego accidents by simultaneously modeling appearance changes and object motions in video frames through the collaboration of optical flow reconstruction and future object localization tasks. Further, we introduce a memory-augmented motion representation mechanism to fully explore the interrelation between different types of motion representations and exploit the high-level features of normal traffic patterns stored in memory to augment motion representations, thus enlarging the difference from anomalies. Experimental results on recently published large-scale dataset demonstrate that our method achieves better performance compared to previous state-of-the-art approaches.
STGlow: A Flow-based Generative Framework with Dual Graphormer for Pedestrian Trajectory Prediction
Nov 22, 2022Pedestrian trajectory prediction task is an essential component of intelligent systems, and its applications include but are not limited to autonomous driving, robot navigation, and anomaly detection of monitoring systems. Due to the diversity of motion behaviors and the complex social interactions among pedestrians, accurately forecasting the future trajectory of pedestrians is challenging. Existing approaches commonly adopt GANs or CVAEs to generate diverse trajectories. However, GAN-based methods do not directly model data in a latent space, which makes them fail to have full support over the underlying data distribution; CVAE-based methods optimize a lower bound on the log-likelihood of observations, causing the learned distribution to deviate from the underlying distribution. The above limitations make existing approaches often generate highly biased or unnatural trajectories. In this paper, we propose a novel generative flow based framework with dual graphormer for pedestrian trajectory prediction (STGlow). Different from previous approaches, our method can more accurately model the underlying data distribution by optimizing the exact log-likelihood of motion behaviors. Besides, our method has clear physical meanings to simulate the evolution of human motion behaviors, where the forward process of the flow gradually degrades the complex motion behavior into a simple behavior, while its reverse process represents the evolution of a simple behavior to the complex motion behavior. Further, we introduce a dual graphormer combining with the graph structure to more adequately model the temporal dependencies and the mutual spatial interactions. Experimental results on several benchmarks demonstrate that our method achieves much better performance compared to previous state-of-the-art approaches.
Uformer-ICS: A Specialized U-Shaped Transformer for Image Compressive Sensing
Sep 05, 2022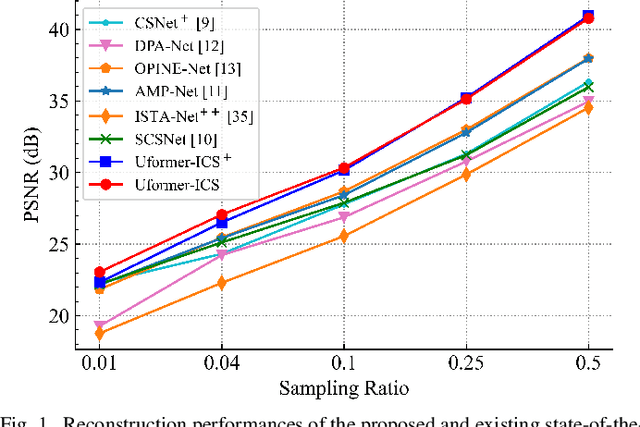
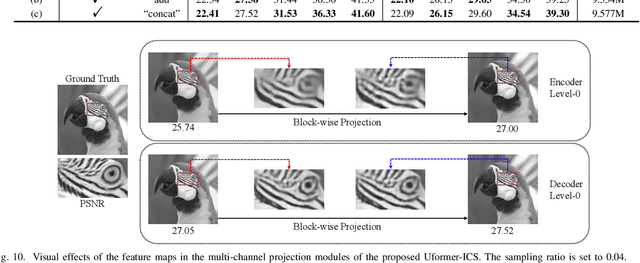
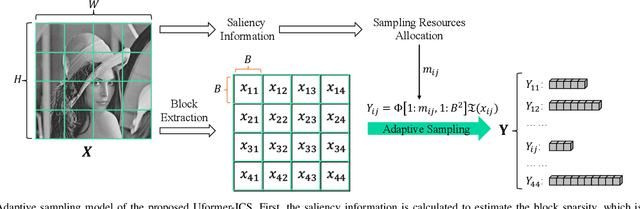

Recently, several studies have applied deep convolutional neural networks (CNNs) in image compressive sensing (CS) tasks to improve reconstruction quality. However, convolutional layers generally have a small receptive field; therefore, capturing long-range pixel correlations using CNNs is challenging, which limits their reconstruction performance in image CS tasks. Considering this limitation, we propose a U-shaped transformer for image CS tasks, called the Uformer-ICS. We develop a projection-based transformer block by integrating the prior projection knowledge of CS into the original transformer blocks, and then build a symmetrical reconstruction model using the projection-based transformer blocks and residual convolutional blocks. Compared with previous CNN-based CS methods that can only exploit local image features, the proposed reconstruction model can simultaneously utilize the local features and long-range dependencies of an image, and the prior projection knowledge of the CS theory. Additionally, we design an adaptive sampling model that can adaptively sample image blocks based on block sparsity, which can ensure that the compressed results retain the maximum possible information of the original image under a fixed sampling ratio. The proposed Uformer-ICS is an end-to-end framework that simultaneously learns the sampling and reconstruction processes. Experimental results demonstrate that it achieves significantly better reconstruction performance than existing state-of-the-art deep learning-based CS methods.
Video Salient Object Detection via Adaptive Local-Global Refinement
May 12, 2021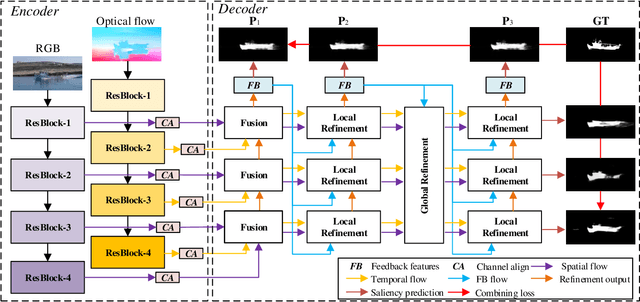
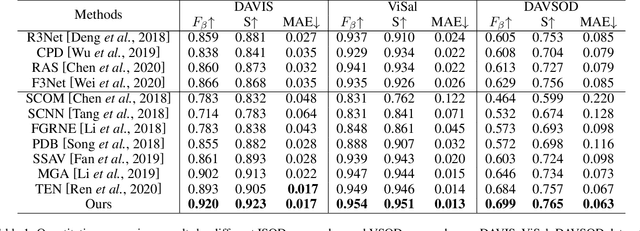
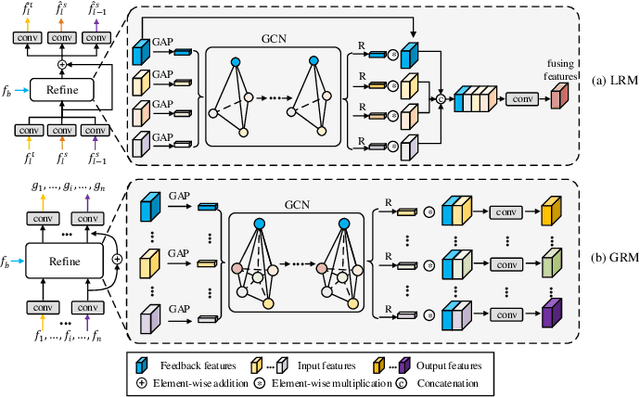

Video salient object detection (VSOD) is an important task in many vision applications. Reliable VSOD requires to simultaneously exploit the information from both the spatial domain and the temporal domain. Most of the existing algorithms merely utilize simple fusion strategies, such as addition and concatenation, to merge the information from different domains. Despite their simplicity, such fusion strategies may introduce feature redundancy, and also fail to fully exploit the relationship between multi-level features extracted from both spatial and temporal domains. In this paper, we suggest an adaptive local-global refinement framework for VSOD. Different from previous approaches, we propose a local refinement architecture and a global one to refine the simply fused features with different scopes, which can fully explore the local dependence and the global dependence of multi-level features. In addition, to emphasize the effective information and suppress the useless one, an adaptive weighting mechanism is designed based on graph convolutional neural network (GCN). We show that our weighting methodology can further exploit the feature correlations, thus driving the network to learn more discriminative feature representation. Extensive experimental results on public video datasets demonstrate the superiority of our method over the existing ones.