 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Malicious Concepts Without Image Generation in AIGC
Feb 13, 2025The task of text-to-image generation has achieved tremendous success in practice, with emerging concept generation models capable of producing highly personalized and customized content. Fervor for concept generation is increasing rapidly among users, and platforms for concept sharing have sprung up. The concept owners may upload malicious concepts and disguise them with non-malicious text descriptions and example images to deceive users into downloading and generating malicious content. The platform needs a quick method to determine whether a concept is malicious to prevent the spread of malicious concepts. However, simply relying on concept image generation to judge whether a concept is malicious requires time and computational resources. Especially, as the number of concepts uploaded and downloaded on the platform continues to increase, this approach becomes impractical and poses a risk of generating malicious content. In this paper, we propose Concept QuickLook, the first systematic work to incorporate malicious concept detection into research, which performs detection based solely on concept files without generating any images. We define malicious concepts and design two work modes for detection: concept matching and fuzzy detection. Extensive experiments demonstrate that the proposed Concept QuickLook can detect malicious concepts and demonstrate practicality in concept sharing platforms. We also design robustness experiments to further validate the effectiveness of the solution. We hope this work can initiate malicious concept detection tasks and provide some inspiration.
Phoneme-Level Feature Discrepancies: A Key to Detecting Sophisticated Speech Deepfakes
Dec 17, 2024



Recent advancements in text-to-speech and speech conversion technologies have enabled the creation of highly convincing synthetic speech. While these innovations offer numerous practical benefits, they also cause significant security challenges when maliciously misused. Therefore, there is an urgent need to detect these synthetic speech signals. Phoneme features provide a powerful speech representation for deepfake detection. However, previous phoneme-based detection approaches typically focused on specific phonemes, overlooking temporal inconsistencies across the entire phoneme sequence. In this paper, we develop a new mechanism for detecting speech deepfakes by identifying the inconsistencies of phoneme-level speech features. We design an adaptive phoneme pooling technique that extracts sample-specific phoneme-level features from frame-level speech data. By applying this technique to features extracted by pre-trained audio models on previously unseen deepfake datasets, we demonstrate that deepfake samples often exhibit phoneme-level inconsistencies when compared to genuine speech. To further enhance detection accuracy, we propose a deepfake detector that uses a graph attention network to model the temporal dependencies of phoneme-level features. Additionally, we introduce a random phoneme substitution augmentation technique to increase feature diversity during training. Extensive experiments on four benchmark datasets demonstrate the superior performance of our method over existing state-of-the-art detection methods.
Robust AI-Synthesized Speech Detection Using Feature Decomposition Learning and Synthesizer Feature Augmentation
Nov 14, 2024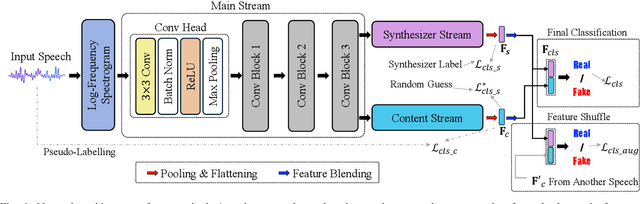
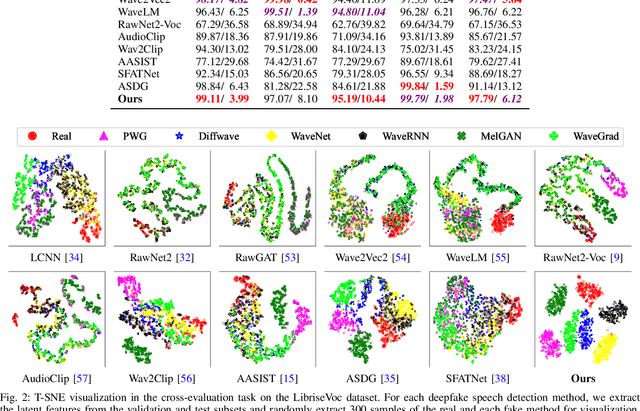
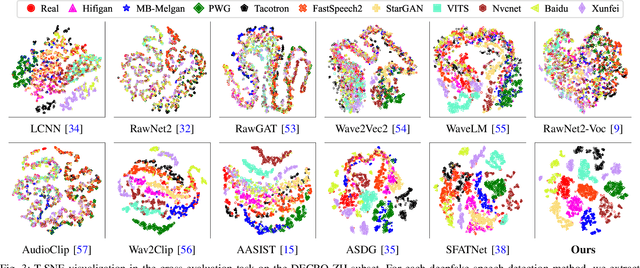
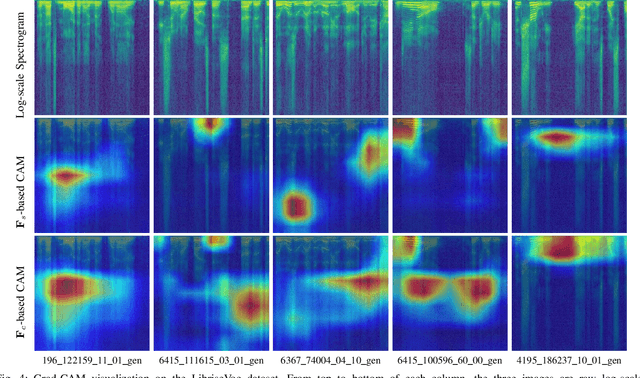
AI-synthesized speech, also known as deepfake speech, has recently raised significant concerns due to the rapid advancement of speech synthesis and speech conversion techniques. Previous works often rely on distinguishing synthesizer artifacts to identify deepfake speech. However, excessive reliance on these specific synthesizer artifacts may result in unsatisfactory performance when addressing speech signals created by unseen synthesizers. In this paper, we propose a robust deepfake speech detection method that employs feature decomposition to learn synthesizer-independent content features as complementary for detection. Specifically, we propose a dual-stream feature decomposition learning strategy that decomposes the learned speech representation using a synthesizer stream and a content stream. The synthesizer stream specializes in learning synthesizer features through supervised training with synthesizer labels. Meanwhile, the content stream focuses on learning synthesizer-independent content features, enabled by a pseudo-labeling-based supervised learning method. This method randomly transforms speech to generate speed and compression labels for training. Additionally, we employ an adversarial learning technique to reduce the synthesizer-related components in the content stream. The final classification is determined by concatenating the synthesizer and content features. To enhance the model's robustness to different synthesizer characteristics, we further propose a synthesizer feature augmentation strategy that randomly blends the characteristic styles within real and fake audio features and randomly shuffles the synthesizer features with the content features. This strategy effectively enhances the feature diversity and simulates more feature combinations.
Hierarchical Invariance for Robust and Interpretable Vision Tasks at Larger Scales
Feb 23, 2024
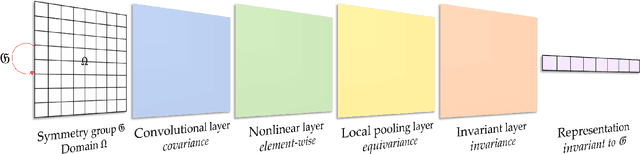
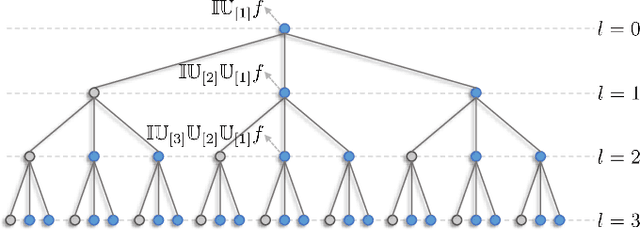
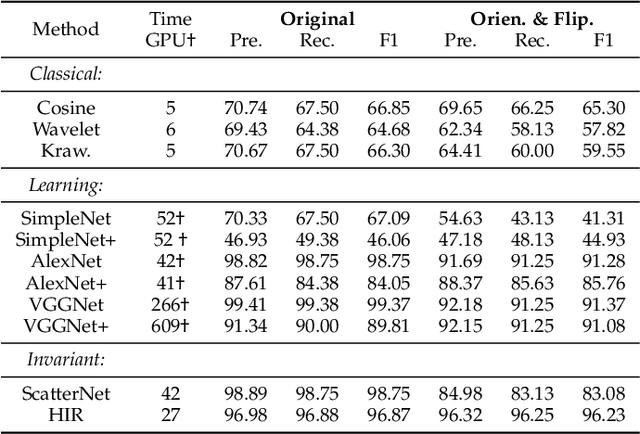
Developing robust and interpretable vision systems is a crucial step towards trustworthy artificial intelligence. In this regard, a promising paradigm considers embedding task-required invariant structures, e.g., geometric invariance, in the fundamental image representation. However, such invariant representations typically exhibit limited discriminability, limiting their applications in larger-scale trustworthy vision tasks. For this open problem, we conduct a systematic investigation of hierarchical invariance, exploring this topic from theoretical, practical, and application perspectives. At the theoretical level, we show how to construct over-complete invariants with a Convolutional Neural Networks (CNN)-like hierarchical architecture yet in a fully interpretable manner. The general blueprint, specific definitions, invariant properties, and numerical implementations are provided. At the practical level, we discuss how to customize this theoretical framework into a given task. With the over-completeness, discriminative features w.r.t. the task can be adaptively formed in a Neural Architecture Search (NAS)-like manner. We demonstrate the above arguments with accuracy, invariance, and efficiency results on texture, digit, and parasite classification experiments. Furthermore, at the application level, our representations are explored in real-world forensics tasks on adversarial perturbations and Artificial Intelligence Generated Content (AIGC). Such applications reveal that the proposed strategy not only realizes the theoretically promised invariance, but also exhibits competitive discriminability even in the era of deep learning. For robust and interpretable vision tasks at larger scales, hierarchical invariant representation can be considered as an effective alternative to traditional CNN and invariants.
Turn Passive to Active: A Survey on Active Intellectual Property Protection of Deep Learning Models
Oct 15, 2023The intellectual property protection of deep learning (DL) models has attracted increasing serious concerns. Many works on intellectual property protection for Deep Neural Networks (DNN) models have been proposed. The vast majority of existing work uses DNN watermarking to verify the ownership of the model after piracy occurs, which is referred to as passive verification. On the contrary, we focus on a new type of intellectual property protection method named active copyright protection, which refers to active authorization control and user identity management of the DNN model. As of now, there is relatively limited research in the field of active DNN copyright protection. In this review, we attempt to clearly elaborate on the connotation, attributes, and requirements of active DNN copyright protection, provide evaluation methods and metrics for active copyright protection, review and analyze existing work on active DL model intellectual property protection, discuss potential attacks that active DL model copyright protection techniques may face, and provide challenges and future directions for active DL model intellectual property protection. This review is helpful to systematically introduce the new field of active DNN copyright protection and provide reference and foundation for subsequent work.
Seeing is not Believing: An Identity Hider for Human Vision Privacy Protection
Jul 06, 2023Massive captured face images are stored in the database for the identification of individuals. However, the stored images can be observed intentionally or unintentionally by data managers, which is not at the will of individuals and may cause privacy violations. Existing protection works only slightly change the visual content of the face while maintaining the utility of identification, making it susceptible to the inference of the true identity by human vision. In this paper, we propose an identity hider that enables significant visual content change for human vision while preserving high identifiability for face recognizers. Firstly, the identity hider generates a virtual face with new visual content by manipulating the latent space in StyleGAN2. In particular, the virtual face has the same irrelevant attributes as the original face, e.g., pose and expression. Secondly, the visual content of the virtual face is transferred into the original face and then the background is replaced with the original one. In addition, the identity hider has strong transferability, which ensures an arbitrary face recognizer can achieve satisfactory accuracy. Adequate experiments show that the proposed identity hider achieves excellent performance on privacy protection and identifiability preservation.
Towards an Accurate and Secure Detector against Adversarial Perturbations
May 18, 2023The vulnerability of deep neural networks to adversarial perturbations has been widely perceived in the computer vision community. From a security perspective, it poses a critical risk for modern vision systems, e.g., the popular Deep Learning as a Service (DLaaS) frameworks. For protecting off-the-shelf deep models while not modifying them, current algorithms typically detect adversarial patterns through discriminative decomposition of natural-artificial data. However, these decompositions are biased towards frequency or spatial discriminability, thus failing to capture subtle adversarial patterns comprehensively. More seriously, they are typically invertible, meaning successful defense-aware (secondary) adversarial attack (i.e., evading the detector as well as fooling the model) is practical under the assumption that the adversary is fully aware of the detector (i.e., the Kerckhoffs's principle). Motivated by such facts, we propose an accurate and secure adversarial example detector, relying on a spatial-frequency discriminative decomposition with secret keys. It expands the above works on two aspects: 1) the introduced Krawtchouk basis provides better spatial-frequency discriminability and thereby is more suitable for capturing adversarial patterns than the common trigonometric or wavelet basis; 2) the extensive parameters for decomposition are generated by a pseudo-random function with secret keys, hence blocking the defense-aware adversarial attack. Theoretical and numerical analysis demonstrates the increased accuracy and security of our detector w.r.t. a number of state-of-the-art algorithms.
Representing Noisy Image Without Denoising
Jan 18, 2023A long-standing topic in artificial intelligence is the effective recognition of patterns from noisy images. In this regard, the recent data-driven paradigm considers 1) improving the representation robustness by adding noisy samples in training phase (i.e., data augmentation) or 2) pre-processing the noisy image by learning to solve the inverse problem (i.e., image denoising). However, such methods generally exhibit inefficient process and unstable result, limiting their practical applications. In this paper, we explore a non-learning paradigm that aims to derive robust representation directly from noisy images, without the denoising as pre-processing. Here, the noise-robust representation is designed as Fractional-order Moments in Radon space (FMR), with also beneficial properties of orthogonality and rotation invariance. Unlike earlier integer-order methods, our work is a more generic design taking such classical methods as special cases, and the introduced fractional-order parameter offers time-frequency analysis capability that is not available in classical methods. Formally, both implicit and explicit paths for constructing the FMR are discussed in detail. Extensive simulation experiments and an image security application are provided to demonstrate the uniqueness and usefulness of our FMR, especially for noise robustness, rotation invariance, and time-frequency discriminability.
InFIP: An Explainable DNN Intellectual Property Protection Method based on Intrinsic Features
Oct 14, 2022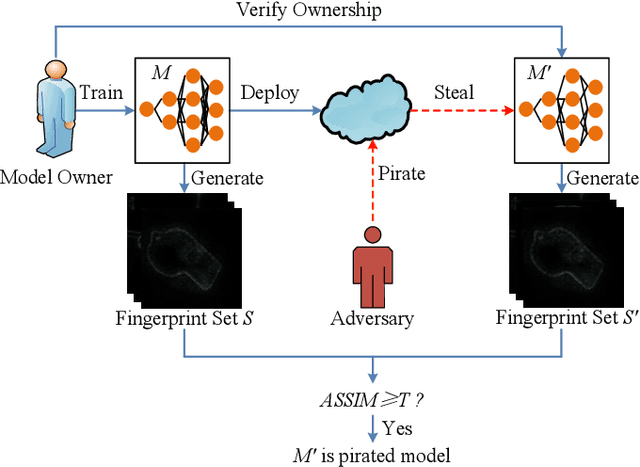
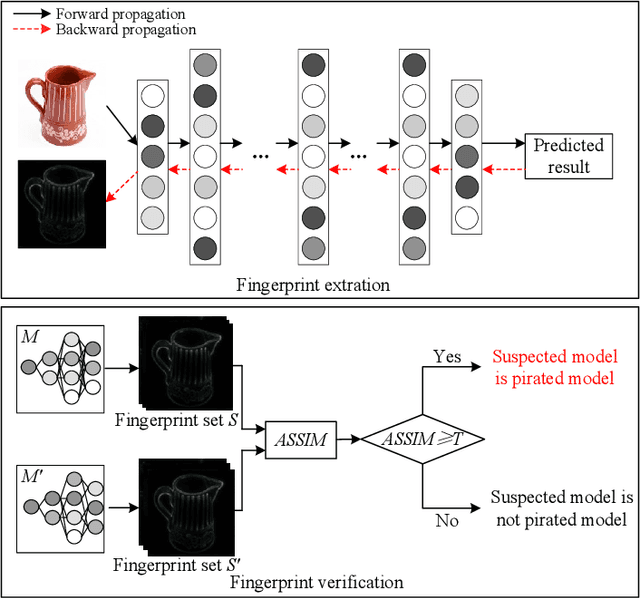
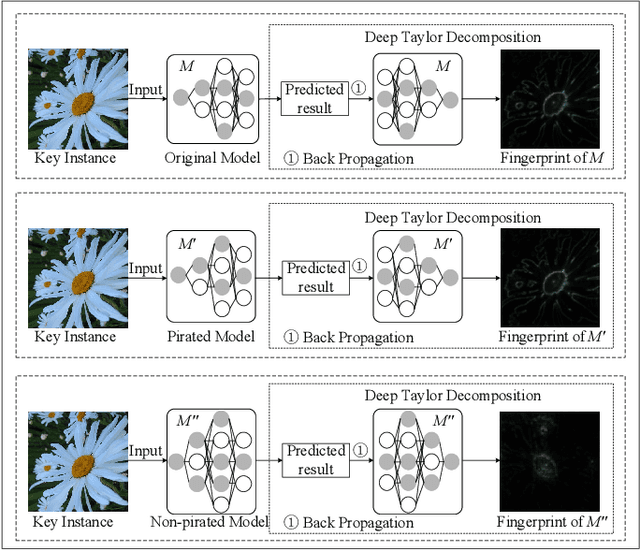

Intellectual property (IP) protection for Deep Neural Networks (DNNs) has raised serious concerns in recent years. Most existing works embed watermarks in the DNN model for IP protection, which need to modify the model and lack of interpretability. In this paper, for the first time, we propose an interpretable intellectual property protection method for DNN based on explainable artificial intelligence. Compared with existing works, the proposed method does not modify the DNN model, and the decision of the ownership verification is interpretable. We extract the intrinsic features of the DNN model by using Deep Taylor Decomposition. Since the intrinsic feature is composed of unique interpretation of the model's decision, the intrinsic feature can be regarded as fingerprint of the model. If the fingerprint of a suspected model is the same as the original model, the suspected model is considered as a pirated model. Experimental results demonstrate that the fingerprints can be successfully used to verify the ownership of the model and the test accuracy of the model is not affected. Furthermore, the proposed method is robust to fine-tuning attack, pruning attack, watermark overwriting attack, and adaptive attack.
Uformer-ICS: A Specialized U-Shaped Transformer for Image Compressive Sensing
Sep 05, 2022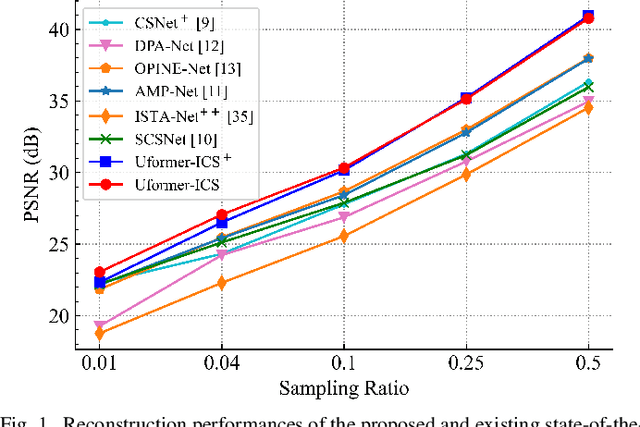
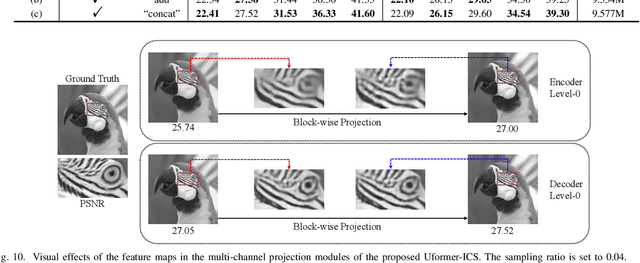
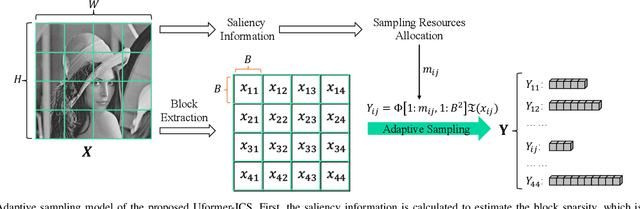

Recently, several studies have applied deep convolutional neural networks (CNNs) in image compressive sensing (CS) tasks to improve reconstruction quality. However, convolutional layers generally have a small receptive field; therefore, capturing long-range pixel correlations using CNNs is challenging, which limits their reconstruction performance in image CS tasks. Considering this limitation, we propose a U-shaped transformer for image CS tasks, called the Uformer-ICS. We develop a projection-based transformer block by integrating the prior projection knowledge of CS into the original transformer blocks, and then build a symmetrical reconstruction model using the projection-based transformer blocks and residual convolutional blocks. Compared with previous CNN-based CS methods that can only exploit local image features, the proposed reconstruction model can simultaneously utilize the local features and long-range dependencies of an image, and the prior projection knowledge of the CS theory. Additionally, we design an adaptive sampling model that can adaptively sample image blocks based on block sparsity, which can ensure that the compressed results retain the maximum possible information of the original image under a fixed sampling ratio. The proposed Uformer-ICS is an end-to-end framework that simultaneously learns the sampling and reconstruction processes. Experimental results demonstrate that it achieves significantly better reconstruction performance than existing state-of-the-art deep learning-based CS methods.