 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCI-Net: A Robust Multi-Domain Context Integration Network for Point Cloud Registration
Dec 29, 2025Robust and discriminative feature learning is critical for high-quality point cloud registration. However, existing deep learning-based methods typically rely on Euclidean neighborhood-based strategies for feature extraction, which struggle to effectively capture the implicit semantics and structural consistency in point clouds. To address these issues, we propose a multi-domain context integration network (MCI-Net) that improves feature representation and registration performance by aggregating contextual cues from diverse domains. Specifically, we propose a graph neighborhood aggregation module, which constructs a global graph to capture the overall structural relationships within point clouds. We then propose a progressive context interaction module to enhance feature discriminability by performing intra-domain feature decoupling and inter-domain context interaction. Finally, we design a dynamic inlier selection method that optimizes inlier weights using residual information from multiple iterations of pose estimation, thereby improving the accuracy and robustness of registration. Extensive experiments on indoor RGB-D and outdoor LiDAR datasets show that the proposed MCI-Net significantly outperforms existing state-of-the-art methods, achieving the highest registration recall of 96.4\% on 3DMatch. Source code is available at http://www.linshuyuan.com.
SC-Net: Robust Correspondence Learning via Spatial and Cross-Channel Context
Dec 29, 2025Recent research has focused on using convolutional neural networks (CNNs) as the backbones in two-view correspondence learning, demonstrating significant superiority over methods based on multilayer perceptrons. However, CNN backbones that are not tailored to specific tasks may fail to effectively aggregate global context and oversmooth dense motion fields in scenes with large disparity. To address these problems, we propose a novel network named SC-Net, which effectively integrates bilateral context from both spatial and channel perspectives. Specifically, we design an adaptive focused regularization module (AFR) to enhance the model's position-awareness and robustness against spurious motion samples, thereby facilitating the generation of a more accurate motion field. We then propose a bilateral field adjustment module (BFA) to refine the motion field by simultaneously modeling long-range relationships and facilitating interaction across spatial and channel dimensions. Finally, we recover the motion vectors from the refined field using a position-aware recovery module (PAR) that ensures consistency and precision. Extensive experiments demonstrate that SC-Net outperforms state-of-the-art methods in relative pose estimation and outlier removal tasks on YFCC100M and SUN3D datasets. Source code is available at http://www.linshuyuan.com.
DPUV4E: High-Throughput DPU Architecture Design for CNN on Versal ACAP
Jun 13, 2025Convolutional Neural Networks (CNNs) remain prevalent in computer vision applications, and FPGAs, known for their flexibility and energy efficiency, have become essential components in heterogeneous acceleration systems. However, traditional FPGAs face challenges in balancing performance and versatility due to limited on-chip resources. AMD's Versal ACAP architecture, tailored for AI applications, incorporates AI Engines (AIEs) to deliver high computational power. Nevertheless, the platform suffers from insufficient memory bandwidth, hindering the full utilization of the AIEs' theoretical performance. In this paper, we present DPUV4E for the Versal architecture, providing configurations ranging from 2PE ($32.6$ TOPS) to 8PE ($131.0$ TOPS). We design two computation units, Conv PE and DWC PE, to support different computational patterns. Each computation unit's data flow efficiently utilizes the data reuse opportunities to mitigate bandwidth bottlenecks. Additionally, we extend the functionality of each PE to utilize AIEs for non-convolutional operations, reducing resource overhead. Experiments on over 50 models show that compared to previous designs, our design provides $8.6\times$ the TOPS/W of traditional FPGA-based DPU designs, while reducing DSP usage by $95.8\%$, LUT usage by $44.7\%$, and latency to $68.5\%$ under single-batch conditions. For end-to-end inference, our design improving throughput by up to $2.2\times$ for depth-wise convolution models and up to $1.3\times$ for standard models.
Twin Trigger Generative Networks for Backdoor Attacks against Object Detection
Nov 23, 2024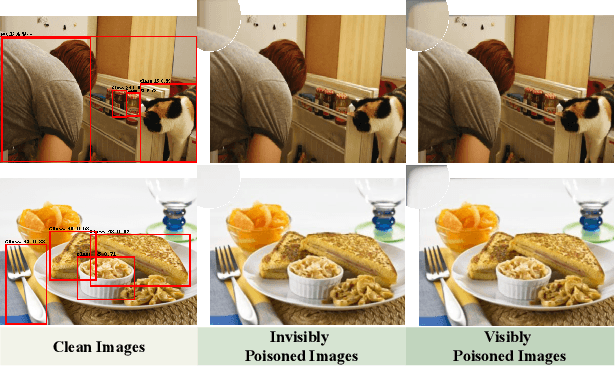
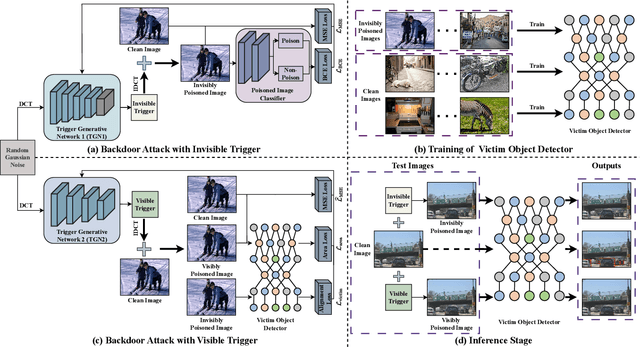
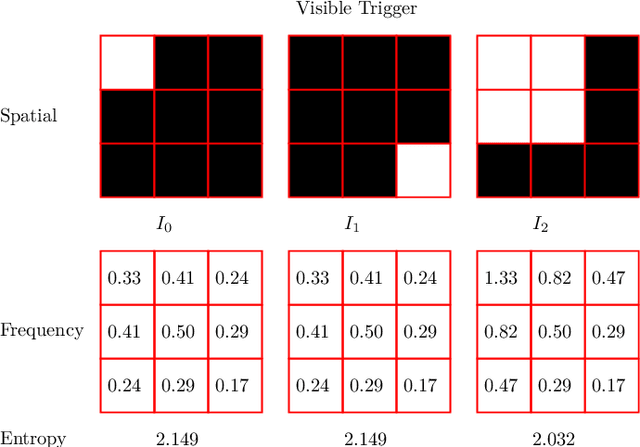
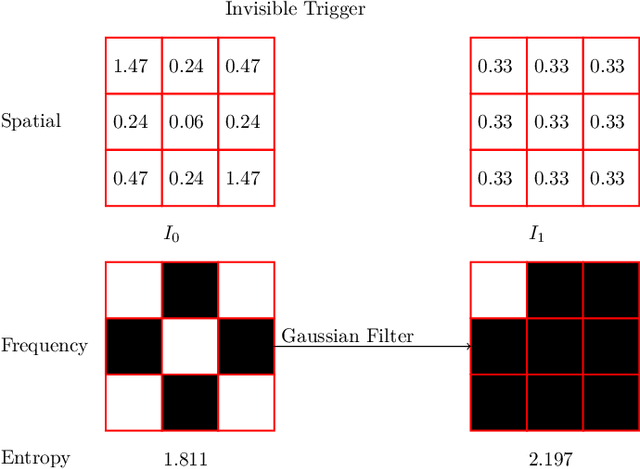
Object detectors, which are widely used in real-world applications, are vulnerable to backdoor attacks. This vulnerability arises because many users rely on datasets or pre-trained models provided by third parties due to constraints on data and resources. However, most research on backdoor attacks has focused on image classification, with limited investigation into object detection. Furthermore, the triggers for most existing backdoor attacks on object detection are manually generated, requiring prior knowledge and consistent patterns between the training and inference stages. This approach makes the attacks either easy to detect or difficult to adapt to various scenarios. To address these limitations, we propose novel twin trigger generative networks in the frequency domain to generate invisible triggers for implanting stealthy backdoors into models during training, and visible triggers for steady activation during inference, making the attack process difficult to trace. Specifically, for the invisible trigger generative network, we deploy a Gaussian smoothing layer and a high-frequency artifact classifier to enhance the stealthiness of backdoor implantation in object detectors. For the visible trigger generative network, we design a novel alignment loss to optimize the visible triggers so that they differ from the original patterns but still align with the malicious activation behavior of the invisible triggers. Extensive experimental results and analyses prove the possibility of using different triggers in the training stage and the inference stage, and demonstrate the attack effectiveness of our proposed visible trigger and invisible trigger generative networks, significantly reducing the mAP_0.5 of the object detectors by 70.0% and 84.5%, including YOLOv5 and YOLOv7 with different settings, respectively.
Towards Understanding and Enhancing Security of Proof-of-Training for DNN Model Ownership Verification
Oct 06, 2024



The great economic values of deep neural networks (DNNs) urge AI enterprises to protect their intellectual property (IP) for these models. Recently, proof-of-training (PoT) has been proposed as a promising solution to DNN IP protection, through which AI enterprises can utilize the record of DNN training process as their ownership proof. To prevent attackers from forging ownership proof, a secure PoT scheme should be able to distinguish honest training records from those forged by attackers. Although existing PoT schemes provide various distinction criteria, these criteria are based on intuitions or observations. The effectiveness of these criteria lacks clear and comprehensive analysis, resulting in existing schemes initially deemed secure being swiftly compromised by simple ideas. In this paper, we make the first move to identify distinction criteria in the style of formal methods, so that their effectiveness can be explicitly demonstrated. Specifically, we conduct systematic modeling to cover a wide range of attacks and then theoretically analyze the distinctions between honest and forged training records. The analysis results not only induce a universal distinction criterion, but also provide detailed reasoning to demonstrate its effectiveness in defending against attacks covered by our model. Guided by the criterion, we propose a generic PoT construction that can be instantiated into concrete schemes. This construction sheds light on the realization that trajectory matching algorithms, previously employed in data distillation, possess significant advantages in PoT construction. Experimental results demonstrate that our scheme can resist attacks that have compromised existing PoT schemes, which corroborates its superiority in security.
Towards Robust Knowledge Tracing Models via k-Sparse Attention
Jul 24, 2024
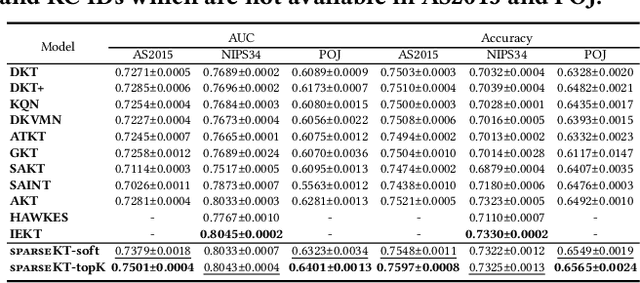
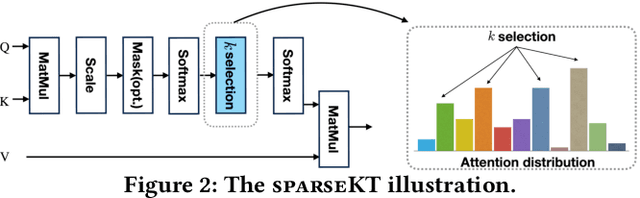
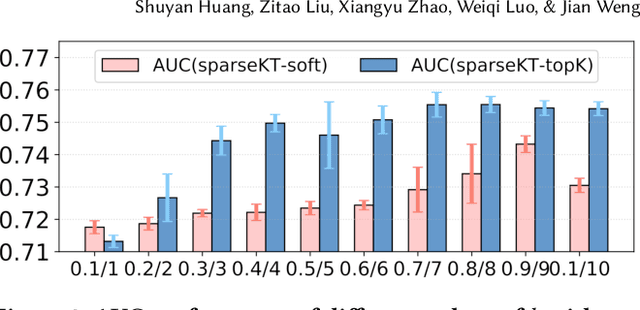
Knowledge tracing (KT) is the problem of predicting students' future performance based on their historical interaction sequences. With the advanced capability of capturing contextual long-term dependency, attention mechanism becomes one of the essential components in many deep learning based KT (DLKT) models. In spite of the impressive performance achieved by these attentional DLKT models, many of them are often vulnerable to run the risk of overfitting, especially on small-scale educational datasets. Therefore, in this paper, we propose \textsc{sparseKT}, a simple yet effective framework to improve the robustness and generalization of the attention based DLKT approaches. Specifically, we incorporate a k-selection module to only pick items with the highest attention scores. We propose two sparsification heuristics : (1) soft-thresholding sparse attention and (2) top-$K$ sparse attention. We show that our \textsc{sparseKT} is able to help attentional KT models get rid of irrelevant student interactions and have comparable predictive performance when compared to 11 state-of-the-art KT models on three publicly available real-world educational datasets. To encourage reproducible research, we make our data and code publicly available at \url{https://github.com/pykt-team/pykt-toolkit}\footnote{We merged our model to the \textsc{pyKT} benchmark at \url{https://pykt.org/}.}.
Hierarchical Invariance for Robust and Interpretable Vision Tasks at Larger Scales
Feb 23, 2024
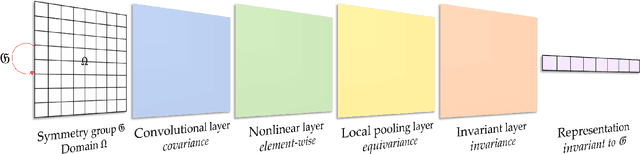
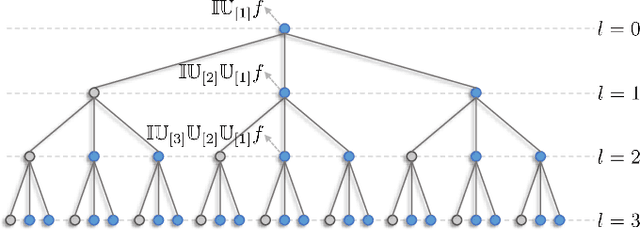
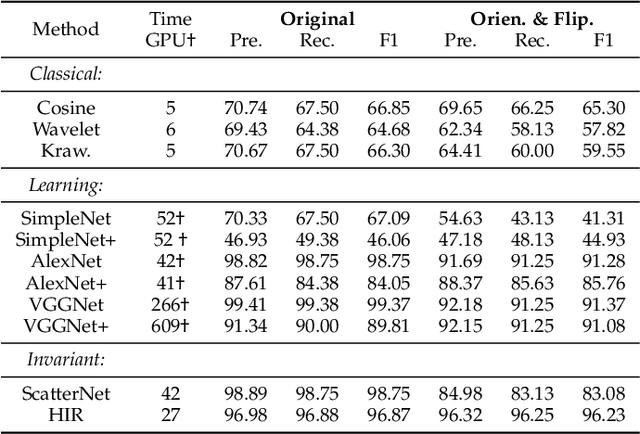
Developing robust and interpretable vision systems is a crucial step towards trustworthy artificial intelligence. In this regard, a promising paradigm considers embedding task-required invariant structures, e.g., geometric invariance, in the fundamental image representation. However, such invariant representations typically exhibit limited discriminability, limiting their applications in larger-scale trustworthy vision tasks. For this open problem, we conduct a systematic investigation of hierarchical invariance, exploring this topic from theoretical, practical, and application perspectives. At the theoretical level, we show how to construct over-complete invariants with a Convolutional Neural Networks (CNN)-like hierarchical architecture yet in a fully interpretable manner. The general blueprint, specific definitions, invariant properties, and numerical implementations are provided. At the practical level, we discuss how to customize this theoretical framework into a given task. With the over-completeness, discriminative features w.r.t. the task can be adaptively formed in a Neural Architecture Search (NAS)-like manner. We demonstrate the above arguments with accuracy, invariance, and efficiency results on texture, digit, and parasite classification experiments. Furthermore, at the application level, our representations are explored in real-world forensics tasks on adversarial perturbations and Artificial Intelligence Generated Content (AIGC). Such applications reveal that the proposed strategy not only realizes the theoretically promised invariance, but also exhibits competitive discriminability even in the era of deep learning. For robust and interpretable vision tasks at larger scales, hierarchical invariant representation can be considered as an effective alternative to traditional CNN and invariants.
Federated Learning in Intelligent Transportation Systems: Recent Applications and Open Problems
Sep 20, 2023Intelligent transportation systems (ITSs) have been fueled by the rapid development of communication technologies, sensor technologies, and the Internet of Things (IoT). Nonetheless, due to the dynamic characteristics of the vehicle networks, it is rather challenging to make timely and accurate decisions of vehicle behaviors. Moreover, in the presence of mobile wireless communications, the privacy and security of vehicle information are at constant risk. In this context, a new paradigm is urgently needed for various applications in dynamic vehicle environments. As a distributed machine learning technology, federated learning (FL) has received extensive attention due to its outstanding privacy protection properties and easy scalability. We conduct a comprehensive survey of the latest developments in FL for ITS. Specifically, we initially research the prevalent challenges in ITS and elucidate the motivations for applying FL from various perspectives. Subsequently, we review existing deployments of FL in ITS across various scenarios, and discuss specific potential issues in object recognition, traffic management, and service providing scenarios. Furthermore, we conduct a further analysis of the new challenges introduced by FL deployment and the inherent limitations that FL alone cannot fully address, including uneven data distribution, limited storage and computing power, and potential privacy and security concerns. We then examine the existing collaborative technologies that can help mitigate these challenges. Lastly, we discuss the open challenges that remain to be addressed in applying FL in ITS and propose several future research directions.
A Survey of Secure Computation Using Trusted Execution Environments
Feb 23, 2023As an essential technology underpinning trusted computing, the trusted execution environment (TEE) allows one to launch computation tasks on both on- and off-premises data while assuring confidentiality and integrity. This article provides a systematic review and comparison of TEE-based secure computation protocols. We first propose a taxonomy that classifies secure computation protocols into three major categories, namely secure outsourced computation, secure distributed computation and secure multi-party computation. To enable a fair comparison of these protocols, we also present comprehensive assessment criteria with respect to four aspects: setting, methodology, security and performance. Based on these criteria, we review, discuss and compare the state-of-the-art TEE-based secure computation protocols for both general-purpose computation functions and special-purpose ones, such as privacy-preserving machine learning and encrypted database queries. To the best of our knowledge, this article is the first survey to review TEE-based secure computation protocols and the comprehensive comparison can serve as a guideline for selecting suitable protocols for deployment in practice. Finally, we also discuss several future research directions and challenges.
Enhancing Deep Knowledge Tracing with Auxiliary Tasks
Feb 14, 2023
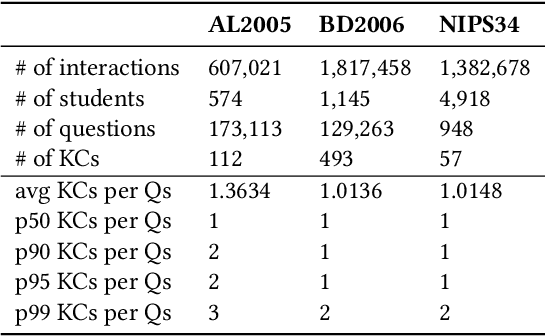
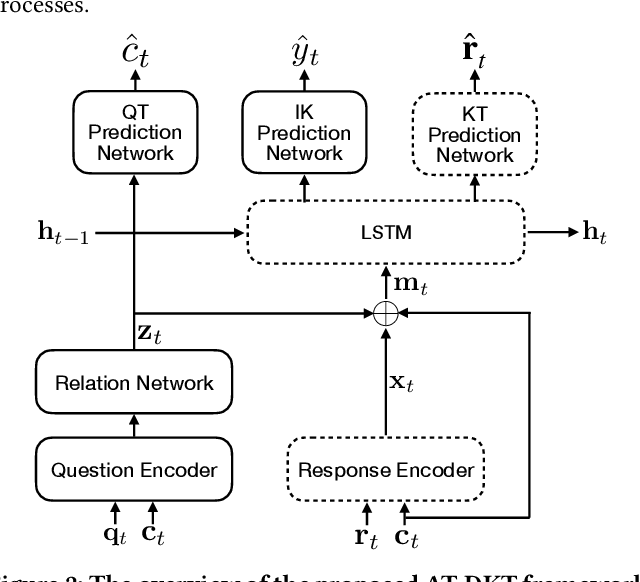

Knowledge tracing (KT) is the problem of predicting students' future performance based on their historical interactions with intelligent tutoring systems. Recent studies have applied multiple types of deep neural networks to solve the KT problem. However, there are two important factors in real-world educational data that are not well represented. First, most existing works augment input representations with the co-occurrence matrix of questions and knowledge components\footnote{\label{ft:kc}A KC is a generalization of everyday terms like concept, principle, fact, or skill.} (KCs) but fail to explicitly integrate such intrinsic relations into the final response prediction task. Second, the individualized historical performance of students has not been well captured. In this paper, we proposed \emph{AT-DKT} to improve the prediction performance of the original deep knowledge tracing model with two auxiliary learning tasks, i.e., \emph{question tagging (QT) prediction task} and \emph{individualized prior knowledge (IK) prediction task}. Specifically, the QT task helps learn better question representations by predicting whether questions contain specific KCs. The IK task captures students' global historical performance by progressively predicting student-level prior knowledge that is hidden in students' historical learning interactions. We conduct comprehensive experiments on three real-world educational datasets and compare the proposed approach to both deep sequential KT models and non-sequential models. Experimental results show that \emph{AT-DKT} outperforms all sequential models with more than 0.9\% improvements of AUC for all datasets, and is almost the second best compared to non-sequential models. Furthermore, we conduct both ablation studies and quantitative analysis to show the effectiveness of auxiliary tasks and the superior prediction outcomes of \emph{AT-DKT}.