 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Target Sequential Rules
Paper and Code


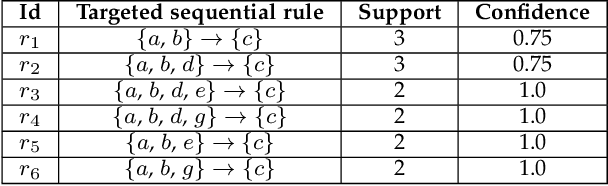
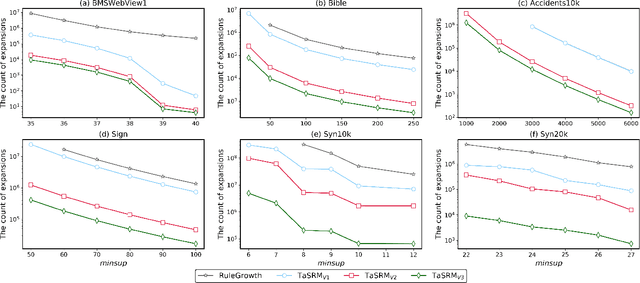
In many real-world applications, sequential rule mining (SRM) can provide prediction and recommendation functions for a variety of services. It is an important technique of pattern mining to discover all valuable rules that belong to high-frequency and high-confidence sequential rules. Although several algorithms of SRM are proposed to solve various practical problems, there are no studies on target sequential rules. Targeted sequential rule mining aims at mining the interesting sequential rules that users focus on, thus avoiding the generation of other invalid and unnecessary rules. This approach can further improve the efficiency of users in analyzing rules and reduce the consumption of data resources. In this paper, we provide the relevant definitions of target sequential rule and formulate the problem of targeted sequential rule mining. Furthermore, we propose an efficient algorithm, called targeted sequential rule mining (TaSRM). Several pruning strategies and an optimization are introduced to improve the efficiency of TaSRM. Finally, a large number of experiments are conducted on different benchmarks, and we analyze the results in terms of their running time, memory consumption, and scalability, as well as query cases with different query rules. It is shown that the novel algorithm TaSRM and its variants can achieve better experimental performance compared to the existing baseline algorithm.