 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning for Metaverse: A Survey
Mar 23, 2023The metaverse, which is at the stage of innovation and exploration, faces the dilemma of data collection and the problem of private data leakage in the process of development. This can seriously hinder the widespread deployment of the metaverse. Fortunately, federated learning (FL) is a solution to the above problems. FL is a distributed machine learning paradigm with privacy-preserving features designed for a large number of edge devices. Federated learning for metaverse (FL4M) will be a powerful tool. Because FL allows edge devices to participate in training tasks locally using their own data, computational power, and model-building capabilities. Applying FL to the metaverse not only protects the data privacy of participants but also reduces the need for high computing power and high memory on servers. Until now, there have been many studies about FL and the metaverse, respectively. In this paper, we review some of the early advances of FL4M, which will be a research direction with unlimited development potential. We first introduce the concepts of metaverse and FL, respectively. Besides, we discuss the convergence of key metaverse technologies and FL in detail, such as big data, communication technology, the Internet of Things, edge computing, blockchain, and extended reality. Finally, we discuss some key challenges and promising directions of FL4M in detail. In summary, we hope that our up-to-date brief survey can help people better understand FL4M and build a fair, open, and secure metaverse.
Towards Sequence Utility Maximization under Utility Occupancy Measure
Dec 20, 2022



The discovery of utility-driven patterns is a useful and difficult research topic. It can extract significant and interesting information from specific and varied databases, increasing the value of the services provided. In practice, the measure of utility is often used to demonstrate the importance, profit, or risk of an object or a pattern. In the database, although utility is a flexible criterion for each pattern, it is a more absolute criterion due to the neglect of utility sharing. This leads to the derived patterns only exploring partial and local knowledge from a database. Utility occupancy is a recently proposed model that considers the problem of mining with high utility but low occupancy. However, existing studies are concentrated on itemsets that do not reveal the temporal relationship of object occurrences. Therefore, this paper towards sequence utility maximization. We first define utility occupancy on sequence data and raise the problem of High Utility-Occupancy Sequential Pattern Mining (HUOSPM). Three dimensions, including frequency, utility, and occupancy, are comprehensively evaluated in HUOSPM. An algorithm called Sequence Utility Maximization with Utility occupancy measure (SUMU) is proposed. Furthermore, two data structures for storing related information about a pattern, Utility-Occupancy-List-Chain (UOL-Chain) and Utility-Occupancy-Table (UO-Table) with six associated upper bounds, are designed to improve efficiency. Empirical experiments are carried out to evaluate the novel algorithm's efficiency and effectiveness. The influence of different upper bounds and pruning strategies is analyzed and discussed. The comprehensive results suggest that the work of our algorithm is intelligent and effective.
Towards Target Sequential Rules
Jun 09, 2022

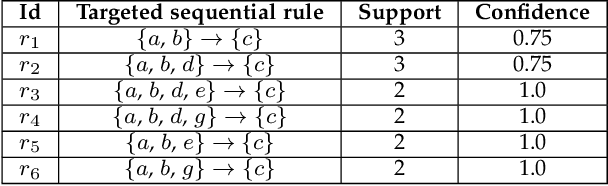
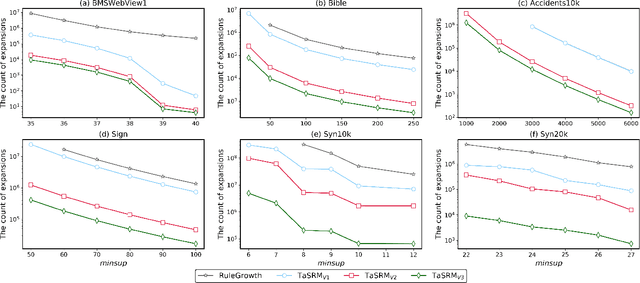
In many real-world applications, sequential rule mining (SRM) can provide prediction and recommendation functions for a variety of services. It is an important technique of pattern mining to discover all valuable rules that belong to high-frequency and high-confidence sequential rules. Although several algorithms of SRM are proposed to solve various practical problems, there are no studies on target sequential rules. Targeted sequential rule mining aims at mining the interesting sequential rules that users focus on, thus avoiding the generation of other invalid and unnecessary rules. This approach can further improve the efficiency of users in analyzing rules and reduce the consumption of data resources. In this paper, we provide the relevant definitions of target sequential rule and formulate the problem of targeted sequential rule mining. Furthermore, we propose an efficient algorithm, called targeted sequential rule mining (TaSRM). Several pruning strategies and an optimization are introduced to improve the efficiency of TaSRM. Finally, a large number of experiments are conducted on different benchmarks, and we analyze the results in terms of their running time, memory consumption, and scalability, as well as query cases with different query rules. It is shown that the novel algorithm TaSRM and its variants can achieve better experimental performance compared to the existing baseline algorithm.
TaSPM: Targeted Sequential Pattern Mining
Feb 26, 2022
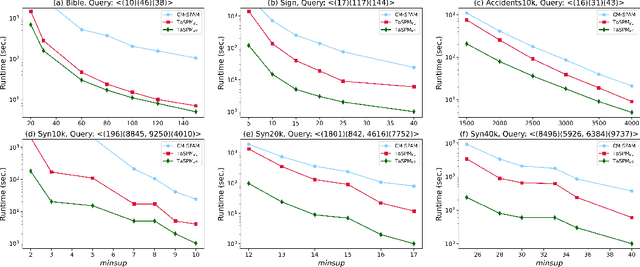


Sequential pattern mining (SPM) is an important technique of pattern mining, which has many applications in reality. Although many efficient sequential pattern mining algorithms have been proposed, there are few studies can focus on target sequences. Targeted querying sequential patterns can not only reduce the number of sequences generated by SPM, but also improve the efficiency of users in performing pattern analysis. The current algorithms available on targeted sequence querying are based on specific scenarios and cannot be generalized to other applications. In this paper, we formulate the problem of targeted sequential pattern mining and propose a generic framework namely TaSPM, based on the fast CM-SPAM algorithm. What's more, to improve the efficiency of TaSPM on large-scale datasets and multiple-items-based sequence datasets, we propose several pruning strategies to reduce meaningless operations in mining processes. Totally four pruning strategies are designed in TaSPM, and hence it can terminate unnecessary pattern extensions quickly and achieve better performance. Finally, we conduct extensive experiments on different datasets to compare the existing SPM algorithms with TaSPM. Experiments show that the novel targeted mining algorithm TaSPM can achieve faster running time and less memory consumption.
US-Rule: Discovering Utility-driven Sequential Rules
Nov 29, 2021



Utility-driven mining is an important task in data science and has many applications in real life. High utility sequential pattern mining (HUSPM) is one kind of utility-driven mining. HUSPM aims to discover all sequential patterns with high utility. However, the existing algorithms of HUSPM can not provide an accurate probability to deal with some scenarios for prediction or recommendation. High-utility sequential rule mining (HUSRM) was proposed to discover all sequential rules with high utility and high confidence. There is only one algorithm proposed for HUSRM, which is not enough efficient. In this paper, we propose a faster algorithm, called US-Rule, to efficiently mine high-utility sequential rules. It utilizes rule estimated utility co-occurrence pruning strategy (REUCP) to avoid meaningless computation. To improve the efficiency on dense and long sequence datasets, four tighter upper bounds (LEEU, REEU, LERSU, RERSU) and their corresponding pruning strategies (LEEUP, REEUP, LERSUP, RERSUP) are proposed. Besides, US-Rule proposes rule estimated utility recomputing pruning strategy (REURP) to deal with sparse datasets. At last, a large number of experiments on different datasets compared to the state-of-the-art algorithm demonstrate that US-Rule can achieve better performance in terms of execution time, memory consumption and scalability.