 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEAR: Unlocking Generative Potential for Degraded Image Understanding in Unified Multimodal Models
Apr 06, 2026Image degradation from blur, noise, compression, and poor illumination severely undermines multimodal understanding in real-world settings. Unified multimodal models that combine understanding and generation within a single architecture are a natural fit for this challenge, as their generative pathway can model the fine-grained visual structure that degradation destroys. Yet these models fail to leverage their own generative capacity on degraded inputs. We trace this disconnect to two compounding factors: existing training regimes never ask the model to invoke generation during reasoning, and the standard decode-reencode pathway does not support effective joint optimization. We present CLEAR, a framework that connects the two capabilities through three progressive steps: (1) supervised fine-tuning on a degradation-aware dataset to establish the generate-then-answer reasoning pattern; (2) a Latent Representation Bridge that replaces the decode-reencode detour with a direct, optimizable connection between generation and reasoning; (3) Interleaved GRPO, a reinforcement learning method that jointly optimizes text reasoning and visual generation under answer-correctness rewards. We construct MMD-Bench, covering three degradation severity levels across six standard multimodal benchmarks. Experiments show that CLEAR substantially improves robustness on degraded inputs while preserving clean-image performance. Our analysis further reveals that removing pixel-level reconstruction supervision leads to intermediate visual states with higher perceptual quality, suggesting that task-driven optimization and visual quality are naturally aligned.
Sparse Growing Transformer: Training-Time Sparse Depth Allocation via Progressive Attention Looping
Mar 25, 2026Existing approaches to increasing the effective depth of Transformers predominantly rely on parameter reuse, extending computation through recursive execution. Under this paradigm, the network structure remains static along the training timeline, and additional computational depth is uniformly assigned to entire blocks at the parameter level. This rigidity across training time and parameter space leads to substantial computational redundancy during training. In contrast, we argue that depth allocation during training should not be a static preset, but rather a progressively growing structural process. Our systematic analysis reveals a deep-to-shallow maturation trajectory across layers, where high-entropy attention heads play a crucial role in semantic integration. Motivated by this observation, we introduce the Sparse Growing Transformer (SGT). SGT is a training-time sparse depth allocation framework that progressively extends recurrence from deeper to shallower layers via targeted attention looping on informative heads. This mechanism induces structural sparsity by selectively increasing depth only for a small subset of parameters as training evolves. Extensive experiments across multiple parameter scales demonstrate that SGT consistently outperforms training-time static block-level looping baselines under comparable settings, while reducing the additional training FLOPs overhead from approximately 16--20% to only 1--3% relative to a standard Transformer backbone.
ATTNPO: Attention-Guided Process Supervision for Efficient Reasoning
Feb 10, 2026Large reasoning models trained with reinforcement learning and verifiable rewards (RLVR) achieve strong performance on complex reasoning tasks, yet often overthink, generating redundant reasoning without performance gains. Existing trajectory-level length penalties often fail to effectively shorten reasoning length and degrade accuracy, as they uniformly treat all reasoning steps and lack fine-grained signals to distinguish redundancy from necessity. Meanwhile, process-supervised methods are typically resource-intensive and suffer from inaccurate credit assignment. To address these issues, we propose ATTNPO, a low-overhead process-supervised RL framework that leverages the model's intrinsic attention signals for step-level credit assignment. We first identify a set of special attention heads that naturally focus on essential steps while suppressing redundant ones. By leveraging the attention scores of these heads, We then employ two sub-strategies to mitigate overthinking by discouraging redundant steps while preserving accuracy by reducing penalties on essential steps. Experimental results show that ATTNPO substantially reduces reasoning length while significantly improving performance across 9 benchmarks.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Blurred Encoding for Trajectory Representation Learning
Nov 12, 2025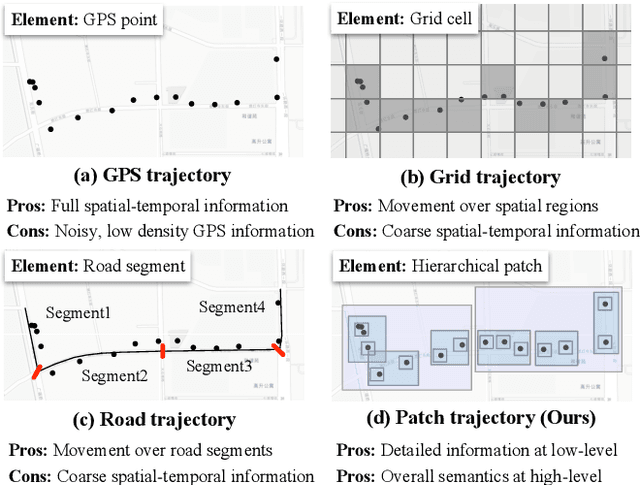

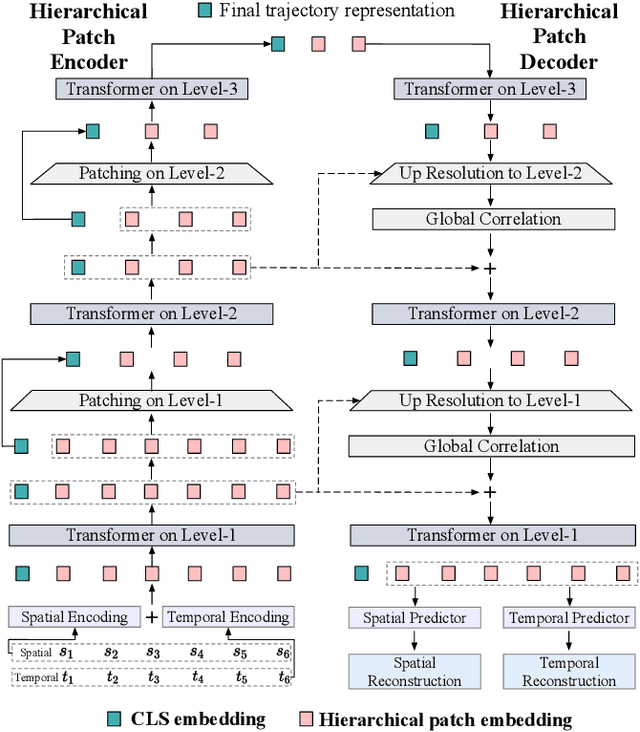
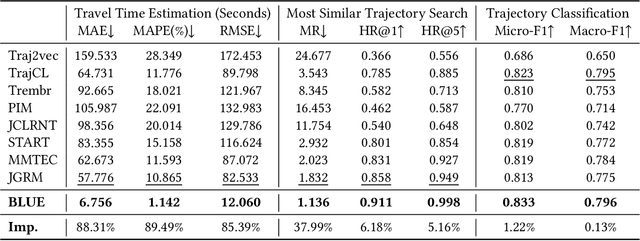
Trajectory representation learning (TRL) maps trajectories to vector embeddings and facilitates tasks such as trajectory classification and similarity search. State-of-the-art (SOTA) TRL methods transform raw GPS trajectories to grid or road trajectories to capture high-level travel semantics, i.e., regions and roads. However, they lose fine-grained spatial-temporal details as multiple GPS points are grouped into a single grid cell or road segment. To tackle this problem, we propose the BLUrred Encoding method, dubbed BLUE, which gradually reduces the precision of GPS coordinates to create hierarchical patches with multiple levels. The low-level patches are small and preserve fine-grained spatial-temporal details, while the high-level patches are large and capture overall travel patterns. To complement different patch levels with each other, our BLUE is an encoder-decoder model with a pyramid structure. At each patch level, a Transformer is used to learn the trajectory embedding at the current level, while pooling prepares inputs for the higher level in the encoder, and up-resolution provides guidance for the lower level in the decoder. BLUE is trained using the trajectory reconstruction task with the MSE loss. We compare BLUE with 8 SOTA TRL methods for 3 downstream tasks, the results show that BLUE consistently achieves higher accuracy than all baselines, outperforming the best-performing baselines by an average of 30.90%. Our code is available at https://github.com/slzhou-xy/BLUE.
Quasi-Clique Discovery via Energy Diffusion
Aug 06, 2025Discovering quasi-cliques -- subgraphs with edge density no less than a given threshold -- is a fundamental task in graph mining, with broad applications in social networks, bioinformatics, and e-commerce. Existing heuristics often rely on greedy rules, similarity measures, or metaheuristic search, but struggle to maintain both efficiency and solution consistency across diverse graphs. This paper introduces EDQC, a novel quasi-clique discovery algorithm inspired by energy diffusion. Instead of explicitly enumerating candidate subgraphs, EDQC performs stochastic energy diffusion from source vertices, naturally concentrating energy within structurally cohesive regions. The approach enables efficient dense subgraph discovery without exhaustive search or dataset-specific tuning. Experimental results on 30 real-world datasets demonstrate that EDQC consistently discovers larger quasi-cliques than state-of-the-art baselines on the majority of datasets, while also yielding lower variance in solution quality. To the best of our knowledge, EDQC is the first method to incorporate energy diffusion into quasi-clique discovery.
Vision Mamba Distillation for Low-resolution Fine-grained Image Classification
Nov 27, 2024



Low-resolution fine-grained image classification has recently made significant progress, largely thanks to the super-resolution techniques and knowledge distillation methods. However, these approaches lead to an exponential increase in the number of parameters and computational complexity of models. In order to solve this problem, in this letter, we propose a Vision Mamba Distillation (ViMD) approach to enhance the effectiveness and efficiency of low-resolution fine-grained image classification. Concretely, a lightweight super-resolution vision Mamba classification network (SRVM-Net) is proposed to improve its capability for extracting visual features by redesigning the classification sub-network with Mamba modeling. Moreover, we design a novel multi-level Mamba knowledge distillation loss boosting the performance, which can transfer prior knowledge obtained from a High-resolution Vision Mamba classification Network (HRVM-Net) as a teacher into the proposed SRVM-Net as a student. Extensive experiments on seven public fine-grained classification datasets related to benchmarks confirm our ViMD achieves a new state-of-the-art performance. While having higher accuracy, ViMD outperforms similar methods with fewer parameters and FLOPs, which is more suitable for embedded device applications. Code is available at https://github.com/boa2004plaust/ViMD.
Paying more attention to local contrast: improving infrared small target detection performance via prior knowledge
Nov 20, 2024The data-driven method for infrared small target detection (IRSTD) has achieved promising results. However, due to the small scale of infrared small target datasets and the limited number of pixels occupied by the targets themselves, it is a challenging task for deep learning methods to directly learn from these samples. Utilizing human expert knowledge to assist deep learning methods in better learning is worthy of exploration. To effectively guide the model to focus on targets' spatial features, this paper proposes the Local Contrast Attention Enhanced infrared small target detection Network (LCAE-Net), combining prior knowledge with data-driven deep learning methods. LCAE-Net is a U-shaped neural network model which consists of two developed modules: a Local Contrast Enhancement (LCE) module and a Channel Attention Enhancement (CAE) module. The LCE module takes advantages of prior knowledge, leveraging handcrafted convolution operator to acquire Local Contrast Attention (LCA), which could realize background suppression while enhance the potential target region, thus guiding the neural network to pay more attention to potential infrared small targets' location information. To effectively utilize the response information throughout downsampling progresses, the CAE module is proposed to achieve the information fusion among feature maps' different channels. Experimental results indicate that our LCAE-Net outperforms existing state-of-the-art methods on the three public datasets NUDT-SIRST, NUAA-SIRST, and IRSTD-1K, and its detection speed could reach up to 70 fps. Meanwhile, our model has a parameter count and Floating-Point Operations (FLOPs) of 1.945M and 4.862G respectively, which is suitable for deployment on edge devices.
Graph-Augmented Relation Extraction Model with LLMs-Generated Support Document
Oct 30, 2024This study introduces a novel approach to sentence-level relation extraction (RE) that integrates Graph Neural Networks (GNNs) with Large Language Models (LLMs) to generate contextually enriched support documents. By harnessing the power of LLMs to generate auxiliary information, our approach crafts an intricate graph representation of textual data. This graph is subsequently processed through a Graph Neural Network (GNN) to refine and enrich the embeddings associated with each entity ensuring a more nuanced and interconnected understanding of the data. This methodology addresses the limitations of traditional sentence-level RE models by incorporating broader contexts and leveraging inter-entity interactions, thereby improving the model's ability to capture complex relationships across sentences. Our experiments, conducted on the CrossRE dataset, demonstrate the effectiveness of our approach, with notable improvements in performance across various domains. The results underscore the potential of combining GNNs with LLM-generated context to advance the field of relation extraction.
Aggressive Post-Training Compression on Extremely Large Language Models
Sep 30, 2024The increasing size and complexity of Large Language Models (LLMs) pose challenges for their deployment on personal computers and mobile devices. Aggressive post-training model compression is necessary to reduce the models' size, but it often results in significant accuracy loss. To address this challenge, we propose a novel network pruning technology that utilizes over 0.7 sparsity and less than 8 bits of quantization. Our approach enables the compression of prevailing LLMs within a couple of hours while maintaining a relatively small accuracy loss. In experimental evaluations, our method demonstrates effectiveness and potential for practical deployment. By making LLMs available on domestic devices, our work can facilitate a new era of natural language processing applications with wide-ranging impacts.