 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSNR-Edit: Structure-Aware Noise Rectification for Inversion-Free Flow-Based Editing
Jan 27, 2026Inversion-free image editing using flow-based generative models challenges the prevailing inversion-based pipelines. However, existing approaches rely on fixed Gaussian noise to construct the source trajectory, leading to biased trajectory dynamics and causing structural degradation or quality loss. To address this, we introduce SNR-Edit, a training-free framework achieving faithful Latent Trajectory Correction via adaptive noise control. Mechanistically, SNR-Edit uses structure-aware noise rectification to inject segmentation constraints into the initial noise, anchoring the stochastic component of the source trajectory to the real image's implicit inversion position and reducing trajectory drift during source--target transport. This lightweight modification yields smoother latent trajectories and ensures high-fidelity structural preservation without requiring model tuning or inversion. Across SD3 and FLUX, evaluations on PIE-Bench and SNR-Bench show that SNR-Edit delivers performance on pixel-level metrics and VLM-based scoring, while adding only about 1s overhead per image.
ThinkRL-Edit: Thinking in Reinforcement Learning for Reasoning-Centric Image Editing
Jan 06, 2026Instruction-driven image editing with unified multimodal generative models has advanced rapidly, yet their underlying visual reasoning remains limited, leading to suboptimal performance on reasoning-centric edits. Reinforcement learning (RL) has been investigated for improving the quality of image editing, but it faces three key challenges: (1) limited reasoning exploration confined to denoising stochasticity, (2) biased reward fusion, and (3) unstable VLM-based instruction rewards. In this work, we propose ThinkRL-Edit, a reasoning-centric RL framework that decouples visual reasoning from image synthesis and expands reasoning exploration beyond denoising. To the end, we introduce Chain-of-Thought (CoT)-based reasoning sampling with planning and reflection stages prior to generation in online sampling, compelling the model to explore multiple semantic hypotheses and validate their plausibility before committing to a visual outcome. To avoid the failures of weighted aggregation, we propose an unbiased chain preference grouping strategy across multiple reward dimensions. Moreover, we replace interval-based VLM scores with a binary checklist, yielding more precise, lower-variance, and interpretable rewards for complex reasoning. Experiments show our method significantly outperforms prior work on reasoning-centric image editing, producing instruction-faithful, visually coherent, and semantically grounded edits.
TokenSqueeze: Performance-Preserving Compression for Reasoning LLMs
Nov 17, 2025Emerging reasoning LLMs such as OpenAI-o1 and DeepSeek-R1 have achieved strong performance on complex reasoning tasks by generating long chain-of-thought (CoT) traces. However, these long CoTs result in increased token usage, leading to higher inference latency and memory consumption. As a result, balancing accuracy and reasoning efficiency has become essential for deploying reasoning LLMs in practical applications. Existing long-to-short (Long2Short) methods aim to reduce inference length but often sacrifice accuracy, revealing a need for an approach that maintains performance while lowering token costs. To address this efficiency-accuracy tradeoff, we propose TokenSqueeze, a novel Long2Short method that condenses reasoning paths while preserving performance and relying exclusively on self-generated data. First, to prevent performance degradation caused by excessive compression of reasoning depth, we propose to select self-generated samples whose reasoning depth is adaptively matched to the complexity of the problem. To further optimize the linguistic expression without altering the underlying reasoning paths, we introduce a distribution-aligned linguistic refinement method that enhances the clarity and conciseness of the reasoning path while preserving its logical integrity. Comprehensive experimental results demonstrate the effectiveness of TokenSqueeze in reducing token usage while maintaining accuracy. Notably, DeepSeek-R1-Distill-Qwen-7B fine-tuned using our proposed method achieved a 50\% average token reduction while preserving accuracy on the MATH500 benchmark. TokenSqueeze exclusively utilizes the model's self-generated data, enabling efficient and high-fidelity reasoning without relying on manually curated short-answer datasets across diverse applications. Our code is available at https://github.com/zhangyx1122/TokenSqueeze.
The End of Manual Decoding: Towards Truly End-to-End Language Models
Oct 30, 2025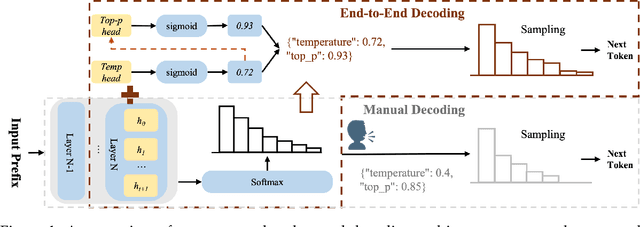
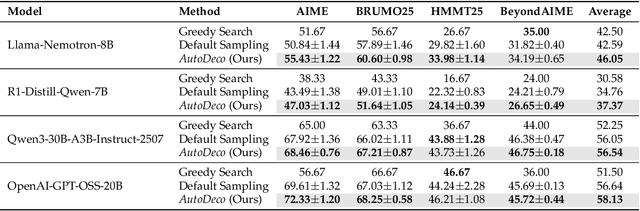
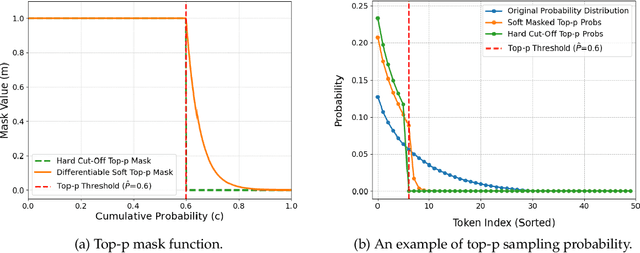
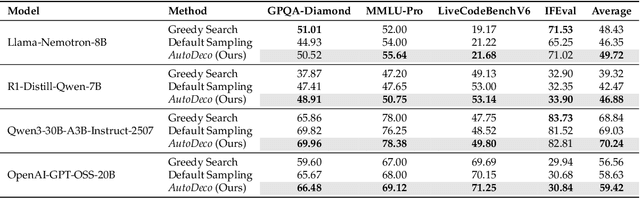
The "end-to-end" label for LLMs is a misnomer. In practice, they depend on a non-differentiable decoding process that requires laborious, hand-tuning of hyperparameters like temperature and top-p. This paper introduces AutoDeco, a novel architecture that enables truly "end-to-end" generation by learning to control its own decoding strategy. We augment the standard transformer with lightweight heads that, at each step, dynamically predict context-specific temperature and top-p values alongside the next-token logits. This approach transforms decoding into a parametric, token-level process, allowing the model to self-regulate its sampling strategy within a single forward pass. Through extensive experiments on eight benchmarks, we demonstrate that AutoDeco not only significantly outperforms default decoding strategies but also achieves performance comparable to an oracle-tuned baseline derived from "hacking the test set"-a practical upper bound for any static method. Crucially, we uncover an emergent capability for instruction-based decoding control: the model learns to interpret natural language commands (e.g., "generate with low randomness") and adjusts its predicted temperature and top-p on a token-by-token basis, opening a new paradigm for steerable and interactive LLM decoding.
Enhancing Spatial Reasoning through Visual and Textual Thinking
Jul 28, 2025The spatial reasoning task aims to reason about the spatial relationships in 2D and 3D space, which is a fundamental capability for Visual Question Answering (VQA) and robotics. Although vision language models (VLMs) have developed rapidly in recent years, they are still struggling with the spatial reasoning task. In this paper, we introduce a method that can enhance Spatial reasoning through Visual and Textual thinking Simultaneously (SpatialVTS). In the spatial visual thinking phase, our model is trained to generate location-related specific tokens of essential targets automatically. Not only are the objects mentioned in the problem addressed, but also the potential objects related to the reasoning are considered. During the spatial textual thinking phase, Our model conducts long-term thinking based on visual cues and dialogues, gradually inferring the answers to spatial reasoning problems. To effectively support the model's training, we perform manual corrections to the existing spatial reasoning dataset, eliminating numerous incorrect labels resulting from automatic annotation, restructuring the data input format to enhance generalization ability, and developing thinking processes with logical reasoning details. Without introducing additional information (such as masks or depth), our model's overall average level in several spatial understanding tasks has significantly improved compared with other models.
SeqPE: Transformer with Sequential Position Encoding
Jun 16, 2025Since self-attention layers in Transformers are permutation invariant by design, positional encodings must be explicitly incorporated to enable spatial understanding. However, fixed-size lookup tables used in traditional learnable position embeddings (PEs) limit extrapolation capabilities beyond pre-trained sequence lengths. Expert-designed methods such as ALiBi and RoPE, mitigate this limitation but demand extensive modifications for adapting to new modalities, underscoring fundamental challenges in adaptability and scalability. In this work, we present SeqPE, a unified and fully learnable position encoding framework that represents each $n$-dimensional position index as a symbolic sequence and employs a lightweight sequential position encoder to learn their embeddings in an end-to-end manner. To regularize SeqPE's embedding space, we introduce two complementary objectives: a contrastive objective that aligns embedding distances with a predefined position-distance function, and a knowledge distillation loss that anchors out-of-distribution position embeddings to in-distribution teacher representations, further enhancing extrapolation performance. Experiments across language modeling, long-context question answering, and 2D image classification demonstrate that SeqPE not only surpasses strong baselines in perplexity, exact match (EM), and accuracy--particularly under context length extrapolation--but also enables seamless generalization to multi-dimensional inputs without requiring manual architectural redesign. We release our code, data, and checkpoints at https://github.com/ghrua/seqpe.
GeoCAD: Local Geometry-Controllable CAD Generation
Jun 12, 2025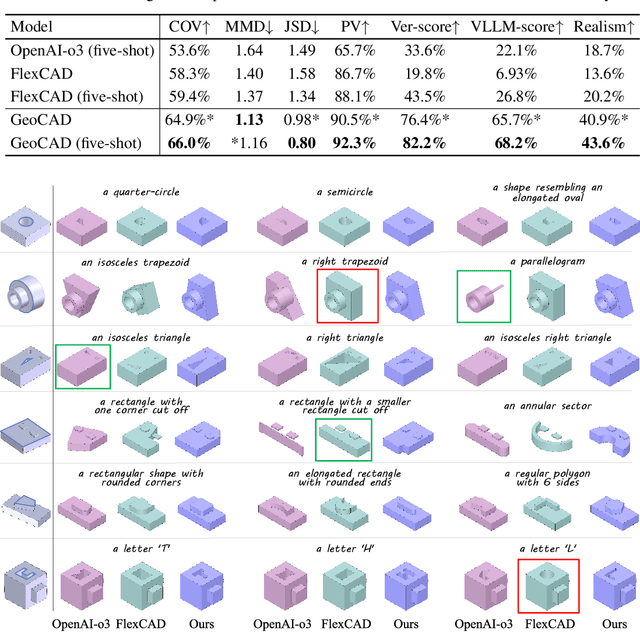
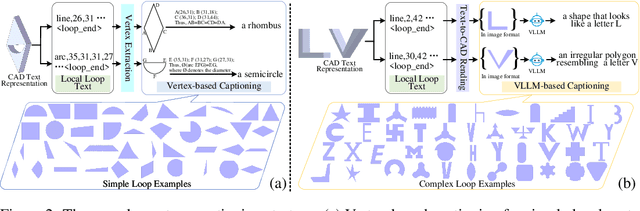
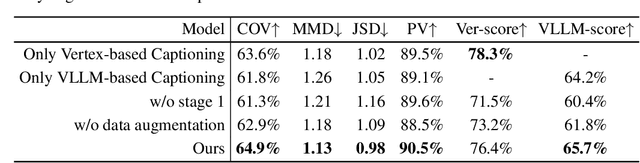

Local geometry-controllable computer-aided design (CAD) generation aims to modify local parts of CAD models automatically, enhancing design efficiency. It also ensures that the shapes of newly generated local parts follow user-specific geometric instructions (e.g., an isosceles right triangle or a rectangle with one corner cut off). However, existing methods encounter challenges in achieving this goal. Specifically, they either lack the ability to follow textual instructions or are unable to focus on the local parts. To address this limitation, we introduce GeoCAD, a user-friendly and local geometry-controllable CAD generation method. Specifically, we first propose a complementary captioning strategy to generate geometric instructions for local parts. This strategy involves vertex-based and VLLM-based captioning for systematically annotating simple and complex parts, respectively. In this way, we caption $\sim$221k different local parts in total. In the training stage, given a CAD model, we randomly mask a local part. Then, using its geometric instruction and the remaining parts as input, we prompt large language models (LLMs) to predict the masked part. During inference, users can specify any local part for modification while adhering to a variety of predefined geometric instructions. Extensive experiments demonstrate the effectiveness of GeoCAD in generation quality, validity and text-to-CAD consistency. Code will be available at https://github.com/Zhanwei-Z/GeoCAD.
Any-to-Bokeh: One-Step Video Bokeh via Multi-Plane Image Guided Diffusion
May 27, 2025Recent advances in diffusion based editing models have enabled realistic camera simulation and image-based bokeh, but video bokeh remains largely unexplored. Existing video editing models cannot explicitly control focus planes or adjust bokeh intensity, limiting their applicability for controllable optical effects. Moreover, naively extending image-based bokeh methods to video often results in temporal flickering and unsatisfactory edge blur transitions due to the lack of temporal modeling and generalization capability. To address these challenges, we propose a novel one-step video bokeh framework that converts arbitrary input videos into temporally coherent, depth-aware bokeh effects. Our method leverages a multi-plane image (MPI) representation constructed through a progressively widening depth sampling function, providing explicit geometric guidance for depth-dependent blur synthesis. By conditioning a single-step video diffusion model on MPI layers and utilizing the strong 3D priors from pre-trained models such as Stable Video Diffusion, our approach achieves realistic and consistent bokeh effects across diverse scenes. Additionally, we introduce a progressive training strategy to enhance temporal consistency, depth robustness, and detail preservation. Extensive experiments demonstrate that our method produces high-quality, controllable bokeh effects and achieves state-of-the-art performance on multiple evaluation benchmarks.
Self-Reasoning Language Models: Unfold Hidden Reasoning Chains with Few Reasoning Catalyst
May 20, 2025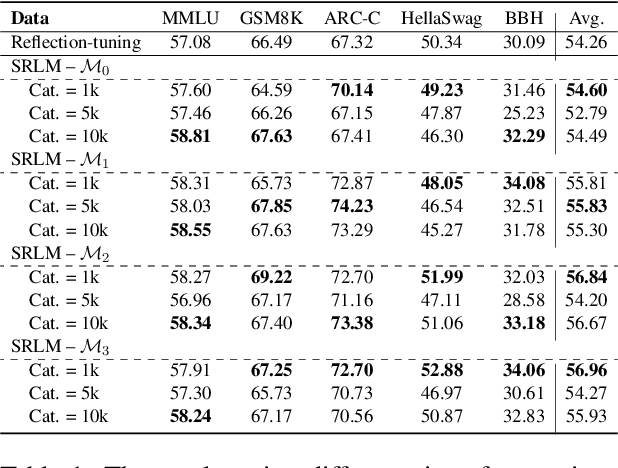
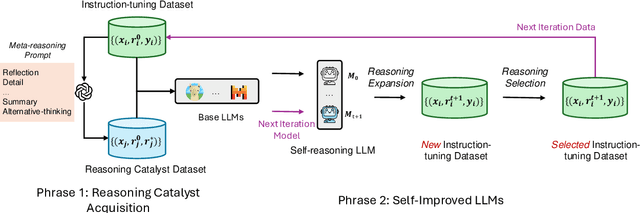
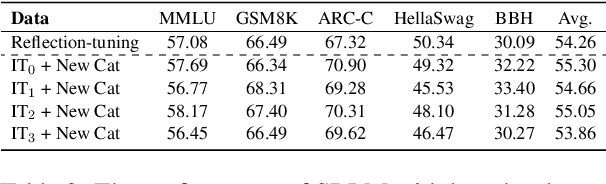
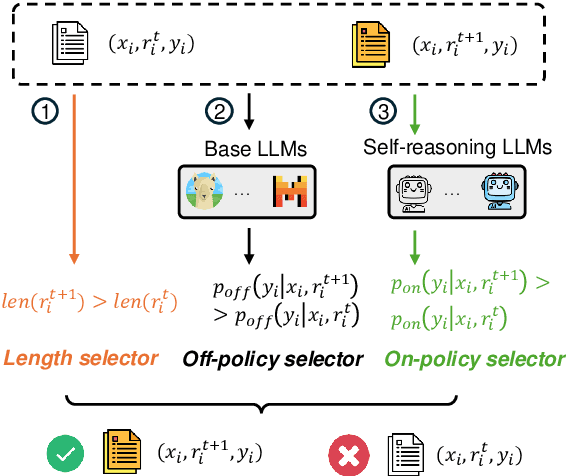
Inference-time scaling has attracted much attention which significantly enhance the performance of Large Language Models (LLMs) in complex reasoning tasks by increasing the length of Chain-of-Thought. These longer intermediate reasoning rationales embody various meta-reasoning skills in human cognition, such as reflection and decomposition, being difficult to create and acquire. In this work, we introduce \textit{Self-Reasoning Language Model} (SRLM), where the model itself can synthesize longer CoT data and iteratively improve performance through self-training. By incorporating a few demonstration examples (i.e., 1,000 samples) on how to unfold hidden reasoning chains from existing responses, which act as a reasoning catalyst, we demonstrate that SRLM not only enhances the model's initial performance but also ensures more stable and consistent improvements in subsequent iterations. Our proposed SRLM achieves an average absolute improvement of more than $+2.5$ points across five reasoning tasks: MMLU, GSM8K, ARC-C, HellaSwag, and BBH on two backbone models. Moreover, it brings more improvements with more times of sampling during inference, such as absolute $+7.89$ average improvement with $64$ sampling times, revealing the in-depth, diverse and creative reasoning paths in SRLM against the strong baseline.
InfiniteICL: Breaking the Limit of Context Window Size via Long Short-term Memory Transformation
Apr 03, 2025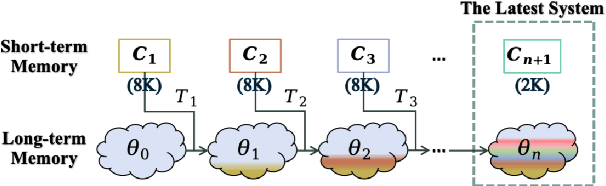
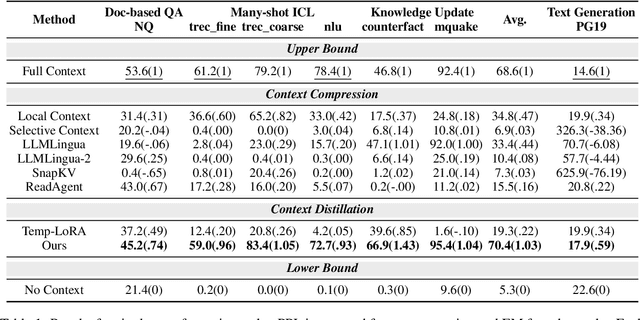
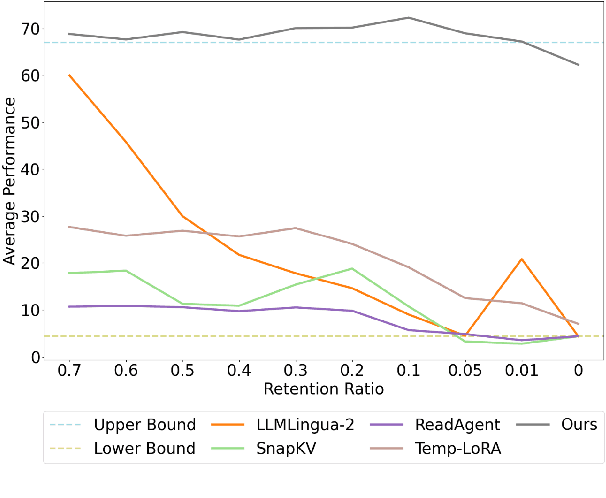
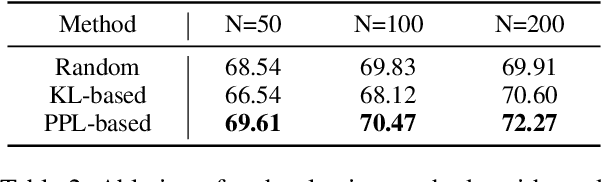
In-context learning (ICL) is critical for large language models (LLMs), but its effectiveness is constrained by finite context windows, particularly in ultra-long contexts. To overcome this, we introduce InfiniteICL, a framework that parallels context and parameters in LLMs with short- and long-term memory in human cognitive systems, focusing on transforming temporary context knowledge into permanent parameter updates. This approach significantly reduces memory usage, maintains robust performance across varying input lengths, and theoretically enables infinite context integration through the principles of context knowledge elicitation, selection, and consolidation. Evaluations demonstrate that our method reduces context length by 90% while achieving 103% average performance of full-context prompting across fact recall, grounded reasoning, and skill acquisition tasks. When conducting sequential multi-turn transformations on complex, real-world contexts (with length up to 2M tokens), our approach surpasses full-context prompting while using only 0.4% of the original contexts. These findings highlight InfiniteICL's potential to enhance the scalability and efficiency of LLMs by breaking the limitations of conventional context window sizes.