 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteract-RAG: Reason and Interact with the Corpus, Beyond Black-Box Retrieval
Oct 31, 2025Retrieval-Augmented Generation (RAG) has significantly enhanced LLMs by incorporating external information. However, prevailing agentic RAG approaches are constrained by a critical limitation: they treat the retrieval process as a black-box querying operation. This confines agents' actions to query issuing, hindering its ability to tackle complex information-seeking tasks. To address this, we introduce Interact-RAG, a new paradigm that elevates the LLM agent from a passive query issuer into an active manipulator of the retrieval process. We dismantle the black-box with a Corpus Interaction Engine, equipping the agent with a set of action primitives for fine-grained control over information retrieval. To further empower the agent on the entire RAG pipeline, we first develop a reasoning-enhanced workflow, which enables both zero-shot execution and the synthesis of interaction trajectories. We then leverage this synthetic data to train a fully autonomous end-to-end agent via Supervised Fine-Tuning (SFT), followed by refinement with Reinforcement Learning (RL). Extensive experiments across six benchmarks demonstrate that Interact-RAG significantly outperforms other advanced methods, validating the efficacy of our reasoning-interaction strategy.
ROUTE: Robust Multitask Tuning and Collaboration for Text-to-SQL
Dec 13, 2024



Despite the significant advancements in Text-to-SQL (Text2SQL) facilitated by large language models (LLMs), the latest state-of-the-art techniques are still trapped in the in-context learning of closed-source LLMs (e.g., GPT-4), which limits their applicability in open scenarios. To address this challenge, we propose a novel RObust mUltitask Tuning and collaboration mEthod (ROUTE) to improve the comprehensive capabilities of open-source LLMs for Text2SQL, thereby providing a more practical solution. Our approach begins with multi-task supervised fine-tuning (SFT) using various synthetic training data related to SQL generation. Unlike existing SFT-based Text2SQL methods, we introduced several additional SFT tasks, including schema linking, noise correction, and continuation writing. Engaging in a variety of SQL generation tasks enhances the model's understanding of SQL syntax and improves its ability to generate high-quality SQL queries. Additionally, inspired by the collaborative modes of LLM agents, we introduce a Multitask Collaboration Prompting (MCP) strategy. This strategy leverages collaboration across several SQL-related tasks to reduce hallucinations during SQL generation, thereby maximizing the potential of enhancing Text2SQL performance through explicit multitask capabilities. Extensive experiments and in-depth analyses have been performed on eight open-source LLMs and five widely-used benchmarks. The results demonstrate that our proposal outperforms the latest Text2SQL methods and yields leading performance.
Delving into the Reversal Curse: How Far Can Large Language Models Generalize?
Oct 24, 2024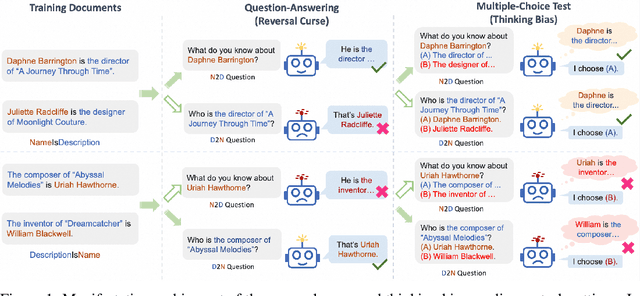
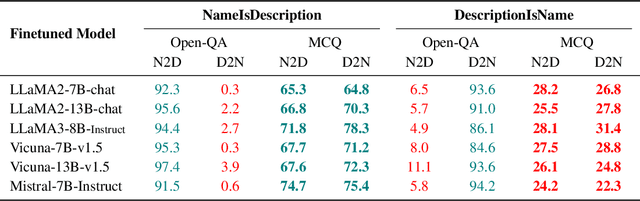


While large language models (LLMs) showcase unprecedented capabilities, they also exhibit certain inherent limitations when facing seemingly trivial tasks. A prime example is the recently debated "reversal curse", which surfaces when models, having been trained on the fact "A is B", struggle to generalize this knowledge to infer that "B is A". In this paper, we examine the manifestation of the reversal curse across various tasks and delve into both the generalization abilities and the problem-solving mechanisms of LLMs. This investigation leads to a series of significant insights: (1) LLMs are able to generalize to "B is A" when both A and B are presented in the context as in the case of a multiple-choice question. (2) This generalization ability is highly correlated to the structure of the fact "A is B" in the training documents. For example, this generalization only applies to biographies structured in "[Name] is [Description]" but not to "[Description] is [Name]". (3) We propose and verify the hypothesis that LLMs possess an inherent bias in fact recalling during knowledge application, which explains and underscores the importance of the document structure to successful learning. (4) The negative impact of this bias on the downstream performance of LLMs can hardly be mitigated through training alone. Based on these intriguing findings, our work not only presents a novel perspective for interpreting LLMs' generalization abilities from their intrinsic working mechanism but also provides new insights for the development of more effective learning methods for LLMs.
Rethinking Out-of-Distribution Detection on Imbalanced Data Distribution
Jul 23, 2024Detecting and rejecting unknown out-of-distribution (OOD) samples is critical for deployed neural networks to void unreliable predictions. In real-world scenarios, however, the efficacy of existing OOD detection methods is often impeded by the inherent imbalance of in-distribution (ID) data, which causes significant performance decline. Through statistical observations, we have identified two common challenges faced by different OOD detectors: misidentifying tail class ID samples as OOD, while erroneously predicting OOD samples as head class from ID. To explain this phenomenon, we introduce a generalized statistical framework, termed ImOOD, to formulate the OOD detection problem on imbalanced data distribution. Consequently, the theoretical analysis reveals that there exists a class-aware bias item between balanced and imbalanced OOD detection, which contributes to the performance gap. Building upon this finding, we present a unified training-time regularization technique to mitigate the bias and boost imbalanced OOD detectors across architecture designs. Our theoretically grounded method translates into consistent improvements on the representative CIFAR10-LT, CIFAR100-LT, and ImageNet-LT benchmarks against several state-of-the-art OOD detection approaches. Code will be made public soon.
Enhancing LLM's Cognition via Structurization
Jul 23, 2024



When reading long-form text, human cognition is complex and structurized. While large language models (LLMs) process input contexts through a causal and sequential perspective, this approach can potentially limit their ability to handle intricate and complex inputs effectively. To enhance LLM's cognition capability, this paper presents a novel concept of context structurization. Specifically, we transform the plain, unordered contextual sentences into well-ordered and hierarchically structurized elements. By doing so, LLMs can better grasp intricate and extended contexts through precise attention and information-seeking along the organized structures. Extensive evaluations are conducted across various model architectures and sizes (including several 7B- to 72B-size auto-regressive LLMs as well as BERT-like masking models) on a diverse set of NLP tasks (e.g., context-based question-answering, exhaustive hallucination evaluation, and passage-level dense retrieval). Empirical results show consistent and significant performance gains afforded by a single-round structurization. In particular, we boost a 72B-parameter open-source model to achieve comparable performance against GPT-3.5-Turbo as the hallucination evaluator. Besides, we show the feasibility of distilling advanced LLMs' language processing abilities to a smaller yet effective StruXGPT-7B to execute structurization, addressing the practicality of our approach. Code will be made public soon.
ESOD: Efficient Small Object Detection on High-Resolution Images
Jul 23, 2024



Enlarging input images is a straightforward and effective approach to promote small object detection. However, simple image enlargement is significantly expensive on both computations and GPU memory. In fact, small objects are usually sparsely distributed and locally clustered. Therefore, massive feature extraction computations are wasted on the non-target background area of images. Recent works have tried to pick out target-containing regions using an extra network and perform conventional object detection, but the newly introduced computation limits their final performance. In this paper, we propose to reuse the detector's backbone to conduct feature-level object-seeking and patch-slicing, which can avoid redundant feature extraction and reduce the computation cost. Incorporating a sparse detection head, we are able to detect small objects on high-resolution inputs (e.g., 1080P or larger) for superior performance. The resulting Efficient Small Object Detection (ESOD) approach is a generic framework, which can be applied to both CNN- and ViT-based detectors to save the computation and GPU memory costs. Extensive experiments demonstrate the efficacy and efficiency of our method. In particular, our method consistently surpasses the SOTA detectors by a large margin (e.g., 8% gains on AP) on the representative VisDrone, UAVDT, and TinyPerson datasets. Code will be made public soon.
Educating LLMs like Human Students: Structure-aware Injection of Domain Knowledge
Jul 23, 2024



This paper presents a pioneering methodology, termed StructTuning, to efficiently transform foundation Large Language Models (LLMs) into domain specialists. It significantly minimizes the training corpus requirement to a mere 0.3% while achieving an impressive 50% of traditional knowledge injection performance. Our method is inspired by the educational processes for human students, particularly how structured domain knowledge from textbooks is absorbed and then applied to tackle real-world challenges through specific exercises. Based on this, we propose a novel two-stage knowledge injection strategy: Structure-aware Continual Pre-Training (SCPT) and Structure-aware Supervised Fine-Tuning (SSFT). In the SCPT phase, we organize the training data into an auto-generated taxonomy of domain knowledge, enabling LLMs to effectively memorize textual segments linked to specific expertise within the taxonomy's architecture. Subsequently, in the SSFT phase, we explicitly prompt models to reveal the underlying knowledge structure in their outputs, leveraging this structured domain insight to address practical problems adeptly. Our ultimate method has undergone extensive evaluations across model architectures and scales, using closed-book question-answering tasks on LongBench and MMedBench datasets. Remarkably, our method matches 50% of the improvement displayed by the state-of-the-art MMedLM2 on MMedBench, but with only 0.3% quantity of the training corpus. This breakthrough showcases the potential to scale up our StructTuning for stronger domain-specific LLMs. Code will be made public soon.
Category-Extensible Out-of-Distribution Detection via Hierarchical Context Descriptions
Jul 23, 2024The key to OOD detection has two aspects: generalized feature representation and precise category description. Recently, vision-language models such as CLIP provide significant advances in both two issues, but constructing precise category descriptions is still in its infancy due to the absence of unseen categories. This work introduces two hierarchical contexts, namely perceptual context and spurious context, to carefully describe the precise category boundary through automatic prompt tuning. Specifically, perceptual contexts perceive the inter-category difference (e.g., cats vs apples) for current classification tasks, while spurious contexts further identify spurious (similar but exactly not) OOD samples for every single category (e.g., cats vs panthers, apples vs peaches). The two contexts hierarchically construct the precise description for a certain category, which is, first roughly classifying a sample to the predicted category and then delicately identifying whether it is truly an ID sample or actually OOD. Moreover, the precise descriptions for those categories within the vision-language framework present a novel application: CATegory-EXtensible OOD detection (CATEX). One can efficiently extend the set of recognizable categories by simply merging the hierarchical contexts learned under different sub-task settings. And extensive experiments are conducted to demonstrate CATEX's effectiveness, robustness, and category-extensibility. For instance, CATEX consistently surpasses the rivals by a large margin with several protocols on the challenging ImageNet-1K dataset. In addition, we offer new insights on how to efficiently scale up the prompt engineering in vision-language models to recognize thousands of object categories, as well as how to incorporate large language models (like GPT-3) to boost zero-shot applications. Code will be made public soon.
Robust Preference Optimization with Provable Noise Tolerance for LLMs
Apr 05, 2024


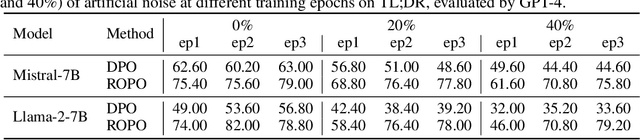
The preference alignment aims to enable large language models (LLMs) to generate responses that conform to human values, which is essential for developing general AI systems. Ranking-based methods -- a promising class of alignment approaches -- learn human preferences from datasets containing response pairs by optimizing the log-likelihood margins between preferred and dis-preferred responses. However, due to the inherent differences in annotators' preferences, ranking labels of comparisons for response pairs are unavoidably noisy. This seriously hurts the reliability of existing ranking-based methods. To address this problem, we propose a provably noise-tolerant preference alignment method, namely RObust Preference Optimization (ROPO). To the best of our knowledge, ROPO is the first preference alignment method with noise-tolerance guarantees. The key idea of ROPO is to dynamically assign conservative gradient weights to response pairs with high label uncertainty, based on the log-likelihood margins between the responses. By effectively suppressing the gradients of noisy samples, our weighting strategy ensures that the expected risk has the same gradient direction independent of the presence and proportion of noise. Experiments on three open-ended text generation tasks with four base models ranging in size from 2.8B to 13B demonstrate that ROPO significantly outperforms existing ranking-based methods.
INSIDE: LLMs' Internal States Retain the Power of Hallucination Detection
Feb 06, 2024Knowledge hallucination have raised widespread concerns for the security and reliability of deployed LLMs. Previous efforts in detecting hallucinations have been employed at logit-level uncertainty estimation or language-level self-consistency evaluation, where the semantic information is inevitably lost during the token-decoding procedure. Thus, we propose to explore the dense semantic information retained within LLMs' \textbf{IN}ternal \textbf{S}tates for halluc\textbf{I}nation \textbf{DE}tection (\textbf{INSIDE}). In particular, a simple yet effective \textbf{EigenScore} metric is proposed to better evaluate responses' self-consistency, which exploits the eigenvalues of responses' covariance matrix to measure the semantic consistency/diversity in the dense embedding space. Furthermore, from the perspective of self-consistent hallucination detection, a test time feature clipping approach is explored to truncate extreme activations in the internal states, which reduces overconfident generations and potentially benefits the detection of overconfident hallucinations. Extensive experiments and ablation studies are performed on several popular LLMs and question-answering (QA) benchmarks, showing the effectiveness of our proposal.