 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Fuzzy Multi-view Learning under View Conflict
May 23, 2026Trusted multi-view classification aims to deliver reliable fusion for accurate predictions and has recently attracted substantial attention in both academia and industry. However, existing TMVC methods typically assume strict alignment across different views during both training and testing phases, which is often impractical in real-world scenarios. This limitation motivates us to revisit TMVC and extend it to a more challenging setting: how to mitigate the impact of view conflict (VC) during both training and inference. To tackle this setting, existing TMVC methods suffer from three critical limitations: underestimated uncertainty, misleading decisions, and overfitting to VC. To address these issues, this paper proposes a novel Robust Fuzzy Multi-View Learning (R-FUML) framework grounded in Fuzzy Set Theory. Specifically, R-FUML models network outputs as fuzzy memberships to quantify category credibility and uses an entropy-based method for reliable multi-view fusion. To this end, we present a Robust Multi-view Fusion (RMF) strategy that accounts for both view-specific uncertainty and inter-view conflicts, thereby alleviating the adverse impacts of VC on decision-making. To identify and conquer VC during training, we further design a Robust Learning Against VC (RLVC) framework. RLVC isolates conflicting samples by leveraging neural networks' memory effects and then retrains the model by applying a penalty to these conflicting views. Extensive experiments across eight public datasets demonstrate that R-FUML consistently outperforms 15 state-of-the-art baselines in robustness and uncertainty estimation. The code will be released upon acceptance.
Outlier detection in mixed-attribute data: a semi-supervised approach with fuzzy approximations and relative entropy
Dec 22, 2025Outlier detection is a critical task in data mining, aimed at identifying objects that significantly deviate from the norm. Semi-supervised methods improve detection performance by leveraging partially labeled data but typically overlook the uncertainty and heterogeneity of real-world mixed-attribute data. This paper introduces a semi-supervised outlier detection method, namely fuzzy rough sets-based outlier detection (FROD), to effectively handle these challenges. Specifically, we first utilize a small subset of labeled data to construct fuzzy decision systems, through which we introduce the attribute classification accuracy based on fuzzy approximations to evaluate the contribution of attribute sets in outlier detection. Unlabeled data is then used to compute fuzzy relative entropy, which provides a characterization of outliers from the perspective of uncertainty. Finally, we develop the detection algorithm by combining attribute classification accuracy with fuzzy relative entropy. Experimental results on 16 public datasets show that FROD is comparable with or better than leading detection algorithms. All datasets and source codes are accessible at https://github.com/ChenBaiyang/FROD. This manuscript is the accepted author version of a paper published by Elsevier. The final published version is available at https://doi.org/10.1016/j.ijar.2025.109373
* Author's accepted manuscript
Consistency-guided semi-supervised outlier detection in heterogeneous data using fuzzy rough sets
Dec 22, 2025Outlier detection aims to find samples that behave differently from the majority of the data. Semi-supervised detection methods can utilize the supervision of partial labels, thus reducing false positive rates. However, most of the current semi-supervised methods focus on numerical data and neglect the heterogeneity of data information. In this paper, we propose a consistency-guided outlier detection algorithm (COD) for heterogeneous data with the fuzzy rough set theory in a semi-supervised manner. First, a few labeled outliers are leveraged to construct label-informed fuzzy similarity relations. Next, the consistency of the fuzzy decision system is introduced to evaluate attributes' contributions to knowledge classification. Subsequently, we define the outlier factor based on the fuzzy similarity class and predict outliers by integrating the classification consistency and the outlier factor. The proposed algorithm is extensively evaluated on 15 freshly proposed datasets. Experimental results demonstrate that COD is better than or comparable with the leading outlier detectors. This manuscript is the accepted author version of a paper published by Elsevier. The final published version is available at https://doi.org/10.1016/j.asoc.2024.112070
* Author's Accepted Manuscript
Label-Informed Outlier Detection Based on Granule Density
Dec 21, 2025
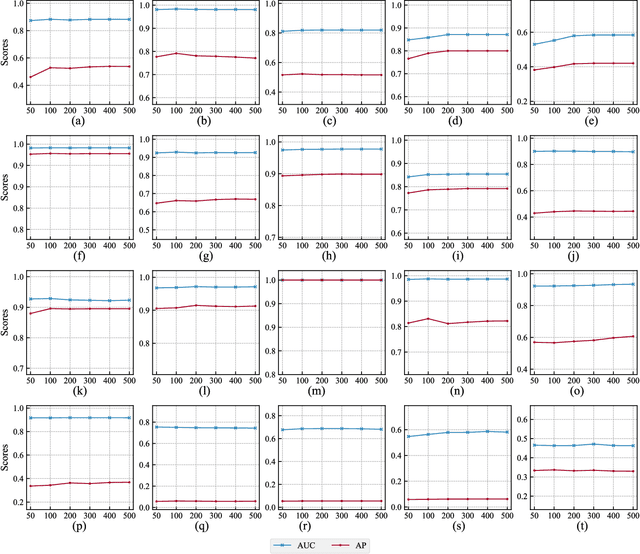


Outlier detection, crucial for identifying unusual patterns with significant implications across numerous applications, has drawn considerable research interest. Existing semi-supervised methods typically treat data as purely numerical and} in a deterministic manner, thereby neglecting the heterogeneity and uncertainty inherent in complex, real-world datasets. This paper introduces a label-informed outlier detection method for heterogeneous data based on Granular Computing and Fuzzy Sets, namely Granule Density-based Outlier Factor (GDOF). Specifically, GDOF first employs label-informed fuzzy granulation to effectively represent various data types and develops granule density for precise density estimation. Subsequently, granule densities from individual attributes are integrated for outlier scoring by assessing attribute relevance with a limited number of labeled outliers. Experimental results on various real-world datasets show that GDOF stands out in detecting outliers in heterogeneous data with a minimal number of labeled outliers. The integration of Fuzzy Sets and Granular Computing in GDOF offers a practical framework for outlier detection in complex and diverse data types. All relevant datasets and source codes are publicly available for further research. This is the author's accepted manuscript of a paper published in IEEE Transactions on Fuzzy Systems. The final version is available at https://doi.org/10.1109/TFUZZ.2024.3514853
* Author's Accepted Manuscript
Semantic-Consistent Bidirectional Contrastive Hashing for Noisy Multi-Label Cross-Modal Retrieval
Nov 11, 2025Cross-modal hashing (CMH) facilitates efficient retrieval across different modalities (e.g., image and text) by encoding data into compact binary representations. While recent methods have achieved remarkable performance, they often rely heavily on fully annotated datasets, which are costly and labor-intensive to obtain. In real-world scenarios, particularly in multi-label datasets, label noise is prevalent and severely degrades retrieval performance. Moreover, existing CMH approaches typically overlook the partial semantic overlaps inherent in multi-label data, limiting their robustness and generalization. To tackle these challenges, we propose a novel framework named Semantic-Consistent Bidirectional Contrastive Hashing (SCBCH). The framework comprises two complementary modules: (1) Cross-modal Semantic-Consistent Classification (CSCC), which leverages cross-modal semantic consistency to estimate sample reliability and reduce the impact of noisy labels; (2) Bidirectional Soft Contrastive Hashing (BSCH), which dynamically generates soft contrastive sample pairs based on multi-label semantic overlap, enabling adaptive contrastive learning between semantically similar and dissimilar samples across modalities. Extensive experiments on four widely-used cross-modal retrieval benchmarks validate the effectiveness and robustness of our method, consistently outperforming state-of-the-art approaches under noisy multi-label conditions.
Reliable Disentanglement Multi-view Learning Against View Adversarial Attacks
May 07, 2025Recently, trustworthy multi-view learning has attracted extensive attention because evidence learning can provide reliable uncertainty estimation to enhance the credibility of multi-view predictions. Existing trusted multi-view learning methods implicitly assume that multi-view data is secure. In practice, however, in safety-sensitive applications such as autonomous driving and security monitoring, multi-view data often faces threats from adversarial perturbations, thereby deceiving or disrupting multi-view learning models. This inevitably leads to the adversarial unreliability problem (AUP) in trusted multi-view learning. To overcome this tricky problem, we propose a novel multi-view learning framework, namely Reliable Disentanglement Multi-view Learning (RDML). Specifically, we first propose evidential disentanglement learning to decompose each view into clean and adversarial parts under the guidance of corresponding evidences, which is extracted by a pretrained evidence extractor. Then, we employ the feature recalibration module to mitigate the negative impact of adversarial perturbations and extract potential informative features from them. Finally, to further ignore the irreparable adversarial interferences, a view-level evidential attention mechanism is designed. Extensive experiments on multi-view classification tasks with adversarial attacks show that our RDML outperforms the state-of-the-art multi-view learning methods by a relatively large margin.
Robust Duality Learning for Unsupervised Visible-Infrared Person Re-Identfication
May 05, 2025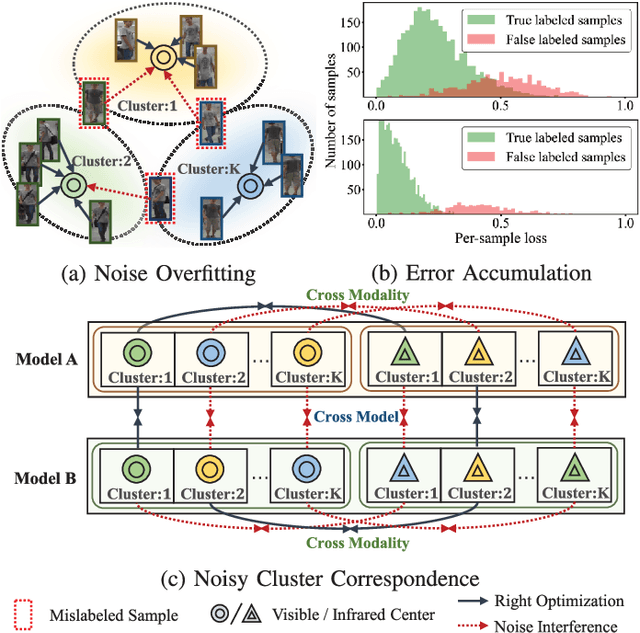
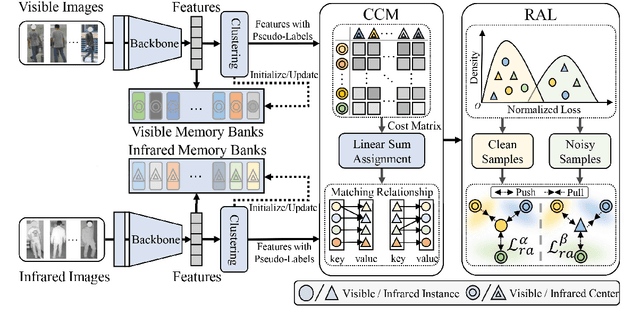
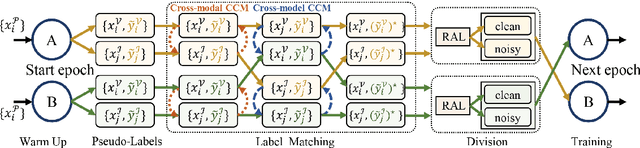
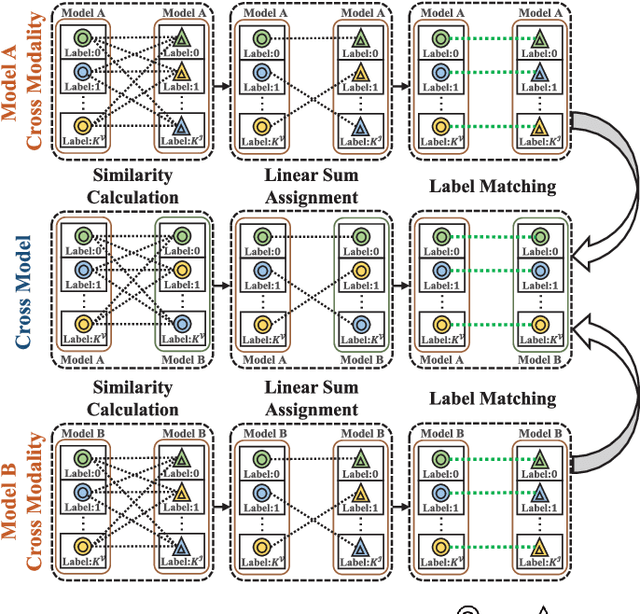
Unsupervised visible-infrared person re-identification (UVI-ReID) aims to retrieve pedestrian images across different modalities without costly annotations, but faces challenges due to the modality gap and lack of supervision. Existing methods often adopt self-training with clustering-generated pseudo-labels but implicitly assume these labels are always correct. In practice, however, this assumption fails due to inevitable pseudo-label noise, which hinders model learning. To address this, we introduce a new learning paradigm that explicitly considers Pseudo-Label Noise (PLN), characterized by three key challenges: noise overfitting, error accumulation, and noisy cluster correspondence. To this end, we propose a novel Robust Duality Learning framework (RoDE) for UVI-ReID to mitigate the effects of noisy pseudo-labels. First, to combat noise overfitting, a Robust Adaptive Learning mechanism (RAL) is proposed to dynamically emphasize clean samples while down-weighting noisy ones. Second, to alleviate error accumulation-where the model reinforces its own mistakes-RoDE employs dual distinct models that are alternately trained using pseudo-labels from each other, encouraging diversity and preventing collapse. However, this dual-model strategy introduces misalignment between clusters across models and modalities, creating noisy cluster correspondence. To resolve this, we introduce Cluster Consistency Matching (CCM), which aligns clusters across models and modalities by measuring cross-cluster similarity. Extensive experiments on three benchmarks demonstrate the effectiveness of RoDE.
LLaVA-ReID: Selective Multi-image Questioner for Interactive Person Re-Identification
Apr 15, 2025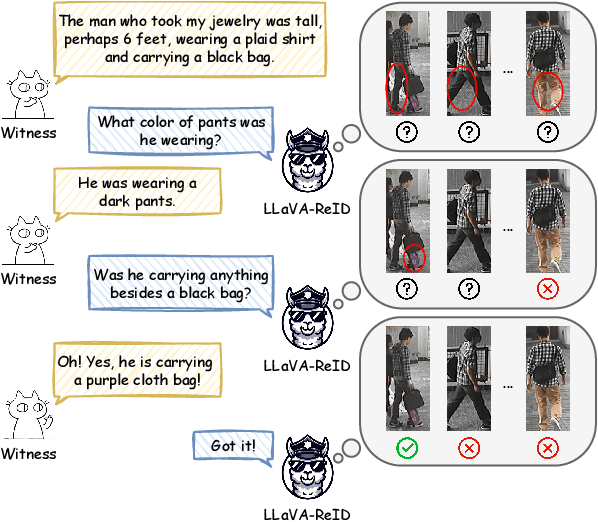
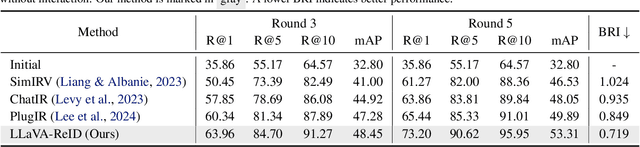
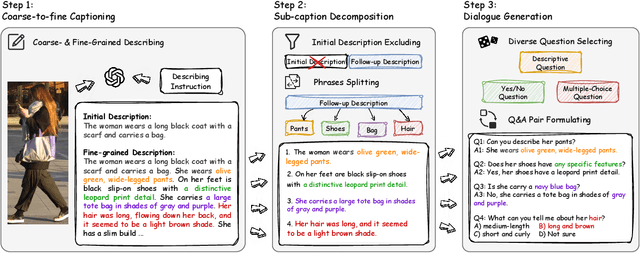
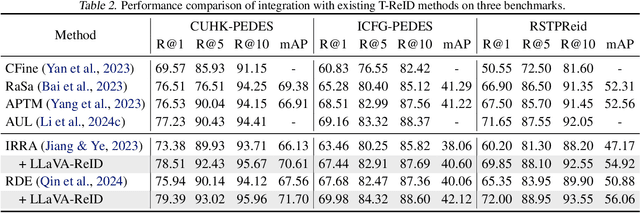
Traditional text-based person ReID assumes that person descriptions from witnesses are complete and provided at once. However, in real-world scenarios, such descriptions are often partial or vague. To address this limitation, we introduce a new task called interactive person re-identification (Inter-ReID). Inter-ReID is a dialogue-based retrieval task that iteratively refines initial descriptions through ongoing interactions with the witnesses. To facilitate the study of this new task, we construct a dialogue dataset that incorporates multiple types of questions by decomposing fine-grained attributes of individuals. We further propose LLaVA-ReID, a question model that generates targeted questions based on visual and textual contexts to elicit additional details about the target person. Leveraging a looking-forward strategy, we prioritize the most informative questions as supervision during training. Experimental results on both Inter-ReID and text-based ReID benchmarks demonstrate that LLaVA-ReID significantly outperforms baselines.
Deep Reversible Consistency Learning for Cross-modal Retrieval
Jan 10, 2025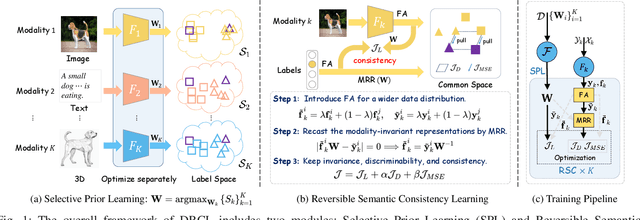
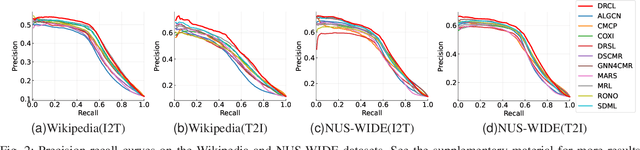
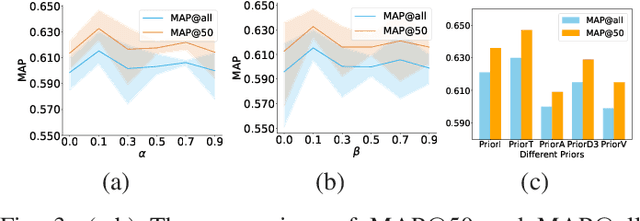
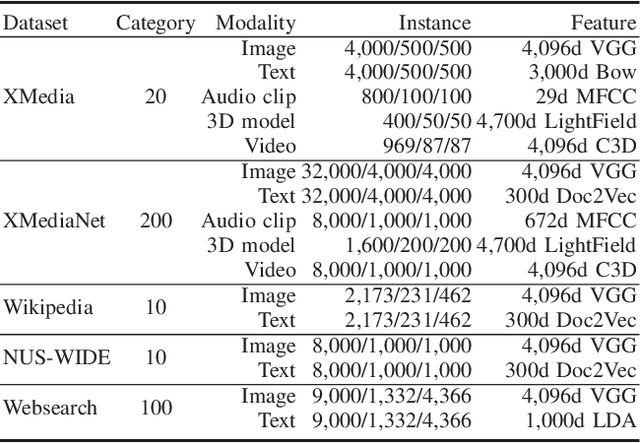
Cross-modal retrieval (CMR) typically involves learning common representations to directly measure similarities between multimodal samples. Most existing CMR methods commonly assume multimodal samples in pairs and employ joint training to learn common representations, limiting the flexibility of CMR. Although some methods adopt independent training strategies for each modality to improve flexibility in CMR, they utilize the randomly initialized orthogonal matrices to guide representation learning, which is suboptimal since they assume inter-class samples are independent of each other, limiting the potential of semantic alignments between sample representations and ground-truth labels. To address these issues, we propose a novel method termed Deep Reversible Consistency Learning (DRCL) for cross-modal retrieval. DRCL includes two core modules, \ie Selective Prior Learning (SPL) and Reversible Semantic Consistency learning (RSC). More specifically, SPL first learns a transformation weight matrix on each modality and selects the best one based on the quality score as the Prior, which greatly avoids blind selection of priors learned from low-quality modalities. Then, RSC employs a Modality-invariant Representation Recasting mechanism (MRR) to recast the potential modality-invariant representations from sample semantic labels by the generalized inverse matrix of the prior. Since labels are devoid of modal-specific information, we utilize the recast features to guide the representation learning, thus maintaining semantic consistency to the fullest extent possible. In addition, a feature augmentation mechanism (FA) is introduced in RSC to encourage the model to learn over a wider data distribution for diversity. Finally, extensive experiments conducted on five widely used datasets and comparisons with 15 state-of-the-art baselines demonstrate the effectiveness and superiority of our DRCL.
Robust Self-Paced Hashing for Cross-Modal Retrieval with Noisy Labels
Jan 03, 2025



Cross-modal hashing (CMH) has appeared as a popular technique for cross-modal retrieval due to its low storage cost and high computational efficiency in large-scale data. Most existing methods implicitly assume that multi-modal data is correctly labeled, which is expensive and even unattainable due to the inevitable imperfect annotations (i.e., noisy labels) in real-world scenarios. Inspired by human cognitive learning, a few methods introduce self-paced learning (SPL) to gradually train the model from easy to hard samples, which is often used to mitigate the effects of feature noise or outliers. It is a less-touched problem that how to utilize SPL to alleviate the misleading of noisy labels on the hash model. To tackle this problem, we propose a new cognitive cross-modal retrieval method called Robust Self-paced Hashing with Noisy Labels (RSHNL), which can mimic the human cognitive process to identify the noise while embracing robustness against noisy labels. Specifically, we first propose a contrastive hashing learning (CHL) scheme to improve multi-modal consistency, thereby reducing the inherent semantic gap. Afterward, we propose center aggregation learning (CAL) to mitigate the intra-class variations. Finally, we propose Noise-tolerance Self-paced Hashing (NSH) that dynamically estimates the learning difficulty for each instance and distinguishes noisy labels through the difficulty level. For all estimated clean pairs, we further adopt a self-paced regularizer to gradually learn hash codes from easy to hard. Extensive experiments demonstrate that the proposed RSHNL performs remarkably well over the state-of-the-art CMH methods.