 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Optimal Sample Complexity for Online Constrained MDPs
Feb 16, 2026Safety is a fundamental challenge in reinforcement learning (RL), particularly in real-world applications such as autonomous driving, robotics, and healthcare. To address this, Constrained Markov Decision Processes (CMDPs) are commonly used to enforce safety constraints while optimizing performance. However, existing methods often suffer from significant safety violations or require a high sample complexity to generate near-optimal policies. We address two settings: relaxed feasibility, where small violations are allowed, and strict feasibility, where no violation is allowed. We propose a model-based primal-dual algorithm that balances regret and bounded constraint violations, drawing on techniques from online RL and constrained optimization. For relaxed feasibility, we prove that our algorithm returns an $\varepsilon$-optimal policy with $\varepsilon$-bounded violation with arbitrarily high probability, requiring $\tilde{O}\left(\frac{SAH^3}{\varepsilon^2}\right)$ learning episodes, matching the lower bound for unconstrained MDPs. For strict feasibility, we prove that our algorithm returns an $\varepsilon$-optimal policy with zero violation with arbitrarily high probability, requiring $\tilde{O}\left(\frac{SAH^5}{\varepsilon^2ζ^2}\right)$ learning episodes, where $ζ$ is the problem-dependent Slater constant characterizing the size of the feasible region. This result matches the lower bound for learning CMDPs with access to a generative model. Our results demonstrate that learning CMDPs in an online setting is as easy as learning with a generative model and is no more challenging than learning unconstrained MDPs when small violations are allowed.
Generalizable and Robust Beam Prediction for 6G Networks: An Deep-Learning Framework with Positioning Feature Fusion
Feb 10, 2026Beamforming (BF) is essential for enhancing system capacity in fifth generation (5G) and beyond wireless networks, yet exhaustive beam training in ultra-massive multiple-input multiple-output (MIMO) systems incurs substantial overhead. To address this challenge, we propose a deep learning based framework that leverages position-aware features to improve beam prediction accuracy while reducing training costs. The proposed approach uses spatial coordinate labels to supervise a position extraction branch and integrates the resulting representations with beam-domain features through a feature fusion module. A dual-branch RegNet architecture is adopted to jointly learn location related and communication features for beam prediction. Two fusion strategies, namely adaptive fusion and adversarial fusion, are introduced to enable efficient feature integration. The proposed framework is evaluated on datasets generated by the DeepMIMO simulator across four urban scenarios at 3.5 GHz following 3GPP specifications, where both reference signal received power and user equipment location information are available. Simulation results under both in-distribution and out-of-distribution settings demonstrate that the proposed approach consistently outperforms traditional baselines and achieves more accurate and robust beam prediction by effectively incorporating positioning information.
Chain-of-Memory: Lightweight Memory Construction with Dynamic Evolution for LLM Agents
Jan 14, 2026External memory systems are pivotal for enabling Large Language Model (LLM) agents to maintain persistent knowledge and perform long-horizon decision-making. Existing paradigms typically follow a two-stage process: computationally expensive memory construction (e.g., structuring data into graphs) followed by naive retrieval-augmented generation. However, our empirical analysis reveals two fundamental limitations: complex construction incurs high costs with marginal performance gains, and simple context concatenation fails to bridge the gap between retrieval recall and reasoning accuracy. To address these challenges, we propose CoM (Chain-of-Memory), a novel framework that advocates for a paradigm shift toward lightweight construction paired with sophisticated utilization. CoM introduces a Chain-of-Memory mechanism that organizes retrieved fragments into coherent inference paths through dynamic evolution, utilizing adaptive truncation to prune irrelevant noise. Extensive experiments on the LongMemEval and LoCoMo benchmarks demonstrate that CoM outperforms strong baselines with accuracy gains of 7.5%-10.4%, while drastically reducing computational overhead to approximately 2.7% of token consumption and 6.0% of latency compared to complex memory architectures.
Beyond Entangled Planning: Task-Decoupled Planning for Long-Horizon Agents
Jan 12, 2026Recent advances in large language models (LLMs) have enabled agents to autonomously execute complex, long-horizon tasks, yet planning remains a primary bottleneck for reliable task execution. Existing methods typically fall into two paradigms: step-wise planning, which is reactive but often short-sighted; and one-shot planning, which generates a complete plan upfront yet is brittle to execution errors. Crucially, both paradigms suffer from entangled contexts, where the agent must reason over a monolithic history spanning multiple sub-tasks. This entanglement increases cognitive load and lets local errors propagate across otherwise independent decisions, making recovery computationally expensive. To address this, we propose Task-Decoupled Planning (TDP), a training-free framework that replaces entangled reasoning with task decoupling. TDP decomposes tasks into a directed acyclic graph (DAG) of sub-goals via a Supervisor. Using a Planner and Executor with scoped contexts, TDP confines reasoning and replanning to the active sub-task. This isolation prevents error propagation and corrects deviations locally without disrupting the workflow. Results on TravelPlanner, ScienceWorld, and HotpotQA show that TDP outperforms strong baselines while reducing token consumption by up to 82%, demonstrating that sub-task decoupling improves both robustness and efficiency for long-horizon agents.
Conditional Representation Learning for Customized Tasks
Oct 06, 2025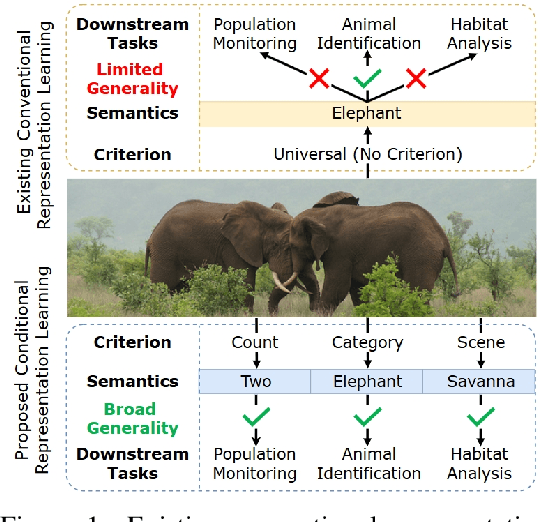

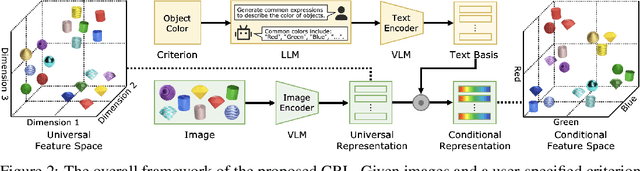
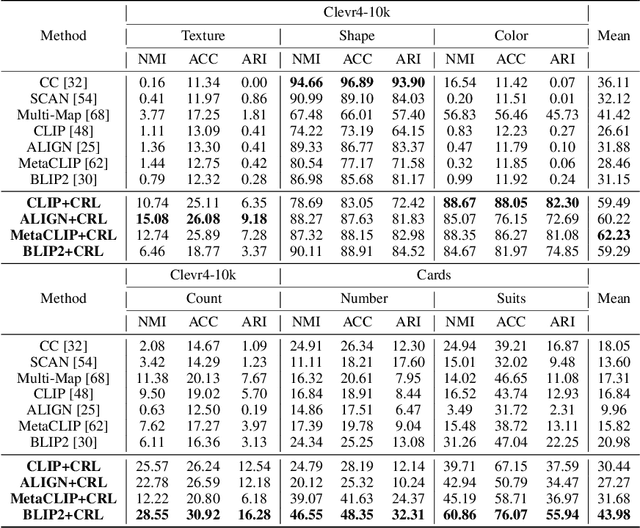
Conventional representation learning methods learn a universal representation that primarily captures dominant semantics, which may not always align with customized downstream tasks. For instance, in animal habitat analysis, researchers prioritize scene-related features, whereas universal embeddings emphasize categorical semantics, leading to suboptimal results. As a solution, existing approaches resort to supervised fine-tuning, which however incurs high computational and annotation costs. In this paper, we propose Conditional Representation Learning (CRL), aiming to extract representations tailored to arbitrary user-specified criteria. Specifically, we reveal that the semantics of a space are determined by its basis, thereby enabling a set of descriptive words to approximate the basis for a customized feature space. Building upon this insight, given a user-specified criterion, CRL first employs a large language model (LLM) to generate descriptive texts to construct the semantic basis, then projects the image representation into this conditional feature space leveraging a vision-language model (VLM). The conditional representation better captures semantics for the specific criterion, which could be utilized for multiple customized tasks. Extensive experiments on classification and retrieval tasks demonstrate the superiority and generality of the proposed CRL. The code is available at https://github.com/XLearning-SCU/2025-NeurIPS-CRL.
DUDE: Diffusion-Based Unsupervised Cross-Domain Image Retrieval
Sep 04, 2025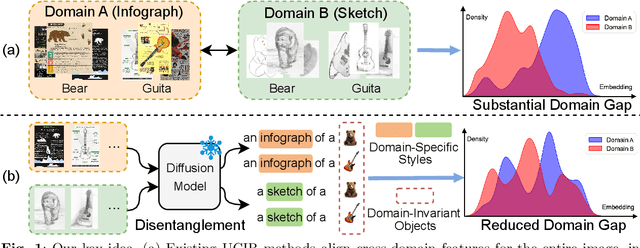
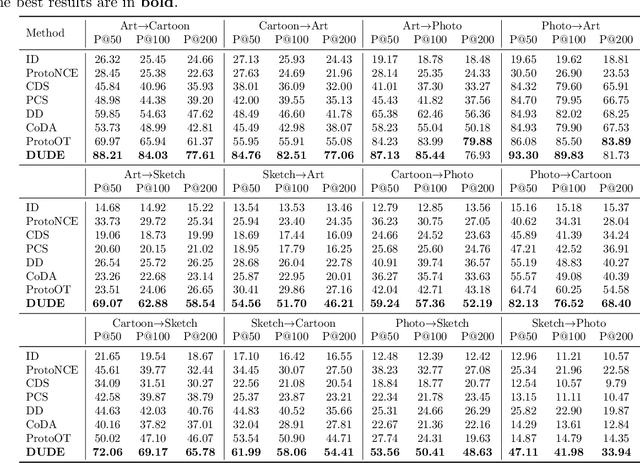
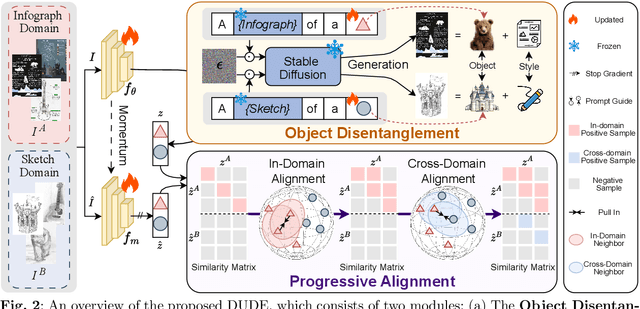
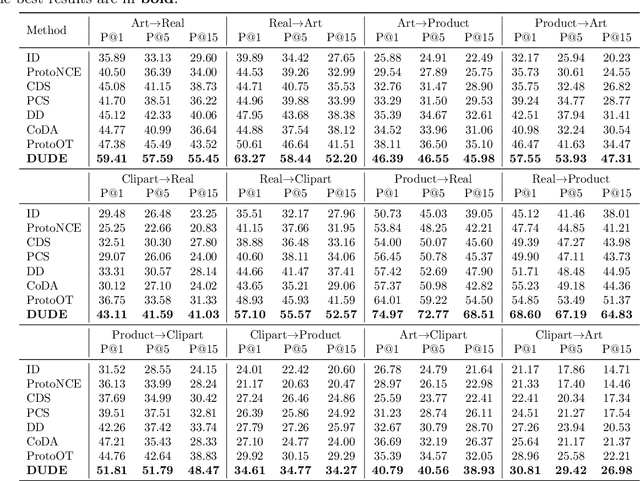
Unsupervised cross-domain image retrieval (UCIR) aims to retrieve images of the same category across diverse domains without relying on annotations. Existing UCIR methods, which align cross-domain features for the entire image, often struggle with the domain gap, as the object features critical for retrieval are frequently entangled with domain-specific styles. To address this challenge, we propose DUDE, a novel UCIR method building upon feature disentanglement. In brief, DUDE leverages a text-to-image generative model to disentangle object features from domain-specific styles, thus facilitating semantical image retrieval. To further achieve reliable alignment of the disentangled object features, DUDE aligns mutual neighbors from within domains to across domains in a progressive manner. Extensive experiments demonstrate that DUDE achieves state-of-the-art performance across three benchmark datasets over 13 domains. The code will be released.
A MIMO Wireless Channel Foundation Model via CIR-CSI Consistency
Feb 17, 2025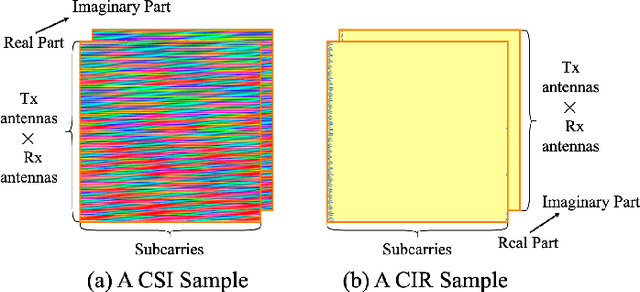
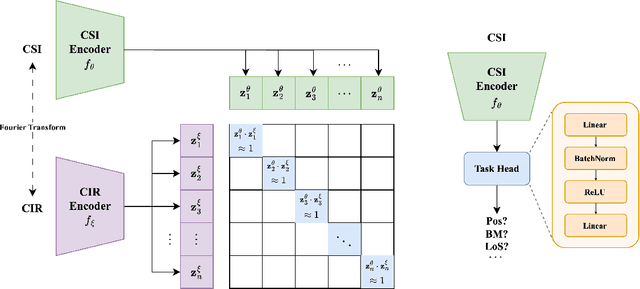
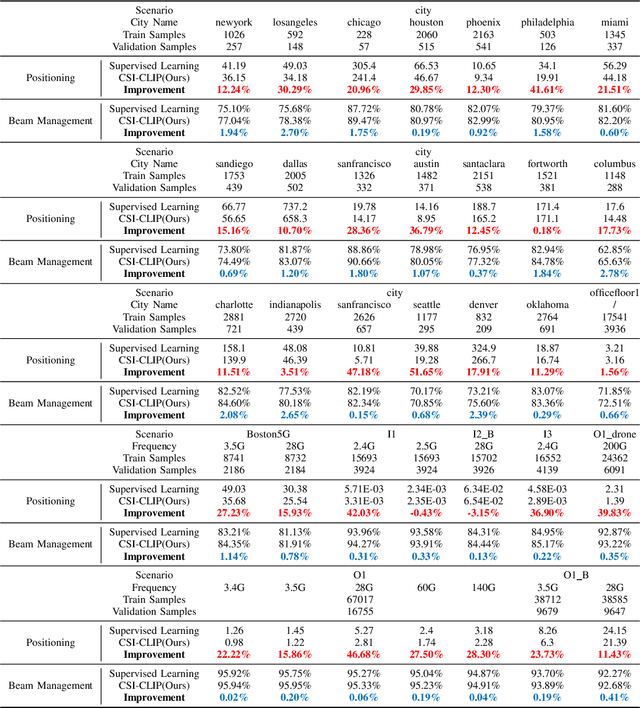
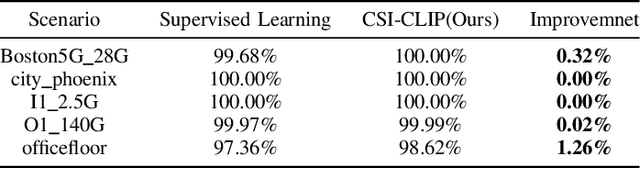
In the field of artificial intelligence, self-supervised learning has demonstrated superior generalization capabilities by leveraging large-scale unlabeled datasets for pretraining, which is especially critical for wireless communication models to adapt to a variety of scenarios. This paper innovatively treats Channel State Information (CSI) and Channel Impulse Response (CIR) as naturally aligned multi-modal data and proposes the first MIMO wireless channel foundation model, named CSI-CLIP. By effectively capturing the joint representations of both CIR and CSI, CSI-CLIP exhibits remarkable adaptability across scenarios and robust feature extraction capabilities. Experimental results show that in positioning task, CSI-CLIP reduces the mean error distance by 22%; in beam management task, it increases accuracy by 1% compared to traditional supervised methods, as well as in the channel identification task. These improvements not only highlight the potential and value of CSI-CLIP in integrating sensing and communication but also demonstrate its significant advantages over existing techniques. Moreover, viewing CSI and CIR as multi-modal pairs and contrastive learning for wireless channel foundation model open up new research directions in the domain of MIMO wireless communications.
DiFiC: Your Diffusion Model Holds the Secret to Fine-Grained Clustering
Dec 25, 2024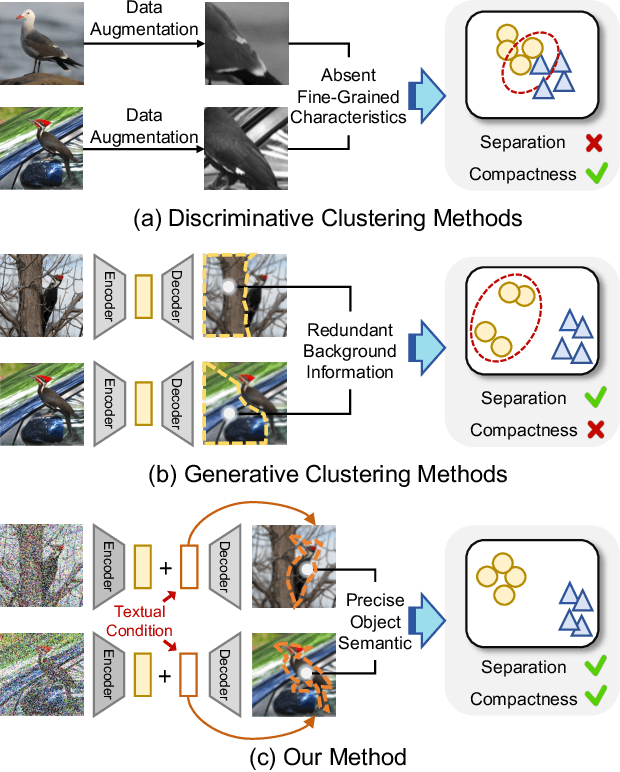
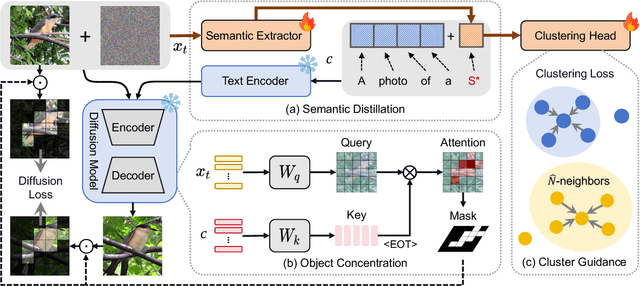
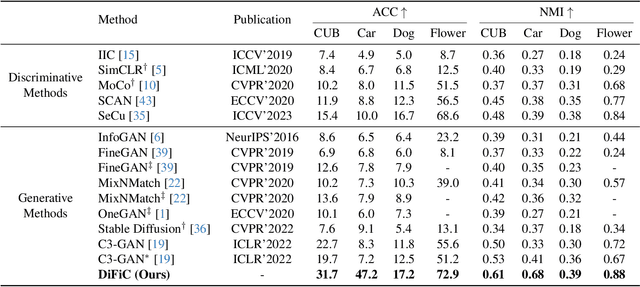
Fine-grained clustering is a practical yet challenging task, whose essence lies in capturing the subtle differences between instances of different classes. Such subtle differences can be easily disrupted by data augmentation or be overwhelmed by redundant information in data, leading to significant performance degradation for existing clustering methods. In this work, we introduce DiFiC a fine-grained clustering method building upon the conditional diffusion model. Distinct from existing works that focus on extracting discriminative features from images, DiFiC resorts to deducing the textual conditions used for image generation. To distill more precise and clustering-favorable object semantics, DiFiC further regularizes the diffusion target and guides the distillation process utilizing neighborhood similarity. Extensive experiments demonstrate that DiFiC outperforms both state-of-the-art discriminative and generative clustering methods on four fine-grained image clustering benchmarks. We hope the success of DiFiC will inspire future research to unlock the potential of diffusion models in tasks beyond generation. The code will be released.
Hyper: Hyperparameter Robust Efficient Exploration in Reinforcement Learning
Dec 04, 2024



The exploration \& exploitation dilemma poses significant challenges in reinforcement learning (RL). Recently, curiosity-based exploration methods achieved great success in tackling hard-exploration problems. However, they necessitate extensive hyperparameter tuning on different environments, which heavily limits the applicability and accessibility of this line of methods. In this paper, we characterize this problem via analysis of the agent behavior, concluding the fundamental difficulty of choosing a proper hyperparameter. We then identify the difficulty and the instability of the optimization when the agent learns with curiosity. We propose our method, hyperparameter robust exploration (\textbf{Hyper}), which extensively mitigates the problem by effectively regularizing the visitation of the exploration and decoupling the exploitation to ensure stable training. We theoretically justify that \textbf{Hyper} is provably efficient under function approximation setting and empirically demonstrate its appealing performance and robustness in various environments.
A Survey on Deep Clustering: From the Prior Perspective
Jun 28, 2024Facilitated by the powerful feature extraction ability of neural networks, deep clustering has achieved great success in analyzing high-dimensional and complex real-world data. The performance of deep clustering methods is affected by various factors such as network structures and learning objectives. However, as pointed out in this survey, the essence of deep clustering lies in the incorporation and utilization of prior knowledge, which is largely ignored by existing works. From pioneering deep clustering methods based on data structure assumptions to recent contrastive clustering methods based on data augmentation invariances, the development of deep clustering intrinsically corresponds to the evolution of prior knowledge. In this survey, we provide a comprehensive review of deep clustering methods by categorizing them into six types of prior knowledge. We find that in general the prior innovation follows two trends, namely, i) from mining to constructing, and ii) from internal to external. Besides, we provide a benchmark on five widely-used datasets and analyze the performance of methods with diverse priors. By providing a novel prior knowledge perspective, we hope this survey could provide some novel insights and inspire future research in the deep clustering community.