 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARTIAN: A Rendering Framework for Aerial Mars Imagery from HiRISE Orbital Data
May 28, 2026Aerial navigation on Mars requires vision-based pipelines that are robust to the diverse illumination conditions and terrain morphology of the Martian surface. A key bottleneck for training and evaluating such methods is the scarcity of large-scale, annotated aerial datasets. We present MARTIAN, an open-source Blender-based rendering framework that leverages real HiRISE orbital map products to synthesize realistic aerial views of the Martian terrain under controllable lighting conditions and at varying altitudes. MARTIAN generates observations with accurate pose annotations, directly addressing the scarcity of training data for vision-based navigation on Mars. The framework has been validated through its deployment in concurrent work on map-based localization systems for Ingenuity and future Mars rotorcraft, where synthetically trained deep image matchers were successfully evaluated on real Mars imagery. MARTIAN is publicly available at: https://github.com/nasa-jpl/martian.
NAVCON: A Cognitively Inspired and Linguistically Grounded Corpus for Vision and Language Navigation
Dec 17, 2024We present NAVCON, a large-scale annotated Vision-Language Navigation (VLN) corpus built on top of two popular datasets (R2R and RxR). The paper introduces four core, cognitively motivated and linguistically grounded, navigation concepts and an algorithm for generating large-scale silver annotations of naturally occurring linguistic realizations of these concepts in navigation instructions. We pair the annotated instructions with video clips of an agent acting on these instructions. NAVCON contains 236, 316 concept annotations for approximately 30, 0000 instructions and 2.7 million aligned images (from approximately 19, 000 instructions) showing what the agent sees when executing an instruction. To our knowledge, this is the first comprehensive resource of navigation concepts. We evaluated the quality of the silver annotations by conducting human evaluation studies on NAVCON samples. As further validation of the quality and usefulness of the resource, we trained a model for detecting navigation concepts and their linguistic realizations in unseen instructions. Additionally, we show that few-shot learning with GPT-4o performs well on this task using large-scale silver annotations of NAVCON.
Pixel to Elevation: Learning to Predict Elevation Maps at Long Range using Images for Autonomous Offroad Navigation
Jan 30, 2024Understanding terrain topology at long-range is crucial for the success of off-road robotic missions, especially when navigating at high-speeds. LiDAR sensors, which are currently heavily relied upon for geometric mapping, provide sparse measurements when mapping at greater distances. To address this challenge, we present a novel learning-based approach capable of predicting terrain elevation maps at long-range using only onboard egocentric images in real-time. Our proposed method is comprised of three main elements. First, a transformer-based encoder is introduced that learns cross-view associations between the egocentric views and prior bird-eye-view elevation map predictions. Second, an orientation-aware positional encoding is proposed to incorporate the 3D vehicle pose information over complex unstructured terrain with multi-view visual image features. Lastly, a history-augmented learn-able map embedding is proposed to achieve better temporal consistency between elevation map predictions to facilitate the downstream navigational tasks. We experimentally validate the applicability of our proposed approach for autonomous offroad robotic navigation in complex and unstructured terrain using real-world offroad driving data. Furthermore, the method is qualitatively and quantitatively compared against the current state-of-the-art methods. Extensive field experiments demonstrate that our method surpasses baseline models in accurately predicting terrain elevation while effectively capturing the overall terrain topology at long-ranges. Finally, ablation studies are conducted to highlight and understand the effect of key components of the proposed approach and validate their suitability to improve offroad robotic navigation capabilities.
Icy Moon Surface Simulation and Stereo Depth Estimation for Sampling Autonomy
Jan 23, 2024Sampling autonomy for icy moon lander missions requires understanding of topographic and photometric properties of the sampling terrain. Unavailability of high resolution visual datasets (either bird-eye view or point-of-view from a lander) is an obstacle for selection, verification or development of perception systems. We attempt to alleviate this problem by: 1) proposing Graphical Utility for Icy moon Surface Simulations (GUISS) framework, for versatile stereo dataset generation that spans the spectrum of bulk photometric properties, and 2) focusing on a stereo-based visual perception system and evaluating both traditional and deep learning-based algorithms for depth estimation from stereo matching. The surface reflectance properties of icy moon terrains (Enceladus and Europa) are inferred from multispectral datasets of previous missions. With procedural terrain generation and physically valid illumination sources, our framework can fit a wide range of hypotheses with respect to visual representations of icy moon terrains. This is followed by a study over the performance of stereo matching algorithms under different visual hypotheses. Finally, we emphasize the standing challenges to be addressed for simulating perception data assets for icy moons such as Enceladus and Europa. Our code can be found here: https://github.com/nasa-jpl/guiss.
Automated Assessment of Critical View of Safety in Laparoscopic Cholecystectomy
Sep 13, 2023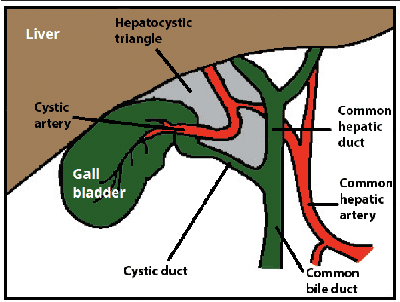
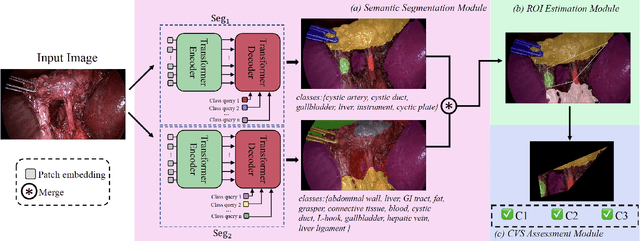
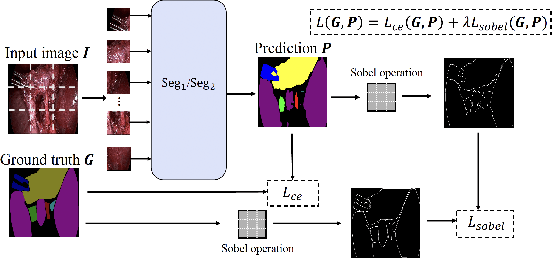
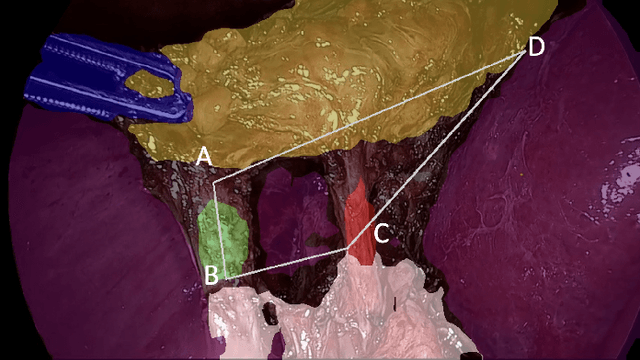
Cholecystectomy (gallbladder removal) is one of the most common procedures in the US, with more than 1.2M procedures annually. Compared with classical open cholecystectomy, laparoscopic cholecystectomy (LC) is associated with significantly shorter recovery period, and hence is the preferred method. However, LC is also associated with an increase in bile duct injuries (BDIs), resulting in significant morbidity and mortality. The primary cause of BDIs from LCs is misidentification of the cystic duct with the bile duct. Critical view of safety (CVS) is the most effective of safety protocols, which is said to be achieved during the surgery if certain criteria are met. However, due to suboptimal understanding and implementation of CVS, the BDI rates have remained stable over the last three decades. In this paper, we develop deep-learning techniques to automate the assessment of CVS in LCs. An innovative aspect of our research is on developing specialized learning techniques by incorporating domain knowledge to compensate for the limited training data available in practice. In particular, our CVS assessment process involves a fusion of two segmentation maps followed by an estimation of a certain region of interest based on anatomical structures close to the gallbladder, and then finally determination of each of the three CVS criteria via rule-based assessment of structural information. We achieved a gain of over 11.8% in mIoU on relevant classes with our two-stream semantic segmentation approach when compared to a single-model baseline, and 1.84% in mIoU with our proposed Sobel loss function when compared to a Transformer-based baseline model. For CVS criteria, we achieved up to 16% improvement and, for the overall CVS assessment, we achieved 5% improvement in balanced accuracy compared to DeepCVS under the same experiment settings.
Cross-modal Map Learning for Vision and Language Navigation
Mar 21, 2022
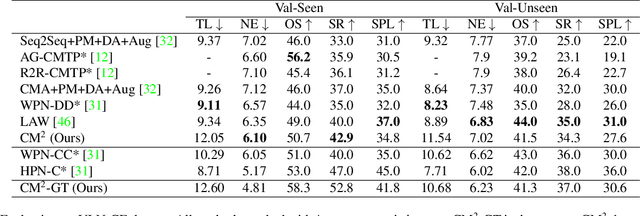
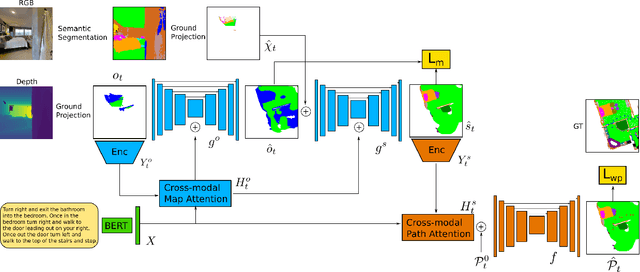
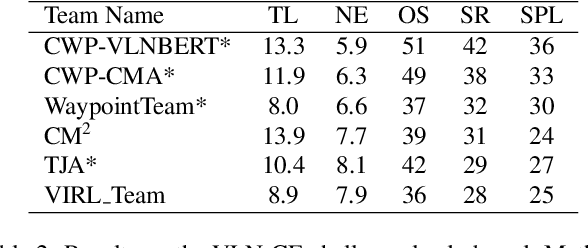
We consider the problem of Vision-and-Language Navigation (VLN). The majority of current methods for VLN are trained end-to-end using either unstructured memory such as LSTM, or using cross-modal attention over the egocentric observations of the agent. In contrast to other works, our key insight is that the association between language and vision is stronger when it occurs in explicit spatial representations. In this work, we propose a cross-modal map learning model for vision-and-language navigation that first learns to predict the top-down semantics on an egocentric map for both observed and unobserved regions, and then predicts a path towards the goal as a set of waypoints. In both cases, the prediction is informed by the language through cross-modal attention mechanisms. We experimentally test the basic hypothesis that language-driven navigation can be solved given a map, and then show competitive results on the full VLN-CE benchmark.
Uncertainty-driven Planner for Exploration and Navigation
Feb 24, 2022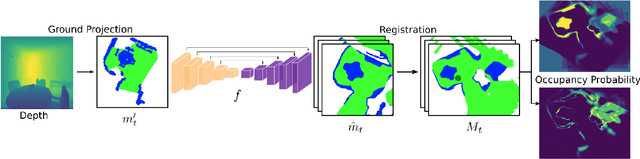
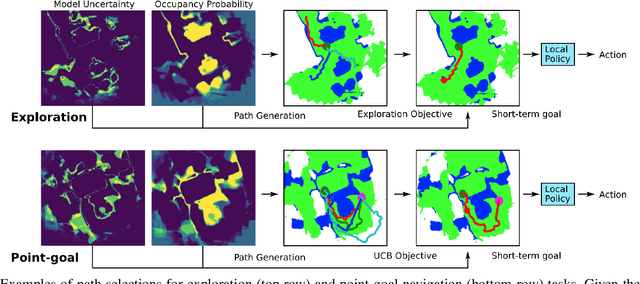
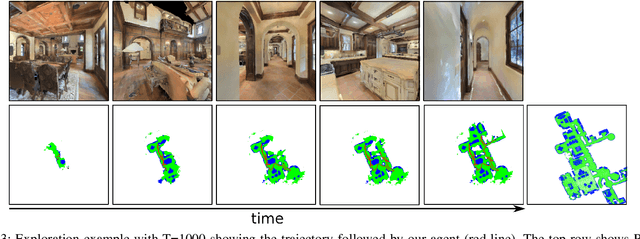
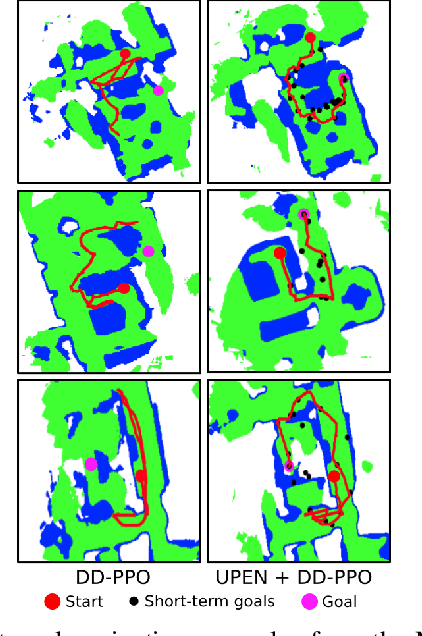
We consider the problems of exploration and point-goal navigation in previously unseen environments, where the spatial complexity of indoor scenes and partial observability constitute these tasks challenging. We argue that learning occupancy priors over indoor maps provides significant advantages towards addressing these problems. To this end, we present a novel planning framework that first learns to generate occupancy maps beyond the field-of-view of the agent, and second leverages the model uncertainty over the generated areas to formulate path selection policies for each task of interest. For point-goal navigation the policy chooses paths with an upper confidence bound policy for efficient and traversable paths, while for exploration the policy maximizes model uncertainty over candidate paths. We perform experiments in the visually realistic environments of Matterport3D using the Habitat simulator and demonstrate: 1) Improved results on exploration and map quality metrics over competitive methods, and 2) The effectiveness of our planning module when paired with the state-of-the-art DD-PPO method for the point-goal navigation task.
Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets
Sep 27, 2021
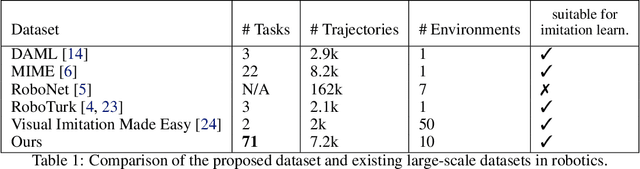

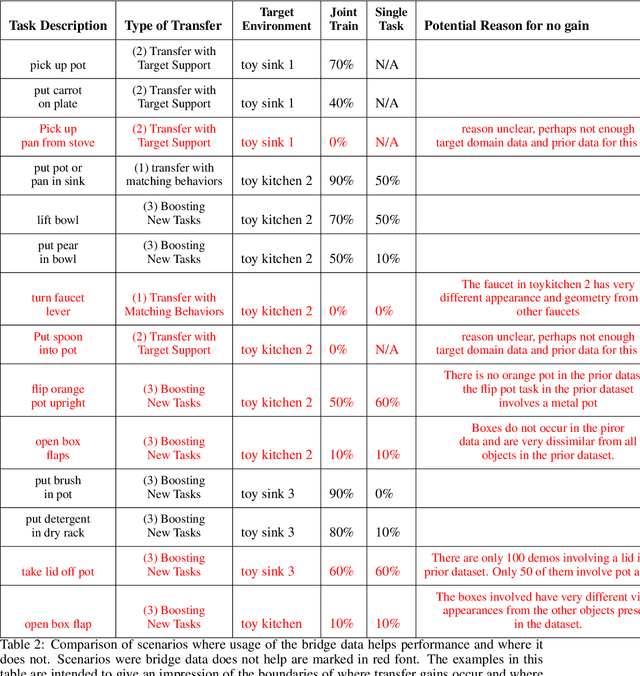
Robot learning holds the promise of learning policies that generalize broadly. However, such generalization requires sufficiently diverse datasets of the task of interest, which can be prohibitively expensive to collect. In other fields, such as computer vision, it is common to utilize shared, reusable datasets, such as ImageNet, to overcome this challenge, but this has proven difficult in robotics. In this paper, we ask: what would it take to enable practical data reuse in robotics for end-to-end skill learning? We hypothesize that the key is to use datasets with multiple tasks and multiple domains, such that a new user that wants to train their robot to perform a new task in a new domain can include this dataset in their training process and benefit from cross-task and cross-domain generalization. To evaluate this hypothesis, we collect a large multi-domain and multi-task dataset, with 7,200 demonstrations constituting 71 tasks across 10 environments, and empirically study how this data can improve the learning of new tasks in new environments. We find that jointly training with the proposed dataset and 50 demonstrations of a never-before-seen task in a new domain on average leads to a 2x improvement in success rate compared to using target domain data alone. We also find that data for only a few tasks in a new domain can bridge the domain gap and make it possible for a robot to perform a variety of prior tasks that were only seen in other domains. These results suggest that reusing diverse multi-task and multi-domain datasets, including our open-source dataset, may pave the way for broader robot generalization, eliminating the need to re-collect data for each new robot learning project.
Learning to Map for Active Semantic Goal Navigation
Jun 29, 2021
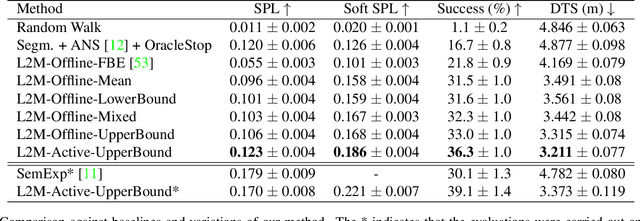
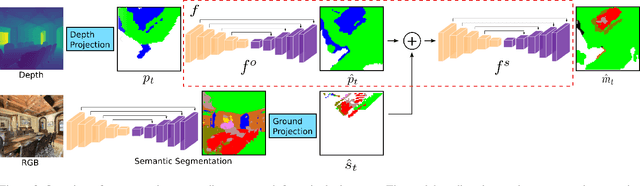

We consider the problem of object goal navigation in unseen environments. In our view, solving this problem requires learning of contextual semantic priors, a challenging endeavour given the spatial and semantic variability of indoor environments. Current methods learn to implicitly encode these priors through goal-oriented navigation policy functions operating on spatial representations that are limited to the agent's observable areas. In this work, we propose a novel framework that actively learns to generate semantic maps outside the field of view of the agent and leverages the uncertainty over the semantic classes in the unobserved areas to decide on long term goals. We demonstrate that through this spatial prediction strategy, we are able to learn semantic priors in scenes that can be leveraged in unknown environments. Additionally, we show how different objectives can be defined by balancing exploration with exploitation during searching for semantic targets. Our method is validated in the visually realistic environments offered by the Matterport3D dataset and show state of the art results on the object goal navigation task.
Object-centric Video Prediction without Annotation
May 06, 2021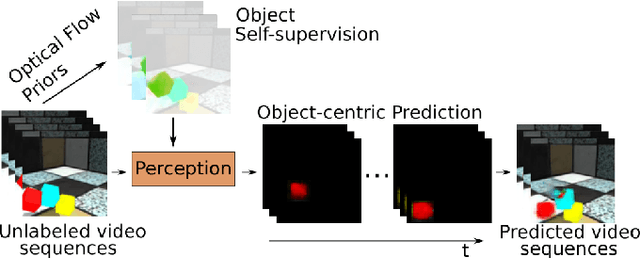
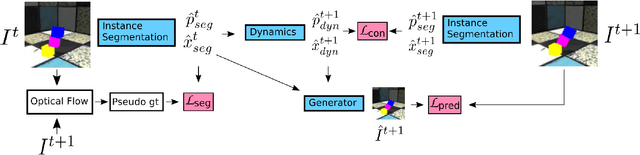

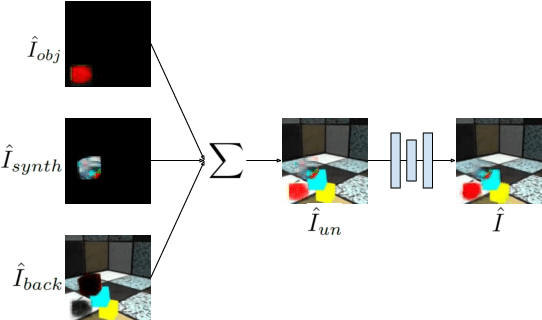
In order to interact with the world, agents must be able to predict the results of the world's dynamics. A natural approach to learn about these dynamics is through video prediction, as cameras are ubiquitous and powerful sensors. Direct pixel-to-pixel video prediction is difficult, does not take advantage of known priors, and does not provide an easy interface to utilize the learned dynamics. Object-centric video prediction offers a solution to these problems by taking advantage of the simple prior that the world is made of objects and by providing a more natural interface for control. However, existing object-centric video prediction pipelines require dense object annotations in training video sequences. In this work, we present Object-centric Prediction without Annotation (OPA), an object-centric video prediction method that takes advantage of priors from powerful computer vision models. We validate our method on a dataset comprised of video sequences of stacked objects falling, and demonstrate how to adapt a perception model in an environment through end-to-end video prediction training.