 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Training for Robots: Offline RL Enables Learning New Tasks from a Handful of Trials
Oct 11, 2022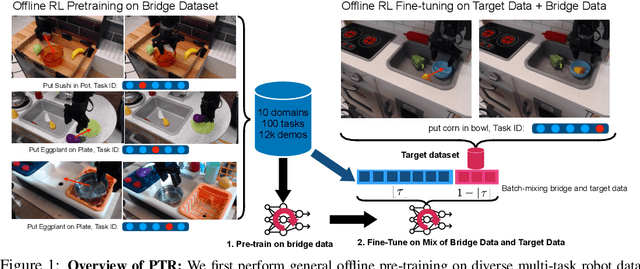

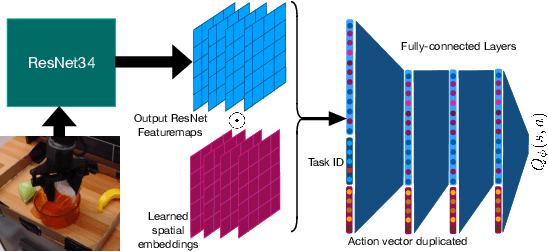

Recent progress in deep learning highlights the tremendous potential of utilizing diverse datasets for achieving effective generalization and makes it enticing to consider leveraging broad datasets for attaining more robust generalization in robotic learning as well. However, in practice we likely will want to learn a new skill in a new environment that is unlikely to be contained in the prior data. Therefore we ask: how can we leverage existing diverse offline datasets in combination with small amounts of task-specific data to solve new tasks, while still enjoying the generalization benefits of training on large amounts of data? In this paper, we demonstrate that end-to-end offline RL can be an effective approach for doing this, without the need for any representation learning or vision-based pre-training. We present pre-training for robots (PTR), a framework based on offline RL that attempts to effectively learn new tasks by combining pre-training on existing robotic datasets with rapid fine-tuning on a new task, with as a few as 10 demonstrations. At its core, PTR applies an existing offline RL method such as conservative Q-learning (CQL), but extends it to include several crucial design decisions that enable PTR to actually work and outperform a variety of prior methods. To the best of our knowledge, PTR is the first offline RL method that succeeds at learning new tasks in a new domain on a real WidowX robot with as few as 10 task demonstrations, by effectively leveraging an existing dataset of diverse multi-task robot data collected in a variety of toy kitchens. Our implementation can be found at: https://github.com/Asap7772/PTR.
BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning
Feb 04, 2022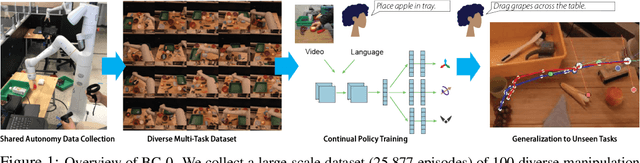
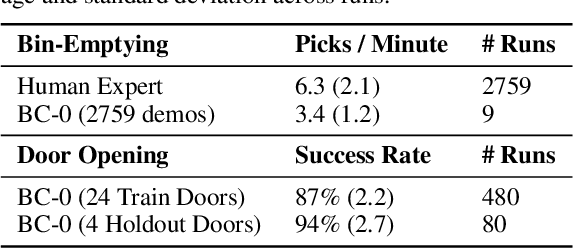

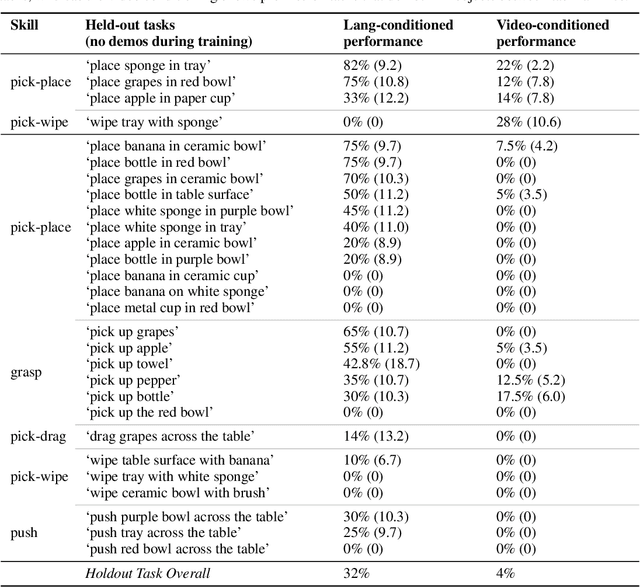
In this paper, we study the problem of enabling a vision-based robotic manipulation system to generalize to novel tasks, a long-standing challenge in robot learning. We approach the challenge from an imitation learning perspective, aiming to study how scaling and broadening the data collected can facilitate such generalization. To that end, we develop an interactive and flexible imitation learning system that can learn from both demonstrations and interventions and can be conditioned on different forms of information that convey the task, including pre-trained embeddings of natural language or videos of humans performing the task. When scaling data collection on a real robot to more than 100 distinct tasks, we find that this system can perform 24 unseen manipulation tasks with an average success rate of 44%, without any robot demonstrations for those tasks.
* CoRL 2021, 23 pages
Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets
Sep 27, 2021
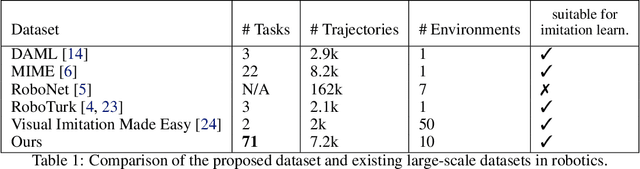

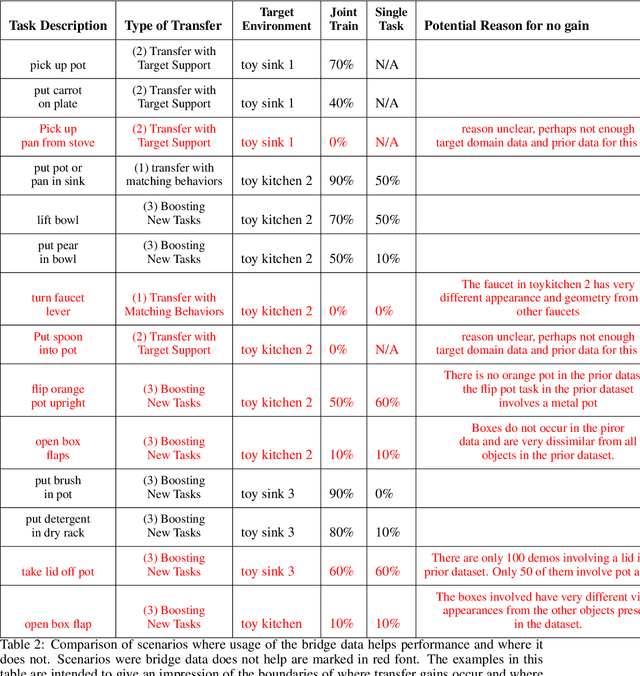
Robot learning holds the promise of learning policies that generalize broadly. However, such generalization requires sufficiently diverse datasets of the task of interest, which can be prohibitively expensive to collect. In other fields, such as computer vision, it is common to utilize shared, reusable datasets, such as ImageNet, to overcome this challenge, but this has proven difficult in robotics. In this paper, we ask: what would it take to enable practical data reuse in robotics for end-to-end skill learning? We hypothesize that the key is to use datasets with multiple tasks and multiple domains, such that a new user that wants to train their robot to perform a new task in a new domain can include this dataset in their training process and benefit from cross-task and cross-domain generalization. To evaluate this hypothesis, we collect a large multi-domain and multi-task dataset, with 7,200 demonstrations constituting 71 tasks across 10 environments, and empirically study how this data can improve the learning of new tasks in new environments. We find that jointly training with the proposed dataset and 50 demonstrations of a never-before-seen task in a new domain on average leads to a 2x improvement in success rate compared to using target domain data alone. We also find that data for only a few tasks in a new domain can bridge the domain gap and make it possible for a robot to perform a variety of prior tasks that were only seen in other domains. These results suggest that reusing diverse multi-task and multi-domain datasets, including our open-source dataset, may pave the way for broader robot generalization, eliminating the need to re-collect data for each new robot learning project.
Model-Based Visual Planning with Self-Supervised Functional Distances
Dec 30, 2020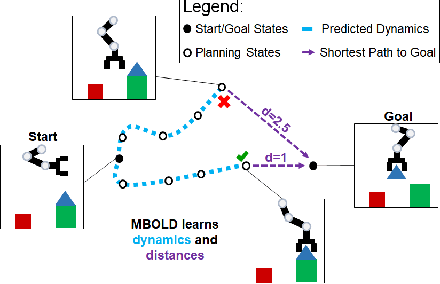
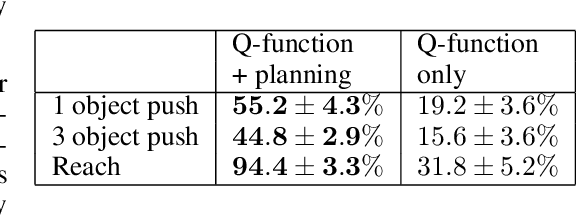
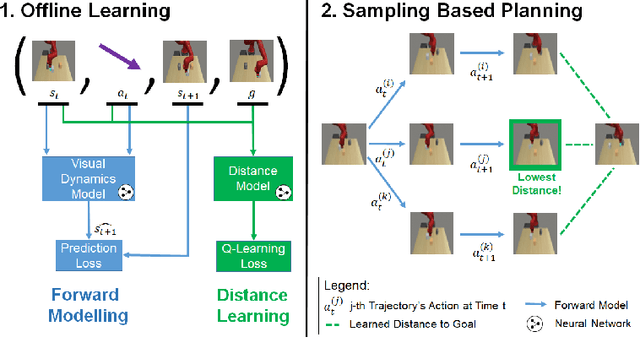
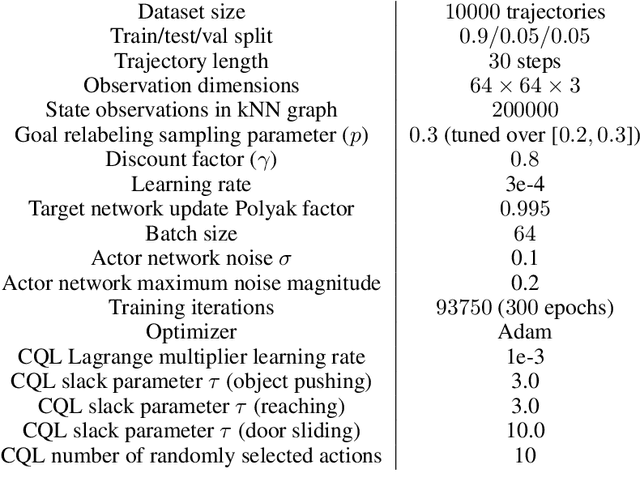
A generalist robot must be able to complete a variety of tasks in its environment. One appealing way to specify each task is in terms of a goal observation. However, learning goal-reaching policies with reinforcement learning remains a challenging problem, particularly when hand-engineered reward functions are not available. Learned dynamics models are a promising approach for learning about the environment without rewards or task-directed data, but planning to reach goals with such a model requires a notion of functional similarity between observations and goal states. We present a self-supervised method for model-based visual goal reaching, which uses both a visual dynamics model as well as a dynamical distance function learned using model-free reinforcement learning. Our approach learns entirely using offline, unlabeled data, making it practical to scale to large and diverse datasets. In our experiments, we find that our method can successfully learn models that perform a variety of tasks at test-time, moving objects amid distractors with a simulated robotic arm and even learning to open and close a drawer using a real-world robot. In comparisons, we find that this approach substantially outperforms both model-free and model-based prior methods. Videos and visualizations are available here: http://sites.google.com/berkeley.edu/mbold.
Long-Horizon Visual Planning with Goal-Conditioned Hierarchical Predictors
Jun 23, 2020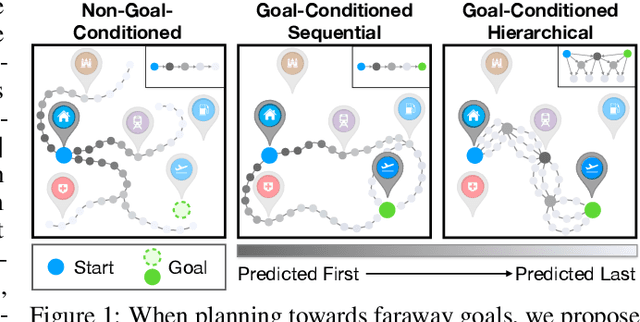
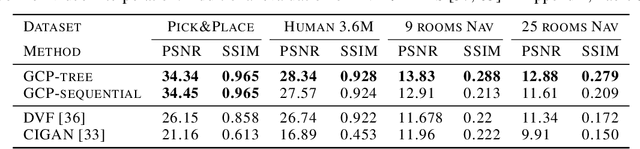

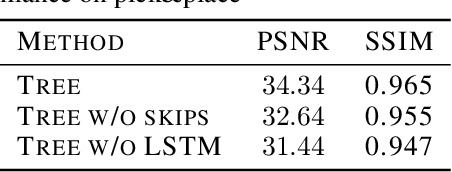
The ability to predict and plan into the future is fundamental for agents acting in the world. To reach a faraway goal, we predict trajectories at multiple timescales, first devising a coarse plan towards the goal and then gradually filling in details. In contrast, current learning approaches for visual prediction and planning fail on long-horizon tasks as they generate predictions (1) without considering goal information, and (2) at the finest temporal resolution, one step at a time. In this work we propose a framework for visual prediction and planning that is able to overcome both of these limitations. First, we formulate the problem of predicting towards a goal and propose the corresponding class of latent space goal-conditioned predictors (GCPs). GCPs significantly improve planning efficiency by constraining the search space to only those trajectories that reach the goal. Further, we show how GCPs can be naturally formulated as hierarchical models that, given two observations, predict an observation between them, and by recursively subdividing each part of the trajectory generate complete sequences. This divide-and-conquer strategy is effective at long-term prediction, and enables us to design an effective hierarchical planning algorithm that optimizes trajectories in a coarse-to-fine manner. We show that by using both goal-conditioning and hierarchical prediction, GCPs enable us to solve visual planning tasks with much longer horizon than previously possible.
OmniTact: A Multi-Directional High Resolution Touch Sensor
Mar 16, 2020



Incorporating touch as a sensing modality for robots can enable finer and more robust manipulation skills. Existing tactile sensors are either flat, have small sensitive fields or only provide low-resolution signals. In this paper, we introduce OmniTact, a multi-directional high-resolution tactile sensor. OmniTact is designed to be used as a fingertip for robotic manipulation with robotic hands, and uses multiple micro-cameras to detect multi-directional deformations of a gel-based skin. This provides a rich signal from which a variety of different contact state variables can be inferred using modern image processing and computer vision methods. We evaluate the capabilities of OmniTact on a challenging robotic control task that requires inserting an electrical connector into an outlet, as well as a state estimation problem that is representative of those typically encountered in dexterous robotic manipulation, where the goal is to infer the angle of contact of a curved finger pressing against an object. Both tasks are performed using only touch sensing and deep convolutional neural networks to process images from the sensor's cameras. We compare with a state-of-the-art tactile sensor that is only sensitive on one side, as well as a state-of-the-art multi-directional tactile sensor, and find that OmniTact's combination of high-resolution and multi-directional sensing is crucial for reliably inserting the electrical connector and allows for higher accuracy in the state estimation task. Videos and supplementary material can be found at https://sites.google.com/berkeley.edu/omnitact
RoboNet: Large-Scale Multi-Robot Learning
Oct 24, 2019


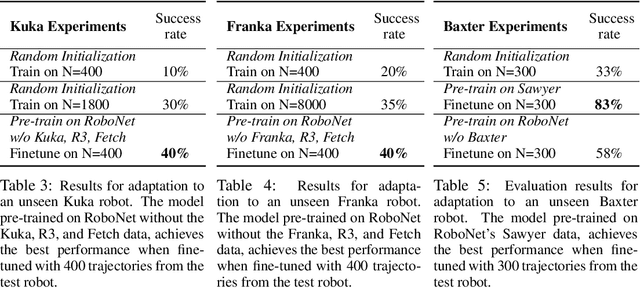
Robot learning has emerged as a promising tool for taming the complexity and diversity of the real world. Methods based on high-capacity models, such as deep networks, hold the promise of providing effective generalization to a wide range of open-world environments. However, these same methods typically require large amounts of diverse training data to generalize effectively. In contrast, most robotic learning experiments are small-scale, single-domain, and single-robot. This leads to a frequent tension in robotic learning: how can we learn generalizable robotic controllers without having to collect impractically large amounts of data for each separate experiment? In this paper, we propose RoboNet, an open database for sharing robotic experience, which provides an initial pool of 15 million video frames, from 7 different robot platforms, and study how it can be used to learn generalizable models for vision-based robotic manipulation. We combine the dataset with two different learning algorithms: visual foresight, which uses forward video prediction models, and supervised inverse models. Our experiments test the learned algorithms' ability to work across new objects, new tasks, new scenes, new camera viewpoints, new grippers, or even entirely new robots. In our final experiment, we find that by pre-training on RoboNet and fine-tuning on data from a held-out Franka or Kuka robot, we can exceed the performance of a robot-specific training approach that uses 4x-20x more data. For videos and data, see the project webpage: https://www.robonet.wiki/
Improvisation through Physical Understanding: Using Novel Objects as Tools with Visual Foresight
Apr 11, 2019
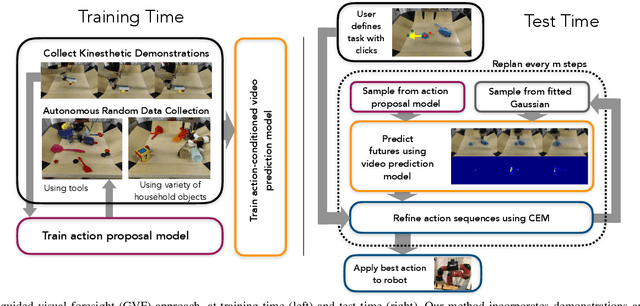


Machine learning techniques have enabled robots to learn narrow, yet complex tasks and also perform broad, yet simple skills with a wide variety of objects. However, learning a model that can both perform complex tasks and generalize to previously unseen objects and goals remains a significant challenge. We study this challenge in the context of "improvisational" tool use: a robot is presented with novel objects and a user-specified goal (e.g., sweep some clutter into the dustpan), and must figure out, using only raw image observations, how to accomplish the goal using the available objects as tools. We approach this problem by training a model with both a visual and physical understanding of multi-object interactions, and develop a sampling-based optimizer that can leverage these interactions to accomplish tasks. We do so by combining diverse demonstration data with self-supervised interaction data, aiming to leverage the interaction data to build generalizable models and the demonstration data to guide the model-based RL planner to solve complex tasks. Our experiments show that our approach can solve a variety of complex tool use tasks from raw pixel inputs, outperforming both imitation learning and self-supervised learning individually. Furthermore, we show that the robot can perceive and use novel objects as tools, including objects that are not conventional tools, while also choosing dynamically to use or not use tools depending on whether or not they are required.
Manipulation by Feel: Touch-Based Control with Deep Predictive Models
Mar 11, 2019

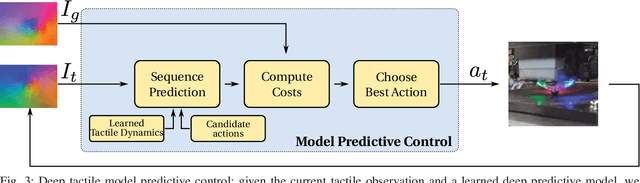
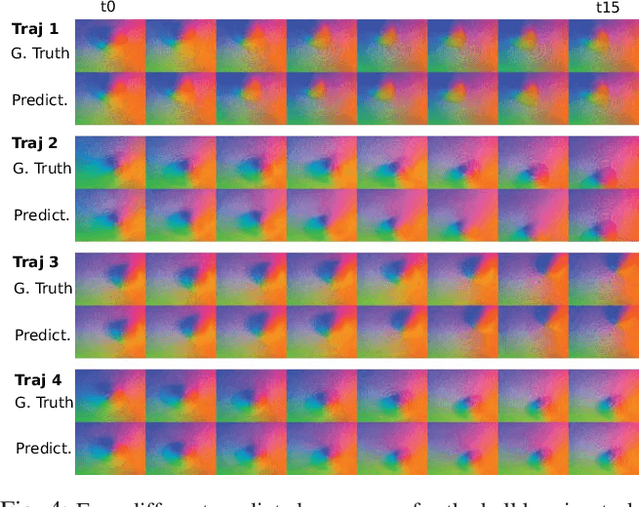
Touch sensing is widely acknowledged to be important for dexterous robotic manipulation, but exploiting tactile sensing for continuous, non-prehensile manipulation is challenging. General purpose control techniques that are able to effectively leverage tactile sensing as well as accurate physics models of contacts and forces remain largely elusive, and it is unclear how to even specify a desired behavior in terms of tactile percepts. In this paper, we take a step towards addressing these issues by combining high-resolution tactile sensing with data-driven modeling using deep neural network dynamics models. We propose deep tactile MPC, a framework for learning to perform tactile servoing from raw tactile sensor inputs, without manual supervision. We show that this method enables a robot equipped with a GelSight-style tactile sensor to manipulate a ball, analog stick, and 20-sided die, learning from unsupervised autonomous interaction and then using the learned tactile predictive model to reposition each object to user-specified configurations, indicated by a goal tactile reading. Videos, visualizations and the code are available here: https://sites.google.com/view/deeptactilempc
Visual Foresight: Model-Based Deep Reinforcement Learning for Vision-Based Robotic Control
Dec 03, 2018

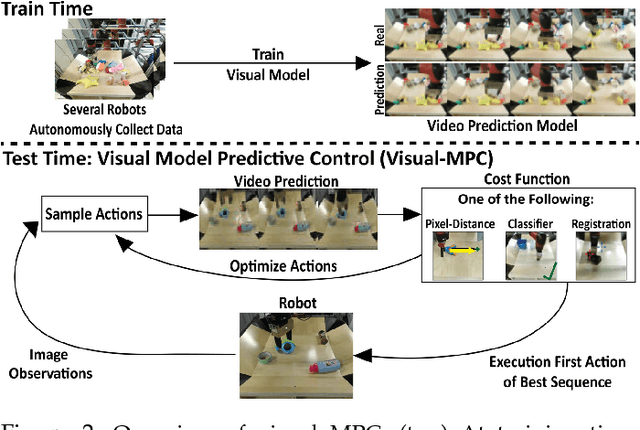

Deep reinforcement learning (RL) algorithms can learn complex robotic skills from raw sensory inputs, but have yet to achieve the kind of broad generalization and applicability demonstrated by deep learning methods in supervised domains. We present a deep RL method that is practical for real-world robotics tasks, such as robotic manipulation, and generalizes effectively to never-before-seen tasks and objects. In these settings, ground truth reward signals are typically unavailable, and we therefore propose a self-supervised model-based approach, where a predictive model learns to directly predict the future from raw sensory readings, such as camera images. At test time, we explore three distinct goal specification methods: designated pixels, where a user specifies desired object manipulation tasks by selecting particular pixels in an image and corresponding goal positions, goal images, where the desired goal state is specified with an image, and image classifiers, which define spaces of goal states. Our deep predictive models are trained using data collected autonomously and continuously by a robot interacting with hundreds of objects, without human supervision. We demonstrate that visual MPC can generalize to never-before-seen objects---both rigid and deformable---and solve a range of user-defined object manipulation tasks using the same model.