 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeRewarder: Learning Dense Reward from Passive Videos via Frame-wise Temporal Distance
Sep 30, 2025Designing dense rewards is crucial for reinforcement learning (RL), yet in robotics it often demands extensive manual effort and lacks scalability. One promising solution is to view task progress as a dense reward signal, as it quantifies the degree to which actions advance the system toward task completion over time. We present TimeRewarder, a simple yet effective reward learning method that derives progress estimation signals from passive videos, including robot demonstrations and human videos, by modeling temporal distances between frame pairs. We then demonstrate how TimeRewarder can supply step-wise proxy rewards to guide reinforcement learning. In our comprehensive experiments on ten challenging Meta-World tasks, we show that TimeRewarder dramatically improves RL for sparse-reward tasks, achieving nearly perfect success in 9/10 tasks with only 200,000 interactions per task with the environment. This approach outperformed previous methods and even the manually designed environment dense reward on both the final success rate and sample efficiency. Moreover, we show that TimeRewarder pretraining can exploit real-world human videos, highlighting its potential as a scalable approach path to rich reward signals from diverse video sources.
ZeroMimic: Distilling Robotic Manipulation Skills from Web Videos
Mar 31, 2025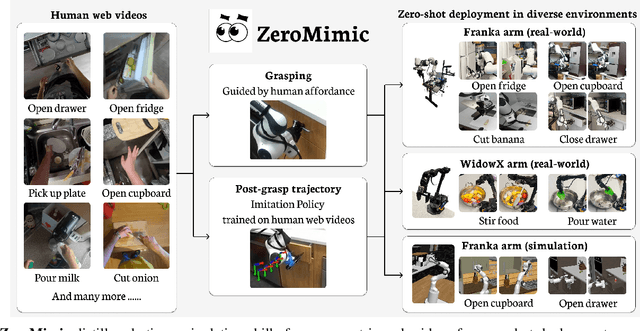



Many recent advances in robotic manipulation have come through imitation learning, yet these rely largely on mimicking a particularly hard-to-acquire form of demonstrations: those collected on the same robot in the same room with the same objects as the trained policy must handle at test time. In contrast, large pre-recorded human video datasets demonstrating manipulation skills in-the-wild already exist, which contain valuable information for robots. Is it possible to distill a repository of useful robotic skill policies out of such data without any additional requirements on robot-specific demonstrations or exploration? We present the first such system ZeroMimic, that generates immediately deployable image goal-conditioned skill policies for several common categories of manipulation tasks (opening, closing, pouring, pick&place, cutting, and stirring) each capable of acting upon diverse objects and across diverse unseen task setups. ZeroMimic is carefully designed to exploit recent advances in semantic and geometric visual understanding of human videos, together with modern grasp affordance detectors and imitation policy classes. After training ZeroMimic on the popular EpicKitchens dataset of ego-centric human videos, we evaluate its out-of-the-box performance in varied real-world and simulated kitchen settings with two different robot embodiments, demonstrating its impressive abilities to handle these varied tasks. To enable plug-and-play reuse of ZeroMimic policies on other task setups and robots, we release software and policy checkpoints of our skill policies.
REGENT: A Retrieval-Augmented Generalist Agent That Can Act In-Context in New Environments
Dec 06, 2024Building generalist agents that can rapidly adapt to new environments is a key challenge for deploying AI in the digital and real worlds. Is scaling current agent architectures the most effective way to build generalist agents? We propose a novel approach to pre-train relatively small policies on relatively small datasets and adapt them to unseen environments via in-context learning, without any finetuning. Our key idea is that retrieval offers a powerful bias for fast adaptation. Indeed, we demonstrate that even a simple retrieval-based 1-nearest neighbor agent offers a surprisingly strong baseline for today's state-of-the-art generalist agents. From this starting point, we construct a semi-parametric agent, REGENT, that trains a transformer-based policy on sequences of queries and retrieved neighbors. REGENT can generalize to unseen robotics and game-playing environments via retrieval augmentation and in-context learning, achieving this with up to 3x fewer parameters and up to an order-of-magnitude fewer pre-training datapoints, significantly outperforming today's state-of-the-art generalist agents. Website: https://kaustubhsridhar.github.io/regent-research
Vision Language Models are In-Context Value Learners
Nov 07, 2024
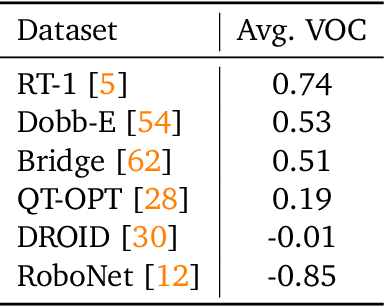
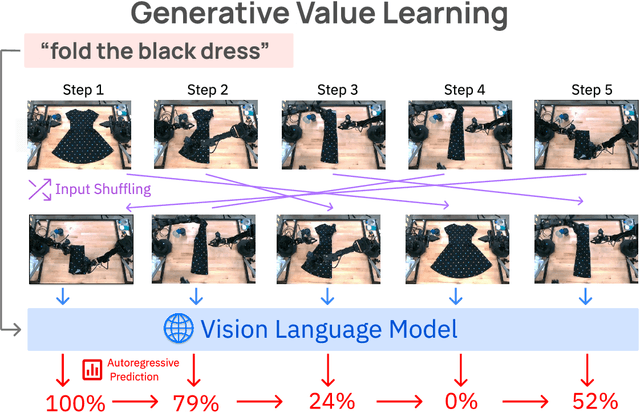
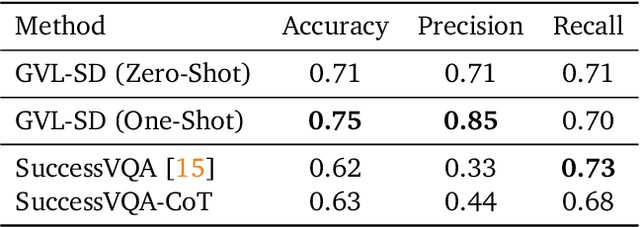
Predicting temporal progress from visual trajectories is important for intelligent robots that can learn, adapt, and improve. However, learning such progress estimator, or temporal value function, across different tasks and domains requires both a large amount of diverse data and methods which can scale and generalize. To address these challenges, we present Generative Value Learning (\GVL), a universal value function estimator that leverages the world knowledge embedded in vision-language models (VLMs) to predict task progress. Naively asking a VLM to predict values for a video sequence performs poorly due to the strong temporal correlation between successive frames. Instead, GVL poses value estimation as a temporal ordering problem over shuffled video frames; this seemingly more challenging task encourages VLMs to more fully exploit their underlying semantic and temporal grounding capabilities to differentiate frames based on their perceived task progress, consequently producing significantly better value predictions. Without any robot or task specific training, GVL can in-context zero-shot and few-shot predict effective values for more than 300 distinct real-world tasks across diverse robot platforms, including challenging bimanual manipulation tasks. Furthermore, we demonstrate that GVL permits flexible multi-modal in-context learning via examples from heterogeneous tasks and embodiments, such as human videos. The generality of GVL enables various downstream applications pertinent to visuomotor policy learning, including dataset filtering, success detection, and advantage-weighted regression -- all without any model training or finetuning.
Eurekaverse: Environment Curriculum Generation via Large Language Models
Nov 04, 2024
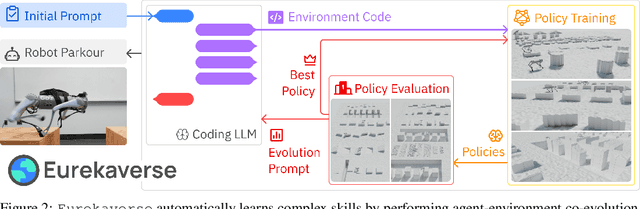

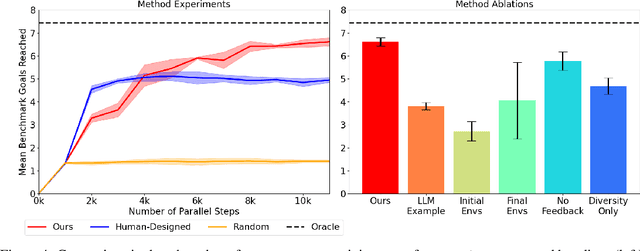
Recent work has demonstrated that a promising strategy for teaching robots a wide range of complex skills is by training them on a curriculum of progressively more challenging environments. However, developing an effective curriculum of environment distributions currently requires significant expertise, which must be repeated for every new domain. Our key insight is that environments are often naturally represented as code. Thus, we probe whether effective environment curriculum design can be achieved and automated via code generation by large language models (LLM). In this paper, we introduce Eurekaverse, an unsupervised environment design algorithm that uses LLMs to sample progressively more challenging, diverse, and learnable environments for skill training. We validate Eurekaverse's effectiveness in the domain of quadrupedal parkour learning, in which a quadruped robot must traverse through a variety of obstacle courses. The automatic curriculum designed by Eurekaverse enables gradual learning of complex parkour skills in simulation and can successfully transfer to the real-world, outperforming manual training courses designed by humans.
Task-Oriented Hierarchical Object Decomposition for Visuomotor Control
Nov 02, 2024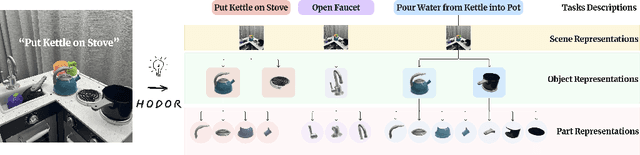
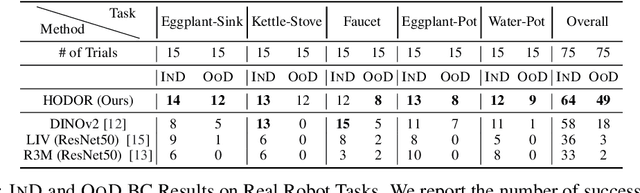
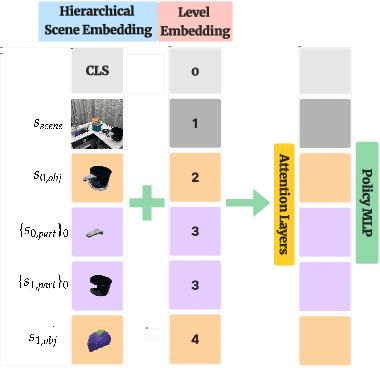
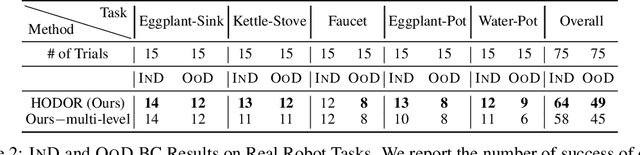
Good pre-trained visual representations could enable robots to learn visuomotor policy efficiently. Still, existing representations take a one-size-fits-all-tasks approach that comes with two important drawbacks: (1) Being completely task-agnostic, these representations cannot effectively ignore any task-irrelevant information in the scene, and (2) They often lack the representational capacity to handle unconstrained/complex real-world scenes. Instead, we propose to train a large combinatorial family of representations organized by scene entities: objects and object parts. This hierarchical object decomposition for task-oriented representations (HODOR) permits selectively assembling different representations specific to each task while scaling in representational capacity with the complexity of the scene and the task. In our experiments, we find that HODOR outperforms prior pre-trained representations, both scene vector representations and object-centric representations, for sample-efficient imitation learning across 5 simulated and 5 real-world manipulation tasks. We further find that the invariances captured in HODOR are inherited into downstream policies, which can robustly generalize to out-of-distribution test conditions, permitting zero-shot skill chaining. Appendix, code, and videos: https://sites.google.com/view/hodor-corl24.
Learning to Achieve Goals with Belief State Transformers
Oct 30, 2024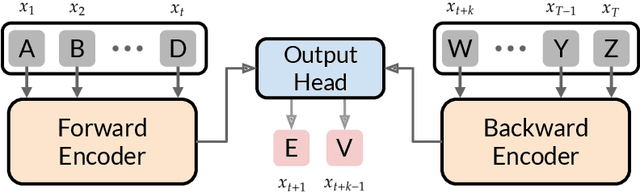
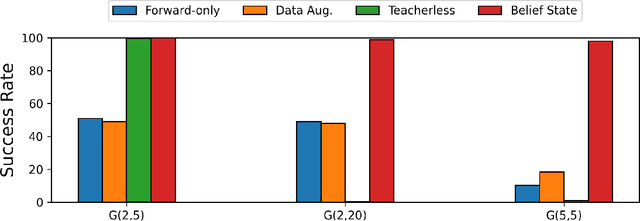
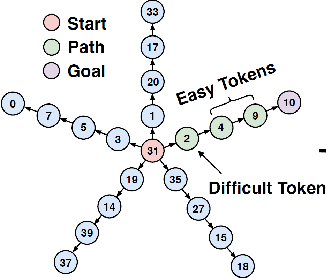
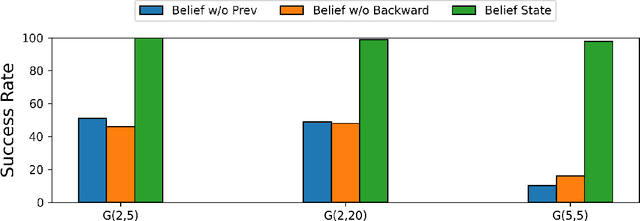
We introduce the "Belief State Transformer", a next-token predictor that takes both a prefix and suffix as inputs, with a novel objective of predicting both the next token for the prefix and the previous token for the suffix. The Belief State Transformer effectively learns to solve challenging problems that conventional forward-only transformers struggle with, in a domain-independent fashion. Key to this success is learning a compact belief state that captures all relevant information necessary for accurate predictions. Empirical ablations show that each component of the model is essential in difficult scenarios where standard Transformers fall short. For the task of story writing with known prefixes and suffixes, our approach outperforms the Fill-in-the-Middle method for reaching known goals and demonstrates improved performance even when the goals are unknown. Altogether, the Belief State Transformer enables more efficient goal-conditioned decoding, better test-time inference, and high-quality text representations on small scale problems.
Leveraging Symmetry to Accelerate Learning of Trajectory Tracking Controllers for Free-Flying Robotic Systems
Sep 17, 2024

Tracking controllers enable robotic systems to accurately follow planned reference trajectories. In particular, reinforcement learning (RL) has shown promise in the synthesis of controllers for systems with complex dynamics and modest online compute budgets. However, the poor sample efficiency of RL and the challenges of reward design make training slow and sometimes unstable, especially for high-dimensional systems. In this work, we leverage the inherent Lie group symmetries of robotic systems with a floating base to mitigate these challenges when learning tracking controllers. We model a general tracking problem as a Markov decision process (MDP) that captures the evolution of both the physical and reference states. Next, we prove that symmetry in the underlying dynamics and running costs leads to an MDP homomorphism, a mapping that allows a policy trained on a lower-dimensional "quotient" MDP to be lifted to an optimal tracking controller for the original system. We compare this symmetry-informed approach to an unstructured baseline, using Proximal Policy Optimization (PPO) to learn tracking controllers for three systems: the Particle (a forced point mass), the Astrobee (a fullyactuated space robot), and the Quadrotor (an underactuated system). Results show that a symmetry-aware approach both accelerates training and reduces tracking error after the same number of training steps.
DrEureka: Language Model Guided Sim-To-Real Transfer
Jun 04, 2024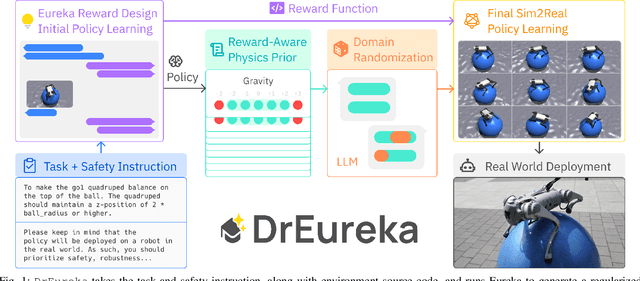
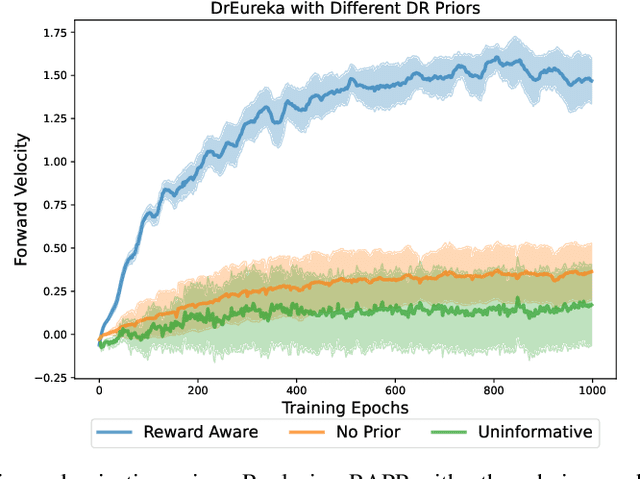

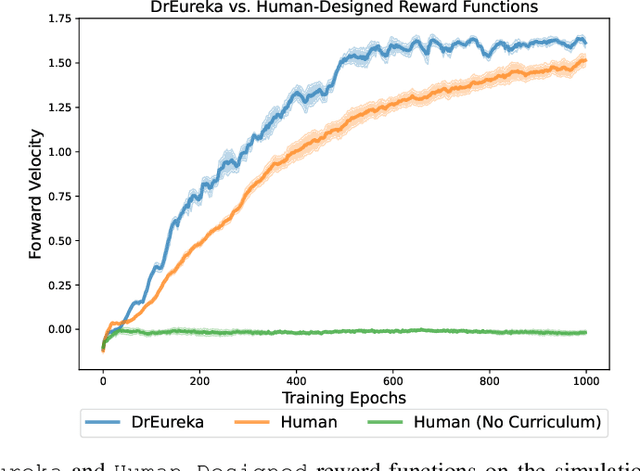
Transferring policies learned in simulation to the real world is a promising strategy for acquiring robot skills at scale. However, sim-to-real approaches typically rely on manual design and tuning of the task reward function as well as the simulation physics parameters, rendering the process slow and human-labor intensive. In this paper, we investigate using Large Language Models (LLMs) to automate and accelerate sim-to-real design. Our LLM-guided sim-to-real approach, DrEureka, requires only the physics simulation for the target task and automatically constructs suitable reward functions and domain randomization distributions to support real-world transfer. We first demonstrate that our approach can discover sim-to-real configurations that are competitive with existing human-designed ones on quadruped locomotion and dexterous manipulation tasks. Then, we showcase that our approach is capable of solving novel robot tasks, such as quadruped balancing and walking atop a yoga ball, without iterative manual design.
Recasting Generic Pretrained Vision Transformers As Object-Centric Scene Encoders For Manipulation Policies
May 24, 2024



Generic re-usable pre-trained image representation encoders have become a standard component of methods for many computer vision tasks. As visual representations for robots however, their utility has been limited, leading to a recent wave of efforts to pre-train robotics-specific image encoders that are better suited to robotic tasks than their generic counterparts. We propose Scene Objects From Transformers, abbreviated as SOFT, a wrapper around pre-trained vision transformer (PVT) models that bridges this gap without any further training. Rather than construct representations out of only the final layer activations, SOFT individuates and locates object-like entities from PVT attentions, and describes them with PVT activations, producing an object-centric embedding. Across standard choices of generic pre-trained vision transformers PVT, we demonstrate in each case that policies trained on SOFT(PVT) far outstrip standard PVT representations for manipulation tasks in simulated and real settings, approaching the state-of-the-art robotics-aware representations. Code, appendix and videos: https://sites.google.com/view/robot-soft/