 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Scalar Rewards to Potential Trends: Shaping Potential Landscapes for Model-Based Reinforcement Learning
Feb 03, 2026Model-based reinforcement learning (MBRL) achieves high sample efficiency by simulating future trajectories with learned dynamics and reward models. However, its effectiveness is severely compromised in sparse reward settings. The core limitation lies in the standard paradigm of regressing ground-truth scalar rewards: in sparse environments, this yields a flat, gradient-free landscape that fails to provide directional guidance for planning. To address this challenge, we propose Shaping Landscapes with Optimistic Potential Estimates (SLOPE), a novel framework that shifts reward modeling from predicting scalars to constructing informative potential landscapes. SLOPE employs optimistic distributional regression to estimate high-confidence upper bounds, which amplifies rare success signals and ensures sufficient exploration gradients. Evaluations on 30+ tasks across 5 benchmarks demonstrate that SLOPE consistently outperforms leading baselines in fully sparse, semi-sparse, and dense rewards.
When does predictive inverse dynamics outperform behavior cloning?
Jan 29, 2026Behavior cloning (BC) is a practical offline imitation learning method, but it often fails when expert demonstrations are limited. Recent works have introduced a class of architectures named predictive inverse dynamics models (PIDM) that combine a future state predictor with an inverse dynamics model (IDM). While PIDM often outperforms BC, the reasons behind its benefits remain unclear. In this paper, we provide a theoretical explanation: PIDM introduces a bias-variance tradeoff. While predicting the future state introduces bias, conditioning the IDM on the prediction can significantly reduce variance. We establish conditions on the state predictor bias for PIDM to achieve lower prediction error and higher sample efficiency than BC, with the gap widening when additional data sources are available. We validate the theoretical insights empirically in 2D navigation tasks, where BC requires up to five times (three times on average) more demonstrations than PIDM to reach comparable performance; and in a complex 3D environment in a modern video game with high-dimensional visual inputs and stochastic transitions, where BC requires over 66\% more samples than PIDM.
Next-Latent Prediction Transformers Learn Compact World Models
Nov 08, 2025Transformers replace recurrence with a memory that grows with sequence length and self-attention that enables ad-hoc look ups over past tokens. Consequently, they lack an inherent incentive to compress history into compact latent states with consistent transition rules. This often leads to learning solutions that generalize poorly. We introduce Next-Latent Prediction (NextLat), which extends standard next-token training with self-supervised predictions in the latent space. Specifically, NextLat trains a transformer to learn latent representations that are predictive of its next latent state given the next output token. Theoretically, we show that these latents provably converge to belief states, compressed information of the history necessary to predict the future. This simple auxiliary objective also injects a recurrent inductive bias into transformers, while leaving their architecture, parallel training, and inference unchanged. NextLat effectively encourages the transformer to form compact internal world models with its own belief states and transition dynamics -- a crucial property absent in standard next-token prediction transformers. Empirically, across benchmarks targeting core sequence modeling competencies -- world modeling, reasoning, planning, and language modeling -- NextLat demonstrates significant gains over standard next-token training in downstream accuracy, representation compression, and lookahead planning. NextLat stands as a simple and efficient paradigm for shaping transformer representations toward stronger generalization.
Attention Schema-based Attention Control (ASAC): A Cognitive-Inspired Approach for Attention Management in Transformers
Sep 19, 2025Attention mechanisms have become integral in AI, significantly enhancing model performance and scalability by drawing inspiration from human cognition. Concurrently, the Attention Schema Theory (AST) in cognitive science posits that individuals manage their attention by creating a model of the attention itself, effectively allocating cognitive resources. Inspired by AST, we introduce ASAC (Attention Schema-based Attention Control), which integrates the attention schema concept into artificial neural networks. Our initial experiments focused on embedding the ASAC module within transformer architectures. This module employs a Vector-Quantized Variational AutoEncoder (VQVAE) as both an attention abstractor and controller, facilitating precise attention management. By explicitly modeling attention allocation, our approach aims to enhance system efficiency. We demonstrate ASAC's effectiveness in both the vision and NLP domains, highlighting its ability to improve classification accuracy and expedite the learning process. Our experiments with vision transformers across various datasets illustrate that the attention controller not only boosts classification accuracy but also accelerates learning. Furthermore, we have demonstrated the model's robustness and generalization capabilities across noisy and out-of-distribution datasets. In addition, we have showcased improved performance in multi-task settings. Quick experiments reveal that the attention schema-based module enhances resilience to adversarial attacks, optimizes attention to improve learning efficiency, and facilitates effective transfer learning and learning from fewer examples. These promising results establish a connection between cognitive science and machine learning, shedding light on the efficient utilization of attention mechanisms in AI systems.
Inference-Time Alignment Control for Diffusion Models with Reinforcement Learning Guidance
Aug 28, 2025Denoising-based generative models, particularly diffusion and flow matching algorithms, have achieved remarkable success. However, aligning their output distributions with complex downstream objectives, such as human preferences, compositional accuracy, or data compressibility, remains challenging. While reinforcement learning (RL) fine-tuning methods, inspired by advances in RL from human feedback (RLHF) for large language models, have been adapted to these generative frameworks, current RL approaches are suboptimal for diffusion models and offer limited flexibility in controlling alignment strength after fine-tuning. In this work, we reinterpret RL fine-tuning for diffusion models through the lens of stochastic differential equations and implicit reward conditioning. We introduce Reinforcement Learning Guidance (RLG), an inference-time method that adapts Classifier-Free Guidance (CFG) by combining the outputs of the base and RL fine-tuned models via a geometric average. Our theoretical analysis shows that RLG's guidance scale is mathematically equivalent to adjusting the KL-regularization coefficient in standard RL objectives, enabling dynamic control over the alignment-quality trade-off without further training. Extensive experiments demonstrate that RLG consistently improves the performance of RL fine-tuned models across various architectures, RL algorithms, and downstream tasks, including human preferences, compositional control, compressibility, and text rendering. Furthermore, RLG supports both interpolation and extrapolation, thereby offering unprecedented flexibility in controlling generative alignment. Our approach provides a practical and theoretically sound solution for enhancing and controlling diffusion model alignment at inference. The source code for RLG is publicly available at the Github: https://github.com/jinluo12345/Reinforcement-learning-guidance.
Learning to Achieve Goals with Belief State Transformers
Oct 30, 2024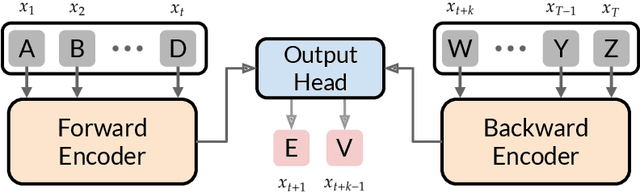
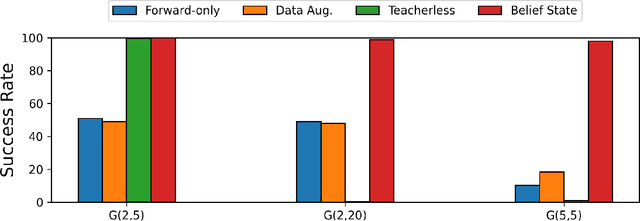
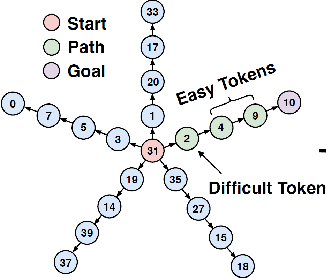
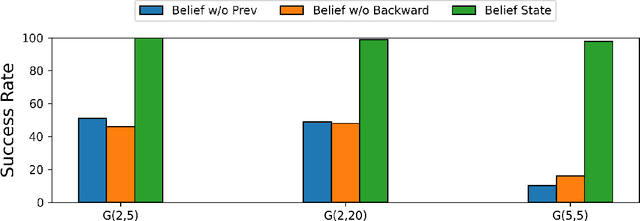
We introduce the "Belief State Transformer", a next-token predictor that takes both a prefix and suffix as inputs, with a novel objective of predicting both the next token for the prefix and the previous token for the suffix. The Belief State Transformer effectively learns to solve challenging problems that conventional forward-only transformers struggle with, in a domain-independent fashion. Key to this success is learning a compact belief state that captures all relevant information necessary for accurate predictions. Empirical ablations show that each component of the model is essential in difficult scenarios where standard Transformers fall short. For the task of story writing with known prefixes and suffixes, our approach outperforms the Fill-in-the-Middle method for reaching known goals and demonstrates improved performance even when the goals are unknown. Altogether, the Belief State Transformer enables more efficient goal-conditioned decoding, better test-time inference, and high-quality text representations on small scale problems.
Generalizing Multi-Step Inverse Models for Representation Learning to Finite-Memory POMDPs
Apr 22, 2024Discovering an informative, or agent-centric, state representation that encodes only the relevant information while discarding the irrelevant is a key challenge towards scaling reinforcement learning algorithms and efficiently applying them to downstream tasks. Prior works studied this problem in high-dimensional Markovian environments, when the current observation may be a complex object but is sufficient to decode the informative state. In this work, we consider the problem of discovering the agent-centric state in the more challenging high-dimensional non-Markovian setting, when the state can be decoded from a sequence of past observations. We establish that generalized inverse models can be adapted for learning agent-centric state representation for this task. Our results include asymptotic theory in the deterministic dynamics setting as well as counter-examples for alternative intuitive algorithms. We complement these findings with a thorough empirical study on the agent-centric state discovery abilities of the different alternatives we put forward. Particularly notable is our analysis of past actions, where we show that these can be a double-edged sword: making the algorithms more successful when used correctly and causing dramatic failure when used incorrectly.
Towards Principled Representation Learning from Videos for Reinforcement Learning
Mar 20, 2024



We study pre-training representations for decision-making using video data, which is abundantly available for tasks such as game agents and software testing. Even though significant empirical advances have been made on this problem, a theoretical understanding remains absent. We initiate the theoretical investigation into principled approaches for representation learning and focus on learning the latent state representations of the underlying MDP using video data. We study two types of settings: one where there is iid noise in the observation, and a more challenging setting where there is also the presence of exogenous noise, which is non-iid noise that is temporally correlated, such as the motion of people or cars in the background. We study three commonly used approaches: autoencoding, temporal contrastive learning, and forward modeling. We prove upper bounds for temporal contrastive learning and forward modeling in the presence of only iid noise. We show that these approaches can learn the latent state and use it to do efficient downstream RL with polynomial sample complexity. When exogenous noise is also present, we establish a lower bound result showing that the sample complexity of learning from video data can be exponentially worse than learning from action-labeled trajectory data. This partially explains why reinforcement learning with video pre-training is hard. We evaluate these representational learning methods in two visual domains, yielding results that are consistent with our theoretical findings.
Can AI Be as Creative as Humans?
Jan 12, 2024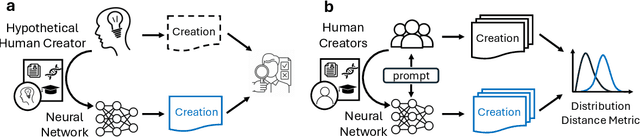
Creativity serves as a cornerstone for societal progress and innovation. With the rise of advanced generative AI models capable of tasks once reserved for human creativity, the study of AI's creative potential becomes imperative for its responsible development and application. In this paper, we provide a theoretical answer to the question of whether AI can be creative. We prove in theory that AI can be as creative as humans under the condition that AI can fit the existing data generated by human creators. Therefore, the debate on AI's creativity is reduced into the question of its ability of fitting a massive amount of data. To arrive at this conclusion, this paper first addresses the complexities in defining creativity by introducing a new concept called Relative Creativity. Instead of trying to define creativity universally, we shift the focus to whether AI can match the creative abilities of a hypothetical human. This perspective draws inspiration from the Turing Test, expanding upon it to address the challenges and subjectivities inherent in assessing creativity. This methodological shift leads to a statistically quantifiable assessment of AI's creativity, which we term Statistical Creativity. This concept allows for comparisons of AI's creative abilities with those of specific human groups, and facilitates the theoretical findings of AI's creative potential. Building on this foundation, we discuss the application of statistical creativity in prompt-conditioned autoregressive models, providing a practical means for evaluating creative abilities of contemporary AI models, such as Large Language Models (LLMs). In addition to defining and analyzing creativity, we introduce an actionable training guideline, effectively bridging the gap between theoretical quantification of creativity and practical model training.
PcLast: Discovering Plannable Continuous Latent States
Nov 06, 2023



Goal-conditioned planning benefits from learned low-dimensional representations of rich, high-dimensional observations. While compact latent representations, typically learned from variational autoencoders or inverse dynamics, enable goal-conditioned planning they ignore state affordances, thus hampering their sample-efficient planning capabilities. In this paper, we learn a representation that associates reachable states together for effective onward planning. We first learn a latent representation with multi-step inverse dynamics (to remove distracting information); and then transform this representation to associate reachable states together in $\ell_2$ space. Our proposals are rigorously tested in various simulation testbeds. Numerical results in reward-based and reward-free settings show significant improvements in sampling efficiency, and yields layered state abstractions that enable computationally efficient hierarchical planning.