 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext-Latent Prediction Transformers Learn Compact World Models
Nov 08, 2025Transformers replace recurrence with a memory that grows with sequence length and self-attention that enables ad-hoc look ups over past tokens. Consequently, they lack an inherent incentive to compress history into compact latent states with consistent transition rules. This often leads to learning solutions that generalize poorly. We introduce Next-Latent Prediction (NextLat), which extends standard next-token training with self-supervised predictions in the latent space. Specifically, NextLat trains a transformer to learn latent representations that are predictive of its next latent state given the next output token. Theoretically, we show that these latents provably converge to belief states, compressed information of the history necessary to predict the future. This simple auxiliary objective also injects a recurrent inductive bias into transformers, while leaving their architecture, parallel training, and inference unchanged. NextLat effectively encourages the transformer to form compact internal world models with its own belief states and transition dynamics -- a crucial property absent in standard next-token prediction transformers. Empirically, across benchmarks targeting core sequence modeling competencies -- world modeling, reasoning, planning, and language modeling -- NextLat demonstrates significant gains over standard next-token training in downstream accuracy, representation compression, and lookahead planning. NextLat stands as a simple and efficient paradigm for shaping transformer representations toward stronger generalization.
Learning to Achieve Goals with Belief State Transformers
Oct 30, 2024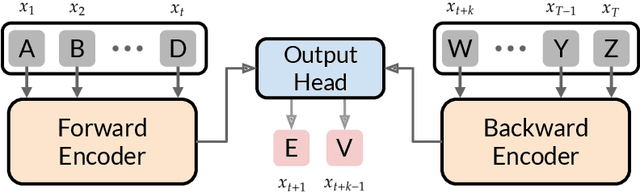
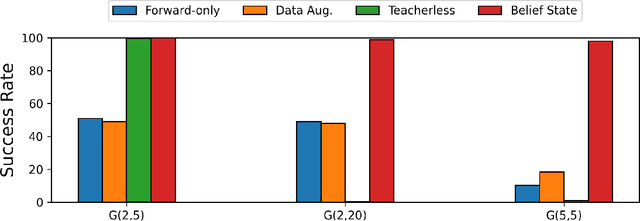
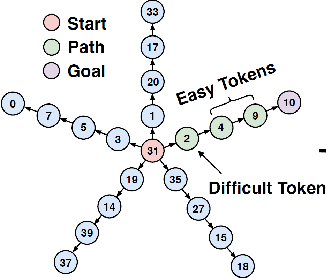
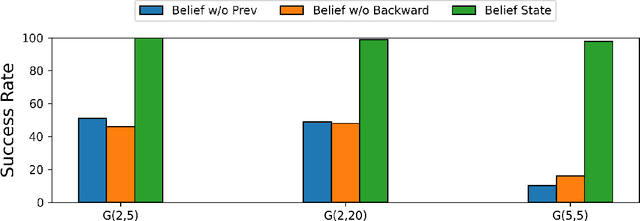
We introduce the "Belief State Transformer", a next-token predictor that takes both a prefix and suffix as inputs, with a novel objective of predicting both the next token for the prefix and the previous token for the suffix. The Belief State Transformer effectively learns to solve challenging problems that conventional forward-only transformers struggle with, in a domain-independent fashion. Key to this success is learning a compact belief state that captures all relevant information necessary for accurate predictions. Empirical ablations show that each component of the model is essential in difficult scenarios where standard Transformers fall short. For the task of story writing with known prefixes and suffixes, our approach outperforms the Fill-in-the-Middle method for reaching known goals and demonstrates improved performance even when the goals are unknown. Altogether, the Belief State Transformer enables more efficient goal-conditioned decoding, better test-time inference, and high-quality text representations on small scale problems.
World Models Increase Autonomy in Reinforcement Learning
Aug 20, 2024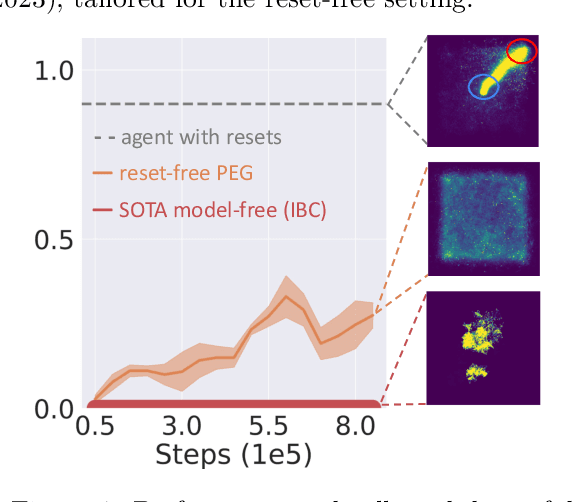

Reinforcement learning (RL) is an appealing paradigm for training intelligent agents, enabling policy acquisition from the agent's own autonomously acquired experience. However, the training process of RL is far from automatic, requiring extensive human effort to reset the agent and environments. To tackle the challenging reset-free setting, we first demonstrate the superiority of model-based (MB) RL methods in such setting, showing that a straightforward adaptation of MBRL can outperform all the prior state-of-the-art methods while requiring less supervision. We then identify limitations inherent to this direct extension and propose a solution called model-based reset-free (MoReFree) agent, which further enhances the performance. MoReFree adapts two key mechanisms, exploration and policy learning, to handle reset-free tasks by prioritizing task-relevant states. It exhibits superior data-efficiency across various reset-free tasks without access to environmental reward or demonstrations while significantly outperforming privileged baselines that require supervision. Our findings suggest model-based methods hold significant promise for reducing human effort in RL. Website: https://sites.google.com/view/morefree
Privileged Sensing Scaffolds Reinforcement Learning
May 23, 2024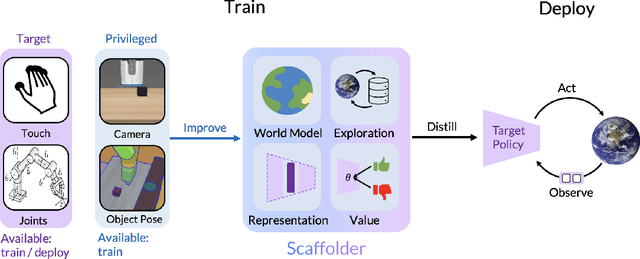
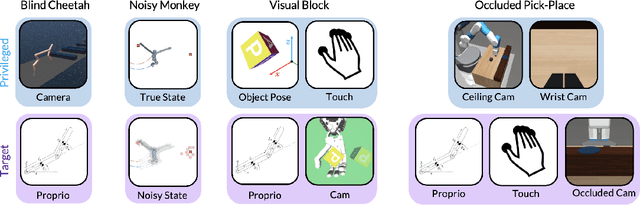

We need to look at our shoelaces as we first learn to tie them but having mastered this skill, can do it from touch alone. We call this phenomenon "sensory scaffolding": observation streams that are not needed by a master might yet aid a novice learner. We consider such sensory scaffolding setups for training artificial agents. For example, a robot arm may need to be deployed with just a low-cost, robust, general-purpose camera; yet its performance may improve by having privileged training-time-only access to informative albeit expensive and unwieldy motion capture rigs or fragile tactile sensors. For these settings, we propose "Scaffolder", a reinforcement learning approach which effectively exploits privileged sensing in critics, world models, reward estimators, and other such auxiliary components that are only used at training time, to improve the target policy. For evaluating sensory scaffolding agents, we design a new "S3" suite of ten diverse simulated robotic tasks that explore a wide range of practical sensor setups. Agents must use privileged camera sensing to train blind hurdlers, privileged active visual perception to help robot arms overcome visual occlusions, privileged touch sensors to train robot hands, and more. Scaffolder easily outperforms relevant prior baselines and frequently performs comparably even to policies that have test-time access to the privileged sensors. Website: https://penn-pal-lab.github.io/scaffolder/
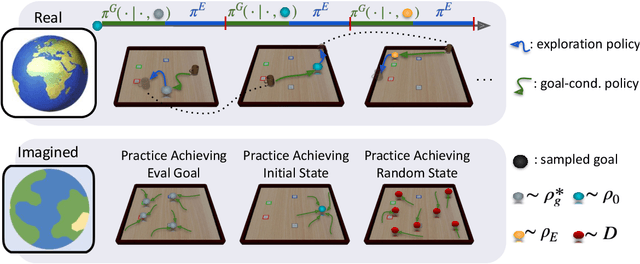
Planning Goals for Exploration
Mar 23, 2023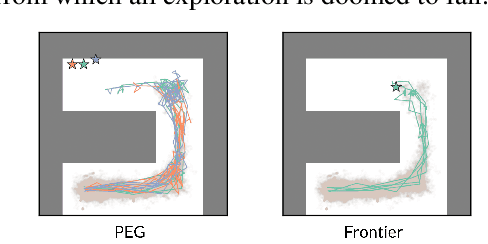
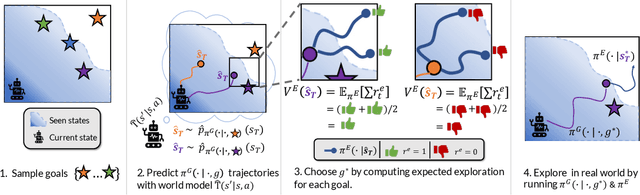
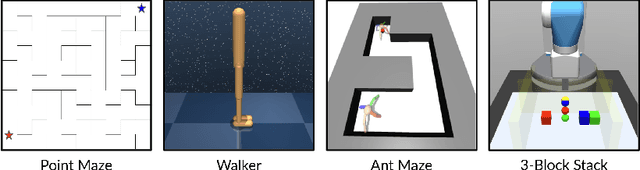
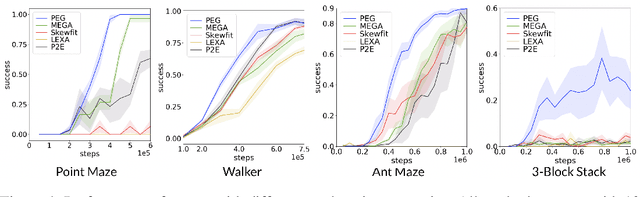
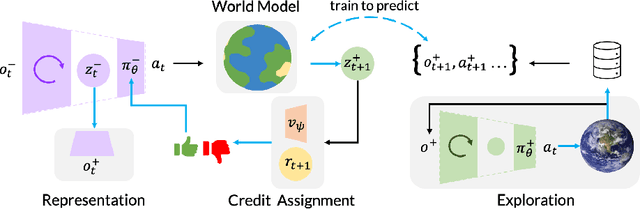
Dropped into an unknown environment, what should an agent do to quickly learn about the environment and how to accomplish diverse tasks within it? We address this question within the goal-conditioned reinforcement learning paradigm, by identifying how the agent should set its goals at training time to maximize exploration. We propose "Planning Exploratory Goals" (PEG), a method that sets goals for each training episode to directly optimize an intrinsic exploration reward. PEG first chooses goal commands such that the agent's goal-conditioned policy, at its current level of training, will end up in states with high exploration potential. It then launches an exploration policy starting at those promising states. To enable this direct optimization, PEG learns world models and adapts sampling-based planning algorithms to "plan goal commands". In challenging simulated robotics environments including a multi-legged ant robot in a maze, and a robot arm on a cluttered tabletop, PEG exploration enables more efficient and effective training of goal-conditioned policies relative to baselines and ablations. Our ant successfully navigates a long maze, and the robot arm successfully builds a stack of three blocks upon command. Website: https://penn-pal-lab.github.io/peg/
Training Robots to Evaluate Robots: Example-Based Interactive Reward Functions for Policy Learning
Dec 17, 2022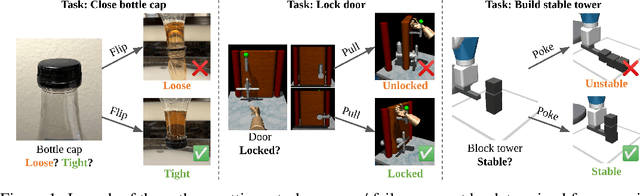

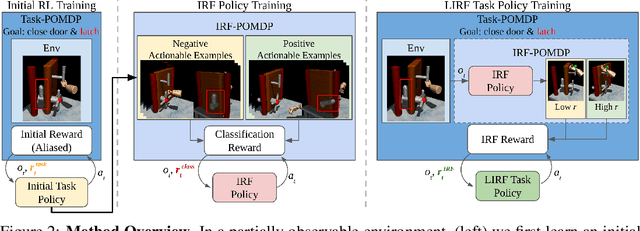

Physical interactions can often help reveal information that is not readily apparent. For example, we may tug at a table leg to evaluate whether it is built well, or turn a water bottle upside down to check that it is watertight. We propose to train robots to acquire such interactive behaviors automatically, for the purpose of evaluating the result of an attempted robotic skill execution. These evaluations in turn serve as "interactive reward functions" (IRFs) for training reinforcement learning policies to perform the target skill, such as screwing the table leg tightly. In addition, even after task policies are fully trained, IRFs can serve as verification mechanisms that improve online task execution. For any given task, our IRFs can be conveniently trained using only examples of successful outcomes, and no further specification is needed to train the task policy thereafter. In our evaluations on door locking and weighted block stacking in simulation, and screw tightening on a real robot, IRFs enable large performance improvements, even outperforming baselines with access to demonstrations or carefully engineered rewards. Project website: https://sites.google.com/view/lirf-corl-2022/
Know Thyself: Transferable Visuomotor Control Through Robot-Awareness
Jul 28, 2021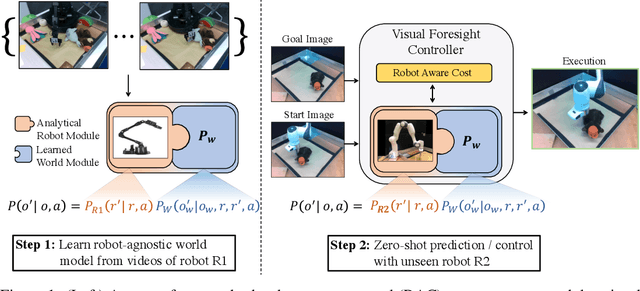

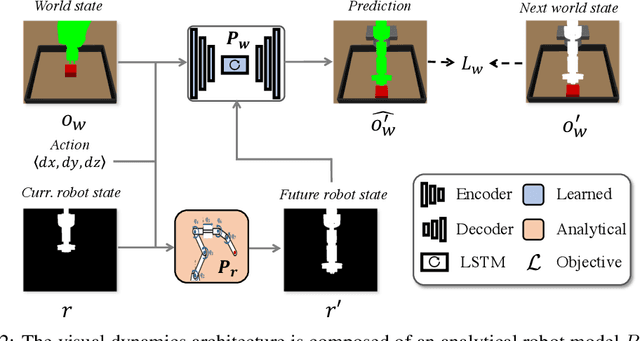
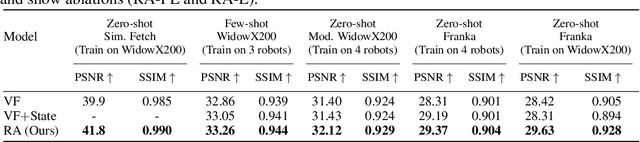
Training visuomotor robot controllers from scratch on a new robot typically requires generating large amounts of robot-specific data. Could we leverage data previously collected on another robot to reduce or even completely remove this need for robot-specific data? We propose a "robot-aware" solution paradigm that exploits readily available robot "self-knowledge" such as proprioception, kinematics, and camera calibration to achieve this. First, we learn modular dynamics models that pair a transferable, robot-agnostic world dynamics module with a robot-specific, analytical robot dynamics module. Next, we set up visual planning costs that draw a distinction between the robot self and the world. Our experiments on tabletop manipulation tasks in simulation and on real robots demonstrate that these plug-in improvements dramatically boost the transferability of visuomotor controllers, even permitting zero-shot transfer onto new robots for the very first time. Project website: https://hueds.github.io/rac/
To Follow or not to Follow: Selective Imitation Learning from Observations
Dec 16, 2019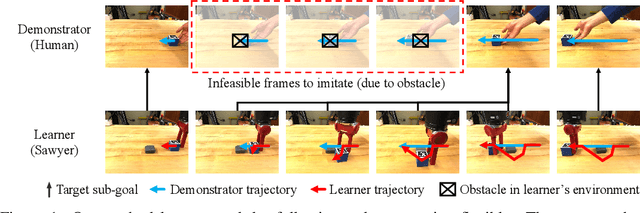

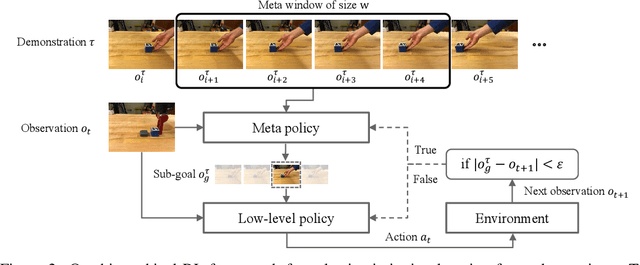
Learning from demonstrations is a useful way to transfer a skill from one agent to another. While most imitation learning methods aim to mimic an expert skill by following the demonstration step-by-step, imitating every step in the demonstration often becomes infeasible when the learner and its environment are different from the demonstration. In this paper, we propose a method that can imitate a demonstration composed solely of observations, which may not be reproducible with the current agent. Our method, dubbed selective imitation learning from observations (SILO), selects reachable states in the demonstration and learns how to reach the selected states. Our experiments on both simulated and real robot environments show that our method reliably performs a new task by following a demonstration. Videos and code are available at https://clvrai.com/silo .
IKEA Furniture Assembly Environment for Long-Horizon Complex Manipulation Tasks
Nov 17, 2019
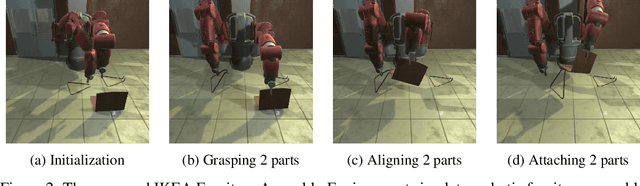

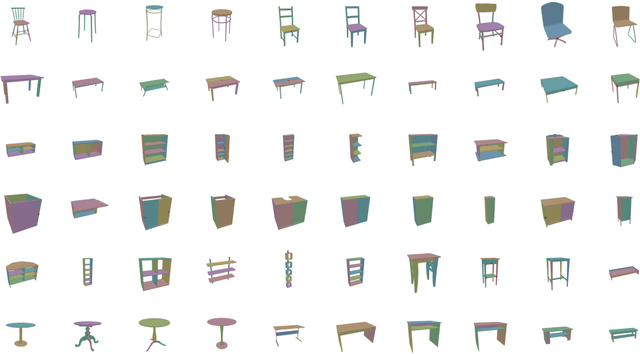
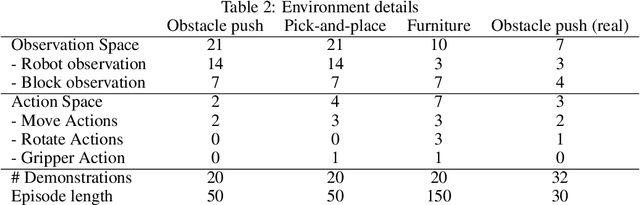
The IKEA Furniture Assembly Environment is one of the first benchmarks for testing and accelerating the automation of complex manipulation tasks. The environment is designed to advance reinforcement learning from simple toy tasks to complex tasks requiring both long-term planning and sophisticated low-level control. Our environment supports over 80 different furniture models, Sawyer and Baxter robot simulation, and domain randomization. The IKEA Furniture Assembly Environment is a testbed for methods aiming to solve complex manipulation tasks. The environment is publicly available at https://clvrai.com/furniture