 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthVerse: A Large-Scale Diverse Synthetic Dataset for Point Tracking
Feb 04, 2026Point tracking aims to follow visual points through complex motion, occlusion, and viewpoint changes, and has advanced rapidly with modern foundation models. Yet progress toward general point tracking remains constrained by limited high-quality data, as existing datasets often provide insufficient diversity and imperfect trajectory annotations. To this end, we introduce SynthVerse, a large-scale, diverse synthetic dataset specifically designed for point tracking. SynthVerse includes several new domains and object types missing from existing synthetic datasets, such as animated-film-style content, embodied manipulation, scene navigation, and articulated objects. SynthVerse substantially expands dataset diversity by covering a broader range of object categories and providing high-quality dynamic motions and interactions, enabling more robust training and evaluation for general point tracking. In addition, we establish a highly diverse point tracking benchmark to systematically evaluate state-of-the-art methods under broader domain shifts. Extensive experiments and analyses demonstrate that training with SynthVerse yields consistent improvements in generalization and reveal limitations of existing trackers under diverse settings.
Video-OPD: Efficient Post-Training of Multimodal Large Language Models for Temporal Video Grounding via On-Policy Distillation
Feb 03, 2026Reinforcement learning has emerged as a principled post-training paradigm for Temporal Video Grounding (TVG) due to its on-policy optimization, yet existing GRPO-based methods remain fundamentally constrained by sparse reward signals and substantial computational overhead. We propose Video-OPD, an efficient post-training framework for TVG inspired by recent advances in on-policy distillation. Video-OPD optimizes trajectories sampled directly from the current policy, thereby preserving alignment between training and inference distributions, while a frontier teacher supplies dense, token-level supervision via a reverse KL divergence objective. This formulation preserves the on-policy property critical for mitigating distributional shift, while converting sparse, episode-level feedback into fine-grained, step-wise learning signals. Building on Video-OPD, we introduce Teacher-Validated Disagreement Focusing (TVDF), a lightweight training curriculum that iteratively prioritizes trajectories that are both teacher-reliable and maximally informative for the student, thereby improving training efficiency. Empirical results demonstrate that Video-OPD consistently outperforms GRPO while achieving substantially faster convergence and lower computational cost, establishing on-policy distillation as an effective alternative to conventional reinforcement learning for TVG.
Federated Balanced Learning
Jan 20, 2026Federated learning is a paradigm of joint learning in which clients collaborate by sharing model parameters instead of data. However, in the non-iid setting, the global model experiences client drift, which can seriously affect the final performance of the model. Previous methods tend to correct the global model that has already deviated based on the loss function or gradient, overlooking the impact of the client samples. In this paper, we rethink the role of the client side and propose Federated Balanced Learning, i.e., FBL, to prevent this issue from the beginning through sample balance on the client side. Technically, FBL allows unbalanced data on the client side to achieve sample balance through knowledge filling and knowledge sampling using edge-side generation models, under the limitation of a fixed number of data samples on clients. Furthermore, we design a Knowledge Alignment Strategy to bridge the gap between synthetic and real data, and a Knowledge Drop Strategy to regularize our method. Meanwhile, we scale our method to real and complex scenarios, allowing different clients to adopt various methods, and extend our framework to further improve performance. Numerous experiments show that our method outperforms state-of-the-art baselines. The code is released upon acceptance.
Vision Also You Need: Navigating Out-of-Distribution Detection with Multimodal Large Language Model
Jan 20, 2026Out-of-Distribution (OOD) detection is a critical task that has garnered significant attention. The emergence of CLIP has spurred extensive research into zero-shot OOD detection, often employing a training-free approach. Current methods leverage expert knowledge from large language models (LLMs) to identify potential outliers. However, these approaches tend to over-rely on knowledge in the text space, neglecting the inherent challenges involved in detecting out-of-distribution samples in the image space. In this paper, we propose a novel pipeline, MM-OOD, which leverages the multimodal reasoning capabilities of MLLMs and their ability to conduct multi-round conversations for enhanced outlier detection. Our method is designed to improve performance in both near OOD and far OOD tasks. Specifically, (1) for near OOD tasks, we directly feed ID images and corresponding text prompts into MLLMs to identify potential outliers; and (2) for far OOD tasks, we introduce the sketch-generate-elaborate framework: first, we sketch outlier exposure using text prompts, then generate corresponding visual OOD samples, and finally elaborate by using multimodal prompts. Experiments demonstrate that our method achieves significant improvements on widely used multimodal datasets such as Food-101, while also validating its scalability on ImageNet-1K.
Federated Joint Learning for Domain and Class Generalization
Jan 18, 2026Efficient fine-tuning of visual-language models like CLIP has become crucial due to their large-scale parameter size and extensive pretraining requirements. Existing methods typically address either the issue of unseen classes or unseen domains in isolation, without considering a joint framework for both. In this paper, we propose \textbf{Fed}erated Joint Learning for \textbf{D}omain and \textbf{C}lass \textbf{G}eneralization, termed \textbf{FedDCG}, a novel approach that addresses both class and domain generalization in federated learning settings. Our method introduces a domain grouping strategy where class-generalized networks are trained within each group to prevent decision boundary confusion. During inference, we aggregate class-generalized results based on domain similarity, effectively integrating knowledge from both class and domain generalization. Specifically, a learnable network is employed to enhance class generalization capabilities, and a decoupling mechanism separates general and domain-specific knowledge, improving generalization to unseen domains. Extensive experiments across various datasets show that \textbf{FedDCG} outperforms state-of-the-art baselines in terms of accuracy and robustness.
REST: Diffusion-based Real-time End-to-end Streaming Talking Head Generation via ID-Context Caching and Asynchronous Streaming Distillation
Dec 12, 2025Diffusion models have significantly advanced the field of talking head generation. However, the slow inference speeds and non-autoregressive paradigms severely constrain the application of diffusion-based THG models. In this study, we propose REST, the first diffusion-based, real-time, end-to-end streaming audio-driven talking head generation framework. To support real-time end-to-end generation, a compact video latent space is first learned through high spatiotemporal VAE compression. Additionally, to enable autoregressive streaming within the compact video latent space, we introduce an ID-Context Cache mechanism, which integrates ID-Sink and Context-Cache principles to key-value caching for maintaining temporal consistency and identity coherence during long-time streaming generation. Furthermore, an Asynchronous Streaming Distillation (ASD) training strategy is proposed to mitigate error accumulation in autoregressive generation and enhance temporal consistency, which leverages a non-streaming teacher with an asynchronous noise schedule to supervise the training of the streaming student model. REST bridges the gap between autoregressive and diffusion-based approaches, demonstrating substantial value for applications requiring real-time talking head generation. Experimental results demonstrate that REST outperforms state-of-the-art methods in both generation speed and overall performance.
SEDM: Scalable Self-Evolving Distributed Memory for Agents
Sep 11, 2025Long-term multi-agent systems inevitably generate vast amounts of trajectories and historical interactions, which makes efficient memory management essential for both performance and scalability. Existing methods typically depend on vector retrieval and hierarchical storage, yet they are prone to noise accumulation, uncontrolled memory expansion, and limited generalization across domains. To address these challenges, we present SEDM, Self-Evolving Distributed Memory, a verifiable and adaptive framework that transforms memory from a passive repository into an active, self-optimizing component. SEDM integrates verifiable write admission based on reproducible replay, a self-scheduling memory controller that dynamically ranks and consolidates entries according to empirical utility, and cross-domain knowledge diffusion that abstracts reusable insights to support transfer across heterogeneous tasks. Evaluations on benchmark datasets demonstrate that SEDM improves reasoning accuracy while reducing token overhead compared with strong memory baselines, and further enables knowledge distilled from fact verification to enhance multi-hop reasoning. The results highlight SEDM as a scalable and sustainable memory mechanism for open-ended multi-agent collaboration. The code will be released in the later stage of this project.
Towards Affordance-Aware Robotic Dexterous Grasping with Human-like Priors
Aug 12, 2025A dexterous hand capable of generalizable grasping objects is fundamental for the development of general-purpose embodied AI. However, previous methods focus narrowly on low-level grasp stability metrics, neglecting affordance-aware positioning and human-like poses which are crucial for downstream manipulation. To address these limitations, we propose AffordDex, a novel framework with two-stage training that learns a universal grasping policy with an inherent understanding of both motion priors and object affordances. In the first stage, a trajectory imitator is pre-trained on a large corpus of human hand motions to instill a strong prior for natural movement. In the second stage, a residual module is trained to adapt these general human-like motions to specific object instances. This refinement is critically guided by two components: our Negative Affordance-aware Segmentation (NAA) module, which identifies functionally inappropriate contact regions, and a privileged teacher-student distillation process that ensures the final vision-based policy is highly successful. Extensive experiments demonstrate that AffordDex not only achieves universal dexterous grasping but also remains remarkably human-like in posture and functionally appropriate in contact location. As a result, AffordDex significantly outperforms state-of-the-art baselines across seen objects, unseen instances, and even entirely novel categories.
Make Your MoVe: Make Your 3D Contents by Adapting Multi-View Diffusion Models to External Editing
Aug 11, 2025As 3D generation techniques continue to flourish, the demand for generating personalized content is rapidly rising. Users increasingly seek to apply various editing methods to polish generated 3D content, aiming to enhance its color, style, and lighting without compromising the underlying geometry. However, most existing editing tools focus on the 2D domain, and directly feeding their results into 3D generation methods (like multi-view diffusion models) will introduce information loss, degrading the quality of the final 3D assets. In this paper, we propose a tuning-free, plug-and-play scheme that aligns edited assets with their original geometry in a single inference run. Central to our approach is a geometry preservation module that guides the edited multi-view generation with original input normal latents. Besides, an injection switcher is proposed to deliberately control the supervision extent of the original normals, ensuring the alignment between the edited color and normal views. Extensive experiments show that our method consistently improves both the multi-view consistency and mesh quality of edited 3D assets, across multiple combinations of multi-view diffusion models and editing methods.
Decoder-Hybrid-Decoder Architecture for Efficient Reasoning with Long Generation
Jul 09, 2025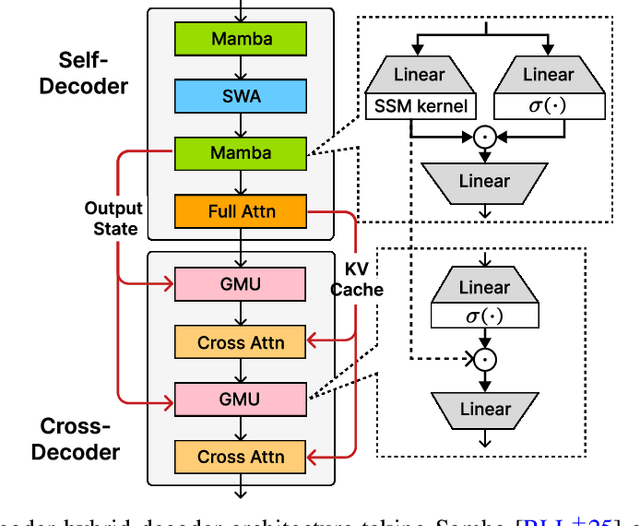
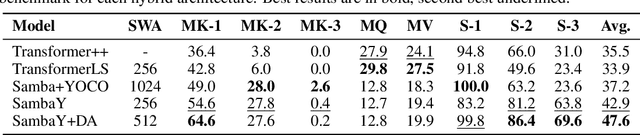
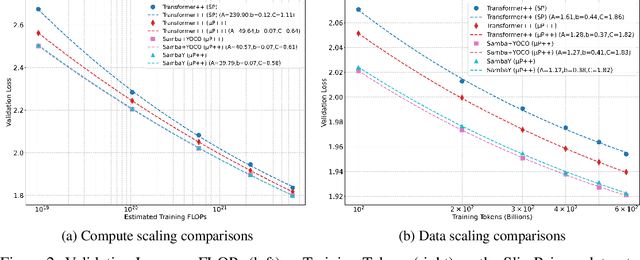
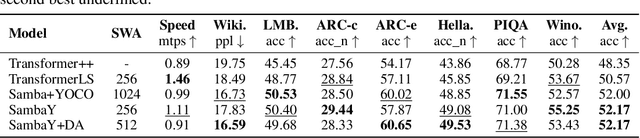
Recent advances in language modeling have demonstrated the effectiveness of State Space Models (SSMs) for efficient sequence modeling. While hybrid architectures such as Samba and the decoder-decoder architecture, YOCO, have shown promising performance gains over Transformers, prior works have not investigated the efficiency potential of representation sharing between SSM layers. In this paper, we introduce the Gated Memory Unit (GMU), a simple yet effective mechanism for efficient memory sharing across layers. We apply it to create SambaY, a decoder-hybrid-decoder architecture that incorporates GMUs in the cross-decoder to share memory readout states from a Samba-based self-decoder. SambaY significantly enhances decoding efficiency, preserves linear pre-filling time complexity, and boosts long-context performance, all while eliminating the need for explicit positional encoding. Through extensive scaling experiments, we demonstrate that our model exhibits a significantly lower irreducible loss compared to a strong YOCO baseline, indicating superior performance scalability under large-scale compute regimes. Our largest model enhanced with Differential Attention, Phi4-mini-Flash-Reasoning, achieves significantly better performance than Phi4-mini-Reasoning on reasoning tasks such as Math500, AIME24/25, and GPQA Diamond without any reinforcement learning, while delivering up to 10x higher decoding throughput on 2K-length prompts with 32K generation length under the vLLM inference framework. We release our training codebase on open-source data at https://github.com/microsoft/ArchScale.