 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient Pre-training: Exploring FP4 Precision in Large Language Models
Feb 17, 2025The burgeoning computational demands for training large language models (LLMs) necessitate efficient methods, including quantized training, which leverages low-bit arithmetic operations to reduce costs. While FP8 precision has shown potential, leveraging FP4 remains challenging due to inherent quantization errors and limited representation capability. Based on the Transformer architecture, we present an FP4 training scheme for LLMs, overcoming these obstacles through mixed-precision quantization strategies tailed for different modules and training stages. This allows us to apply the precision level suitable to distinct components within the model, ensuring that multi-head attention and linear layers are handled appropriately. Our pretraining recipe ensures stability in backpropagation by incorporating fine-grained quantization methods with a target precision training schedule. Experimental results demonstrate that our FP4 training scheme achieves accuracy comparable to BF16 and FP8, with smaller theoretical computational cost. With the advent of next-generation hardware supporting FP4, our method sets the foundation for efficient ultra-low precision training.
Fisheye-GS: Lightweight and Extensible Gaussian Splatting Module for Fisheye Cameras
Sep 11, 2024Recently, 3D Gaussian Splatting (3DGS) has garnered attention for its high fidelity and real-time rendering. However, adapting 3DGS to different camera models, particularly fisheye lenses, poses challenges due to the unique 3D to 2D projection calculation. Additionally, there are inefficiencies in the tile-based splatting, especially for the extreme curvature and wide field of view of fisheye lenses, which are crucial for its broader real-life applications. To tackle these challenges, we introduce Fisheye-GS.This innovative method recalculates the projection transformation and its gradients for fisheye cameras. Our approach can be seamlessly integrated as a module into other efficient 3D rendering methods, emphasizing its extensibility, lightweight nature, and modular design. Since we only modified the projection component, it can also be easily adapted for use with different camera models. Compared to methods that train after undistortion, our approach demonstrates a clear improvement in visual quality.
FlashGS: Efficient 3D Gaussian Splatting for Large-scale and High-resolution Rendering
Aug 15, 2024

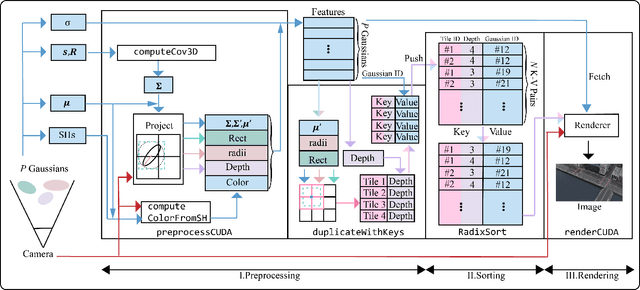

This work introduces FlashGS, an open-source CUDA Python library, designed to facilitate the efficient differentiable rasterization of 3D Gaussian Splatting through algorithmic and kernel-level optimizations. FlashGS is developed based on the observations from a comprehensive analysis of the rendering process to enhance computational efficiency and bring the technique to wide adoption. The paper includes a suite of optimization strategies, encompassing redundancy elimination, efficient pipelining, refined control and scheduling mechanisms, and memory access optimizations, all of which are meticulously integrated to amplify the performance of the rasterization process. An extensive evaluation of FlashGS' performance has been conducted across a diverse spectrum of synthetic and real-world large-scale scenes, encompassing a variety of image resolutions. The empirical findings demonstrate that FlashGS consistently achieves an average 4x acceleration over mobile consumer GPUs, coupled with reduced memory consumption. These results underscore the superior performance and resource optimization capabilities of FlashGS, positioning it as a formidable tool in the domain of 3D rendering.
PackMamba: Efficient Processing of Variable-Length Sequences in Mamba training
Aug 07, 2024



With the evolution of large language models, traditional Transformer models become computationally demanding for lengthy sequences due to the quadratic growth in computation with respect to the sequence length. Mamba, emerging as a groundbreaking architecture in the field of generative AI, demonstrates remarkable proficiency in handling elongated sequences with reduced computational and memory complexity. Nevertheless, the existing training framework of Mamba presents inefficiency with variable-length sequence inputs. Either single-sequence training results in low GPU utilization, or batched processing of variable-length sequences to a maximum length incurs considerable memory and computational overhead. To address this problem, we analyze the performance of bottleneck operators in Mamba under diverse tensor shapes and proposed PackMamba, a high-throughput Mamba that efficiently handles variable-length sequences. Diving deep into state-space models (SSMs), we modify the parallel operators to avoid passing information between individual sequences while maintaining high performance. Experimental results on an NVIDIA A100 GPU demonstrate throughput exceeding the baseline single-sequence processing scheme: 3.06x speedup on the 1.4B model and 2.62x on the 2.8B model.