 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMxMoE: Mixed-precision Quantization for MoE with Accuracy and Performance Co-Design
May 09, 2025



Mixture-of-Experts (MoE) models face deployment challenges due to their large parameter counts and computational demands. We explore quantization for MoE models and highlight two key insights: 1) linear blocks exhibit varying quantization sensitivity, and 2) divergent expert activation frequencies create heterogeneous computational characteristics. Based on these observations, we introduce MxMoE, a mixed-precision optimization framework for MoE models that considers both algorithmic and system perspectives. MxMoE navigates the design space defined by parameter sensitivity, expert activation dynamics, and hardware resources to derive efficient mixed-precision configurations. Additionally, MxMoE automatically generates optimized mixed-precision GroupGEMM kernels, enabling parallel execution of GEMMs with different precisions. Evaluations show that MxMoE outperforms existing methods, achieving 2.4 lower Wikitext-2 perplexity than GPTQ at 2.25-bit and delivering up to 3.4x speedup over full precision, as well as up to 29.4% speedup over uniform quantization at equivalent accuracy with 5-bit weight-activation quantization. Our code is available at https://github.com/cat538/MxMoE.
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Apr 15, 2025We introduce InternVL3, a significant advancement in the InternVL series featuring a native multimodal pre-training paradigm. Rather than adapting a text-only large language model (LLM) into a multimodal large language model (MLLM) that supports visual inputs, InternVL3 jointly acquires multimodal and linguistic capabilities from both diverse multimodal data and pure-text corpora during a single pre-training stage. This unified training paradigm effectively addresses the complexities and alignment challenges commonly encountered in conventional post-hoc training pipelines for MLLMs. To further improve performance and scalability, InternVL3 incorporates variable visual position encoding (V2PE) to support extended multimodal contexts, employs advanced post-training techniques such as supervised fine-tuning (SFT) and mixed preference optimization (MPO), and adopts test-time scaling strategies alongside an optimized training infrastructure. Extensive empirical evaluations demonstrate that InternVL3 delivers superior performance across a wide range of multi-modal tasks. In particular, InternVL3-78B achieves a score of 72.2 on the MMMU benchmark, setting a new state-of-the-art among open-source MLLMs. Its capabilities remain highly competitive with leading proprietary models, including ChatGPT-4o, Claude 3.5 Sonnet, and Gemini 2.5 Pro, while also maintaining strong pure-language proficiency. In pursuit of open-science principles, we will publicly release both the training data and model weights to foster further research and development in next-generation MLLMs.
GS-Cache: A GS-Cache Inference Framework for Large-scale Gaussian Splatting Models
Feb 20, 2025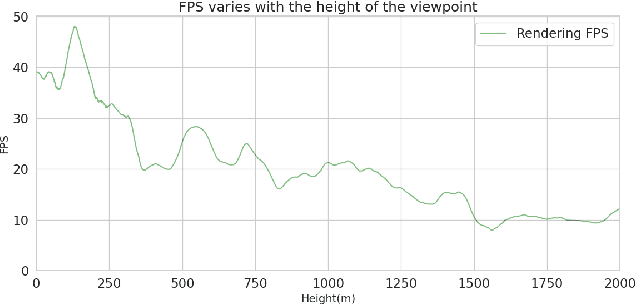
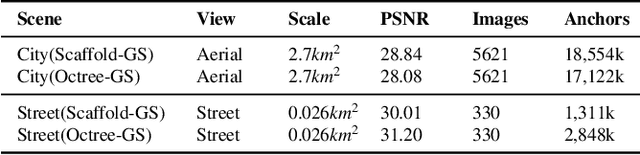
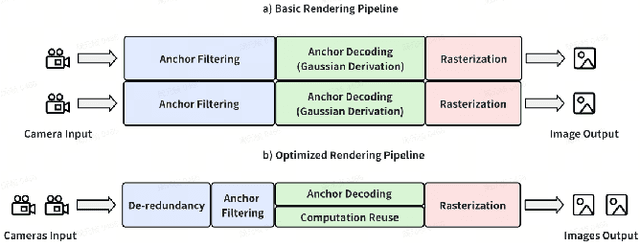
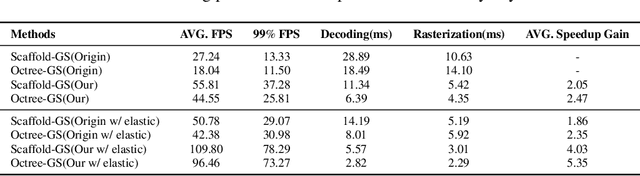
Rendering large-scale 3D Gaussian Splatting (3DGS) model faces significant challenges in achieving real-time, high-fidelity performance on consumer-grade devices. Fully realizing the potential of 3DGS in applications such as virtual reality (VR) requires addressing critical system-level challenges to support real-time, immersive experiences. We propose GS-Cache, an end-to-end framework that seamlessly integrates 3DGS's advanced representation with a highly optimized rendering system. GS-Cache introduces a cache-centric pipeline to eliminate redundant computations, an efficiency-aware scheduler for elastic multi-GPU rendering, and optimized CUDA kernels to overcome computational bottlenecks. This synergy between 3DGS and system design enables GS-Cache to achieve up to 5.35x performance improvement, 35% latency reduction, and 42% lower GPU memory usage, supporting 2K binocular rendering at over 120 FPS with high visual quality. By bridging the gap between 3DGS's representation power and the demands of VR systems, GS-Cache establishes a scalable and efficient framework for real-time neural rendering in immersive environments.
Towards Efficient Pre-training: Exploring FP4 Precision in Large Language Models
Feb 17, 2025The burgeoning computational demands for training large language models (LLMs) necessitate efficient methods, including quantized training, which leverages low-bit arithmetic operations to reduce costs. While FP8 precision has shown potential, leveraging FP4 remains challenging due to inherent quantization errors and limited representation capability. Based on the Transformer architecture, we present an FP4 training scheme for LLMs, overcoming these obstacles through mixed-precision quantization strategies tailed for different modules and training stages. This allows us to apply the precision level suitable to distinct components within the model, ensuring that multi-head attention and linear layers are handled appropriately. Our pretraining recipe ensures stability in backpropagation by incorporating fine-grained quantization methods with a target precision training schedule. Experimental results demonstrate that our FP4 training scheme achieves accuracy comparable to BF16 and FP8, with smaller theoretical computational cost. With the advent of next-generation hardware supporting FP4, our method sets the foundation for efficient ultra-low precision training.
InternLM-XComposer2.5-OmniLive: A Comprehensive Multimodal System for Long-term Streaming Video and Audio Interactions
Dec 12, 2024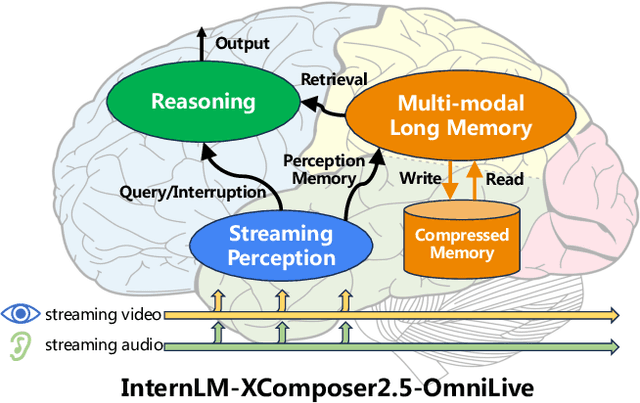
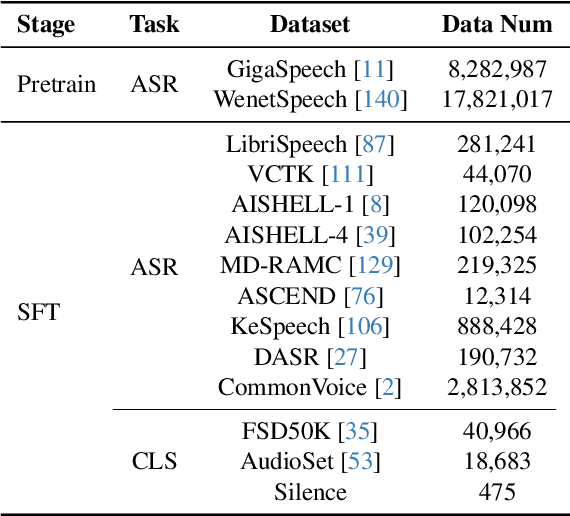
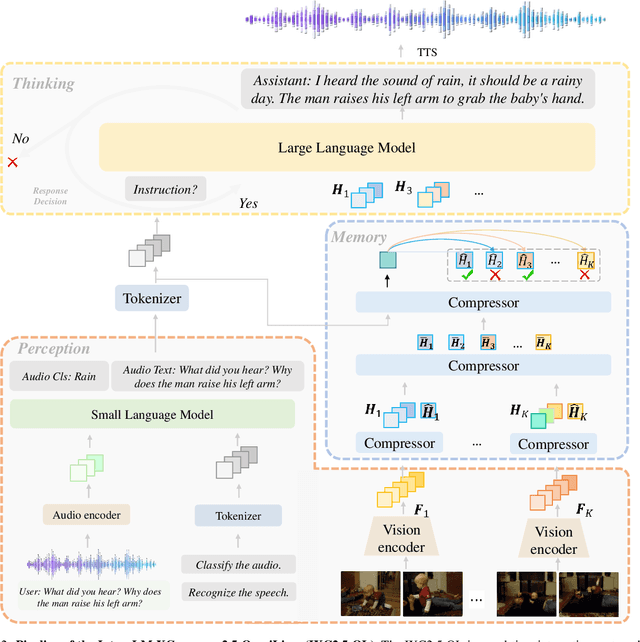

Creating AI systems that can interact with environments over long periods, similar to human cognition, has been a longstanding research goal. Recent advancements in multimodal large language models (MLLMs) have made significant strides in open-world understanding. However, the challenge of continuous and simultaneous streaming perception, memory, and reasoning remains largely unexplored. Current MLLMs are constrained by their sequence-to-sequence architecture, which limits their ability to process inputs and generate responses simultaneously, akin to being unable to think while perceiving. Furthermore, relying on long contexts to store historical data is impractical for long-term interactions, as retaining all information becomes costly and inefficient. Therefore, rather than relying on a single foundation model to perform all functions, this project draws inspiration from the concept of the Specialized Generalist AI and introduces disentangled streaming perception, reasoning, and memory mechanisms, enabling real-time interaction with streaming video and audio input. The proposed framework InternLM-XComposer2.5-OmniLive (IXC2.5-OL) consists of three key modules: (1) Streaming Perception Module: Processes multimodal information in real-time, storing key details in memory and triggering reasoning in response to user queries. (2) Multi-modal Long Memory Module: Integrates short-term and long-term memory, compressing short-term memories into long-term ones for efficient retrieval and improved accuracy. (3) Reasoning Module: Responds to queries and executes reasoning tasks, coordinating with the perception and memory modules. This project simulates human-like cognition, enabling multimodal large language models to provide continuous and adaptive service over time.
Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling
Dec 06, 2024



We introduce InternVL 2.5, an advanced multimodal large language model (MLLM) series that builds upon InternVL 2.0, maintaining its core model architecture while introducing significant enhancements in training and testing strategies as well as data quality. In this work, we delve into the relationship between model scaling and performance, systematically exploring the performance trends in vision encoders, language models, dataset sizes, and test-time configurations. Through extensive evaluations on a wide range of benchmarks, including multi-discipline reasoning, document understanding, multi-image / video understanding, real-world comprehension, multimodal hallucination detection, visual grounding, multilingual capabilities, and pure language processing, InternVL 2.5 exhibits competitive performance, rivaling leading commercial models such as GPT-4o and Claude-3.5-Sonnet. Notably, our model is the first open-source MLLMs to surpass 70% on the MMMU benchmark, achieving a 3.7-point improvement through Chain-of-Thought (CoT) reasoning and showcasing strong potential for test-time scaling. We hope this model contributes to the open-source community by setting new standards for developing and applying multimodal AI systems. HuggingFace demo see https://huggingface.co/spaces/OpenGVLab/InternVL
Fisheye-GS: Lightweight and Extensible Gaussian Splatting Module for Fisheye Cameras
Sep 11, 2024Recently, 3D Gaussian Splatting (3DGS) has garnered attention for its high fidelity and real-time rendering. However, adapting 3DGS to different camera models, particularly fisheye lenses, poses challenges due to the unique 3D to 2D projection calculation. Additionally, there are inefficiencies in the tile-based splatting, especially for the extreme curvature and wide field of view of fisheye lenses, which are crucial for its broader real-life applications. To tackle these challenges, we introduce Fisheye-GS.This innovative method recalculates the projection transformation and its gradients for fisheye cameras. Our approach can be seamlessly integrated as a module into other efficient 3D rendering methods, emphasizing its extensibility, lightweight nature, and modular design. Since we only modified the projection component, it can also be easily adapted for use with different camera models. Compared to methods that train after undistortion, our approach demonstrates a clear improvement in visual quality.
PSE-Net: Channel Pruning for Convolutional Neural Networks with Parallel-subnets Estimator
Aug 29, 2024



Channel Pruning is one of the most widespread techniques used to compress deep neural networks while maintaining their performances. Currently, a typical pruning algorithm leverages neural architecture search to directly find networks with a configurable width, the key step of which is to identify representative subnet for various pruning ratios by training a supernet. However, current methods mainly follow a serial training strategy to optimize supernet, which is very time-consuming. In this work, we introduce PSE-Net, a novel parallel-subnets estimator for efficient channel pruning. Specifically, we propose a parallel-subnets training algorithm that simulate the forward-backward pass of multiple subnets by droping extraneous features on batch dimension, thus various subnets could be trained in one round. Our proposed algorithm facilitates the efficiency of supernet training and equips the network with the ability to interpolate the accuracy of unsampled subnets, enabling PSE-Net to effectively evaluate and rank the subnets. Over the trained supernet, we develop a prior-distributed-based sampling algorithm to boost the performance of classical evolutionary search. Such algorithm utilizes the prior information of supernet training phase to assist in the search of optimal subnets while tackling the challenge of discovering samples that satisfy resource constraints due to the long-tail distribution of network configuration. Extensive experiments demonstrate PSE-Net outperforms previous state-of-the-art channel pruning methods on the ImageNet dataset while retaining superior supernet training efficiency. For example, under 300M FLOPs constraint, our pruned MobileNetV2 achieves 75.2% Top-1 accuracy on ImageNet dataset, exceeding the original MobileNetV2 by 2.6 units while only cost 30%/16% times than BCNet/AutoAlim.
FlashGS: Efficient 3D Gaussian Splatting for Large-scale and High-resolution Rendering
Aug 15, 2024

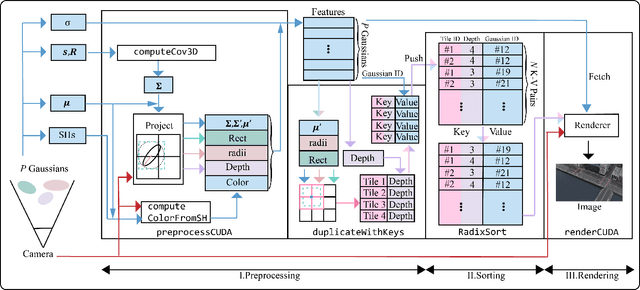

This work introduces FlashGS, an open-source CUDA Python library, designed to facilitate the efficient differentiable rasterization of 3D Gaussian Splatting through algorithmic and kernel-level optimizations. FlashGS is developed based on the observations from a comprehensive analysis of the rendering process to enhance computational efficiency and bring the technique to wide adoption. The paper includes a suite of optimization strategies, encompassing redundancy elimination, efficient pipelining, refined control and scheduling mechanisms, and memory access optimizations, all of which are meticulously integrated to amplify the performance of the rasterization process. An extensive evaluation of FlashGS' performance has been conducted across a diverse spectrum of synthetic and real-world large-scale scenes, encompassing a variety of image resolutions. The empirical findings demonstrate that FlashGS consistently achieves an average 4x acceleration over mobile consumer GPUs, coupled with reduced memory consumption. These results underscore the superior performance and resource optimization capabilities of FlashGS, positioning it as a formidable tool in the domain of 3D rendering.
PackMamba: Efficient Processing of Variable-Length Sequences in Mamba training
Aug 07, 2024



With the evolution of large language models, traditional Transformer models become computationally demanding for lengthy sequences due to the quadratic growth in computation with respect to the sequence length. Mamba, emerging as a groundbreaking architecture in the field of generative AI, demonstrates remarkable proficiency in handling elongated sequences with reduced computational and memory complexity. Nevertheless, the existing training framework of Mamba presents inefficiency with variable-length sequence inputs. Either single-sequence training results in low GPU utilization, or batched processing of variable-length sequences to a maximum length incurs considerable memory and computational overhead. To address this problem, we analyze the performance of bottleneck operators in Mamba under diverse tensor shapes and proposed PackMamba, a high-throughput Mamba that efficiently handles variable-length sequences. Diving deep into state-space models (SSMs), we modify the parallel operators to avoid passing information between individual sequences while maintaining high performance. Experimental results on an NVIDIA A100 GPU demonstrate throughput exceeding the baseline single-sequence processing scheme: 3.06x speedup on the 1.4B model and 2.62x on the 2.8B model.