 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearch on World Models Is Not Merely Injecting World Knowledge into Specific Tasks
Feb 02, 2026World models have emerged as a critical frontier in AI research, aiming to enhance large models by infusing them with physical dynamics and world knowledge. The core objective is to enable agents to understand, predict, and interact with complex environments. However, current research landscape remains fragmented, with approaches predominantly focused on injecting world knowledge into isolated tasks, such as visual prediction, 3D estimation, or symbol grounding, rather than establishing a unified definition or framework. While these task-specific integrations yield performance gains, they often lack the systematic coherence required for holistic world understanding. In this paper, we analyze the limitations of such fragmented approaches and propose a unified design specification for world models. We suggest that a robust world model should not be a loose collection of capabilities but a normative framework that integrally incorporates interaction, perception, symbolic reasoning, and spatial representation. This work aims to provide a structured perspective to guide future research toward more general, robust, and principled models of the world.
DataFlow: An LLM-Driven Framework for Unified Data Preparation and Workflow Automation in the Era of Data-Centric AI
Dec 18, 2025The rapidly growing demand for high-quality data in Large Language Models (LLMs) has intensified the need for scalable, reliable, and semantically rich data preparation pipelines. However, current practices remain dominated by ad-hoc scripts and loosely specified workflows, which lack principled abstractions, hinder reproducibility, and offer limited support for model-in-the-loop data generation. To address these challenges, we present DataFlow, a unified and extensible LLM-driven data preparation framework. DataFlow is designed with system-level abstractions that enable modular, reusable, and composable data transformations, and provides a PyTorch-style pipeline construction API for building debuggable and optimizable dataflows. The framework consists of nearly 200 reusable operators and six domain-general pipelines spanning text, mathematical reasoning, code, Text-to-SQL, agentic RAG, and large-scale knowledge extraction. To further improve usability, we introduce DataFlow-Agent, which automatically translates natural-language specifications into executable pipelines via operator synthesis, pipeline planning, and iterative verification. Across six representative use cases, DataFlow consistently improves downstream LLM performance. Our math, code, and text pipelines outperform curated human datasets and specialized synthetic baselines, achieving up to +3\% execution accuracy in Text-to-SQL over SynSQL, +7\% average improvements on code benchmarks, and 1--3 point gains on MATH, GSM8K, and AIME. Moreover, a unified 10K-sample dataset produced by DataFlow enables base models to surpass counterparts trained on 1M Infinity-Instruct data. These results demonstrate that DataFlow provides a practical and high-performance substrate for reliable, reproducible, and scalable LLM data preparation, and establishes a system-level foundation for future data-centric AI development.
DOCR-Inspector: Fine-Grained and Automated Evaluation of Document Parsing with VLM
Dec 11, 2025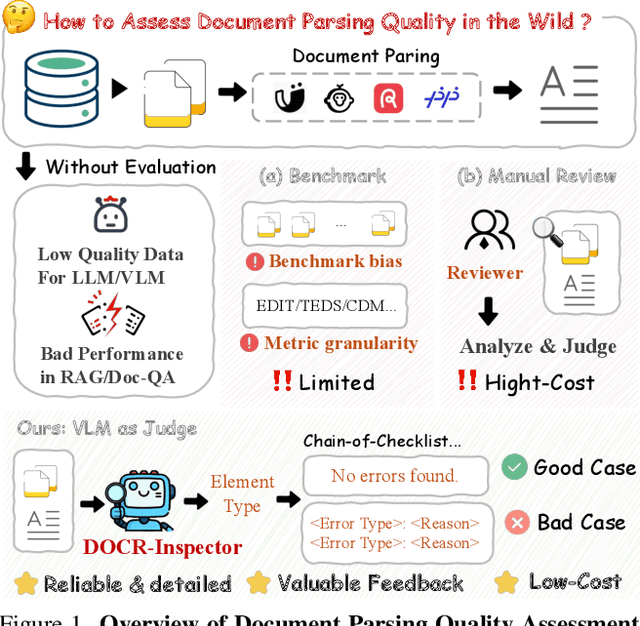
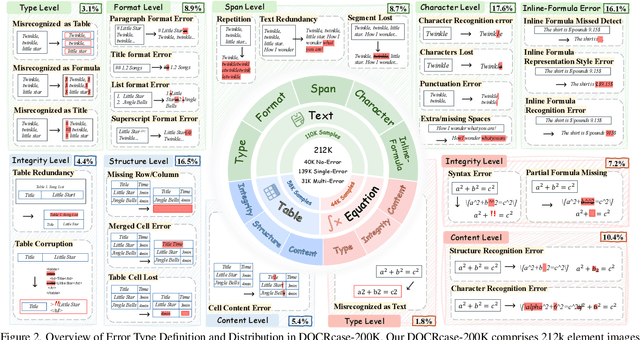

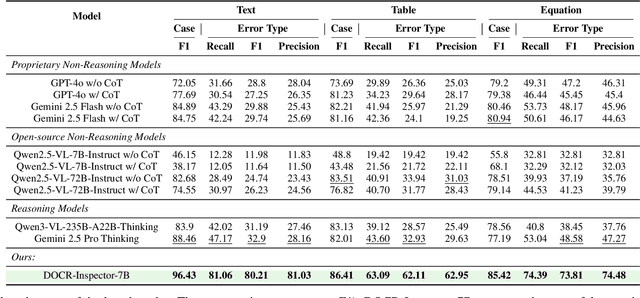
Document parsing aims to transform unstructured PDF images into semi-structured data, facilitating the digitization and utilization of information in diverse domains. While vision language models (VLMs) have significantly advanced this task, achieving reliable, high-quality parsing in real-world scenarios remains challenging. Common practice often selects the top-performing model on standard benchmarks. However, these benchmarks may carry dataset-specific biases, leading to inconsistent model rankings and limited correlation with real-world performance. Moreover, benchmark metrics typically provide only overall scores, which can obscure distinct error patterns in output. This raises a key challenge: how can we reliably and comprehensively assess document parsing quality in the wild? We address this problem with DOCR-Inspector, which formalizes document parsing assessment as fine-grained error detection and analysis. Leveraging VLM-as-a-Judge, DOCR-Inspector analyzes a document image and its parsed output, identifies all errors, assigns them to one of 28 predefined types, and produces a comprehensive quality assessment. To enable this capability, we construct DOCRcase-200K for training and propose the Chain-of-Checklist reasoning paradigm to enable the hierarchical structure of parsing quality assessment. For empirical validation, we introduce DOCRcaseBench, a set of 882 real-world document parsing cases with manual annotations. On this benchmark, DOCR-Inspector-7B outperforms commercial models like Gemini 2.5 Pro, as well as leading open-source models. Further experiments demonstrate that its quality assessments provide valuable guidance for parsing results refinement, making DOCR-Inspector both a practical evaluator and a driver for advancing document parsing systems at scale. Model and code are released at: https://github.com/ZZZZZQT/DOCR-Inspector.
VABench: A Comprehensive Benchmark for Audio-Video Generation
Dec 10, 2025Recent advances in video generation have been remarkable, enabling models to produce visually compelling videos with synchronized audio. While existing video generation benchmarks provide comprehensive metrics for visual quality, they lack convincing evaluations for audio-video generation, especially for models aiming to generate synchronized audio-video outputs. To address this gap, we introduce VABench, a comprehensive and multi-dimensional benchmark framework designed to systematically evaluate the capabilities of synchronous audio-video generation. VABench encompasses three primary task types: text-to-audio-video (T2AV), image-to-audio-video (I2AV), and stereo audio-video generation. It further establishes two major evaluation modules covering 15 dimensions. These dimensions specifically assess pairwise similarities (text-video, text-audio, video-audio), audio-video synchronization, lip-speech consistency, and carefully curated audio and video question-answering (QA) pairs, among others. Furthermore, VABench covers seven major content categories: animals, human sounds, music, environmental sounds, synchronous physical sounds, complex scenes, and virtual worlds. We provide a systematic analysis and visualization of the evaluation results, aiming to establish a new standard for assessing video generation models with synchronous audio capabilities and to promote the comprehensive advancement of the field.
MorphoBench: A Benchmark with Difficulty Adaptive to Model Reasoning
Oct 16, 2025

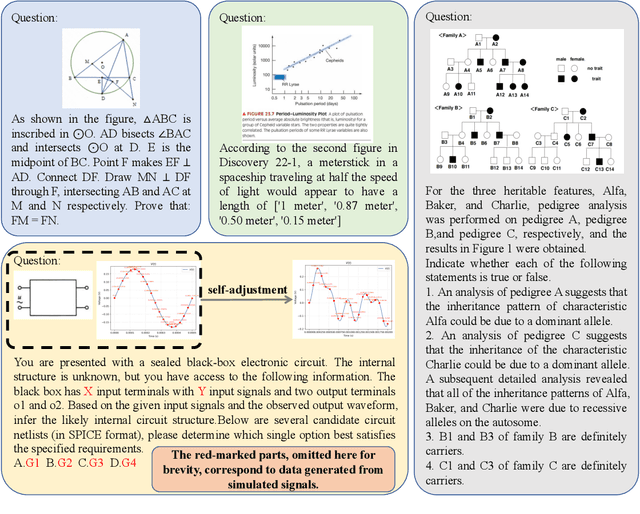
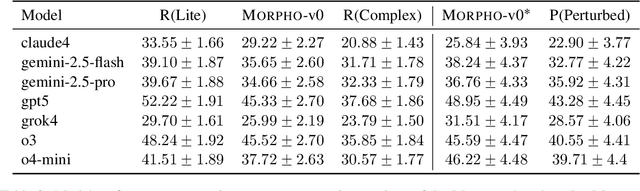
With the advancement of powerful large-scale reasoning models, effectively evaluating the reasoning capabilities of these models has become increasingly important. However, existing benchmarks designed to assess the reasoning abilities of large models tend to be limited in scope and lack the flexibility to adapt their difficulty according to the evolving reasoning capacities of the models. To address this, we propose MorphoBench, a benchmark that incorporates multidisciplinary questions to evaluate the reasoning capabilities of large models and can adjust and update question difficulty based on the reasoning abilities of advanced models. Specifically, we curate the benchmark by selecting and collecting complex reasoning questions from existing benchmarks and sources such as Olympiad-level competitions. Additionally, MorphoBench adaptively modifies the analytical challenge of questions by leveraging key statements generated during the model's reasoning process. Furthermore, it includes questions generated using simulation software, enabling dynamic adjustment of benchmark difficulty with minimal resource consumption. We have gathered over 1,300 test questions and iteratively adjusted the difficulty of MorphoBench based on the reasoning capabilities of models such as o3 and GPT-5. MorphoBench enhances the comprehensiveness and validity of model reasoning evaluation, providing reliable guidance for improving both the reasoning abilities and scientific robustness of large models. The code has been released in https://github.com/OpenDCAI/MorphoBench.
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Sep 26, 2025We introduce MinerU2.5, a 1.2B-parameter document parsing vision-language model that achieves state-of-the-art recognition accuracy while maintaining exceptional computational efficiency. Our approach employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. In the first stage, the model performs efficient layout analysis on downsampled images to identify structural elements, circumventing the computational overhead of processing high-resolution inputs. In the second stage, guided by the global layout, it performs targeted content recognition on native-resolution crops extracted from the original image, preserving fine-grained details in dense text, complex formulas, and tables. To support this strategy, we developed a comprehensive data engine that generates diverse, large-scale training corpora for both pretraining and fine-tuning. Ultimately, MinerU2.5 demonstrates strong document parsing ability, achieving state-of-the-art performance on multiple benchmarks, surpassing both general-purpose and domain-specific models across various recognition tasks, while maintaining significantly lower computational overhead.
Native Visual Understanding: Resolving Resolution Dilemmas in Vision-Language Models
Jun 15, 2025



Vision-Language Models (VLMs) face significant challenges when dealing with the diverse resolutions and aspect ratios of real-world images, as most existing models rely on fixed, low-resolution inputs. While recent studies have explored integrating native resolution visual encoding to improve model performance, such efforts remain fragmented and lack a systematic framework within the open-source community. Moreover, existing benchmarks fall short in evaluating VLMs under varied visual conditions, often neglecting resolution as a critical factor. To address the "Resolution Dilemma" stemming from both model design and benchmark limitations, we introduce RC-Bench, a novel benchmark specifically designed to systematically evaluate VLM capabilities under extreme visual conditions, with an emphasis on resolution and aspect ratio variations. In conjunction, we propose NativeRes-LLaVA, an open-source training framework that empowers VLMs to effectively process images at their native resolutions and aspect ratios. Based on RC-Bench and NativeRes-LLaVA, we conduct comprehensive experiments on existing visual encoding strategies. The results show that Native Resolution Visual Encoding significantly improves the performance of VLMs on RC-Bench as well as other resolution-centric benchmarks. Code is available at https://github.com/Niujunbo2002/NativeRes-LLaVA.
Learning What Reinforcement Learning Can't: Interleaved Online Fine-Tuning for Hardest Questions
Jun 09, 2025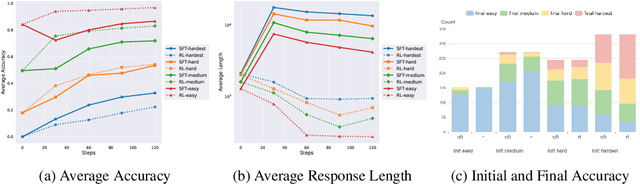
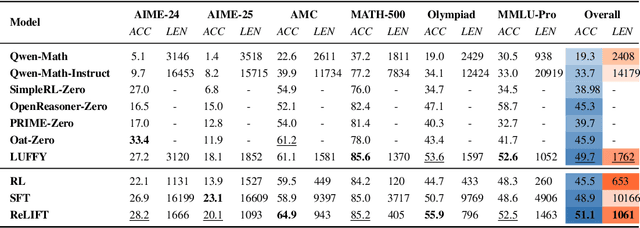
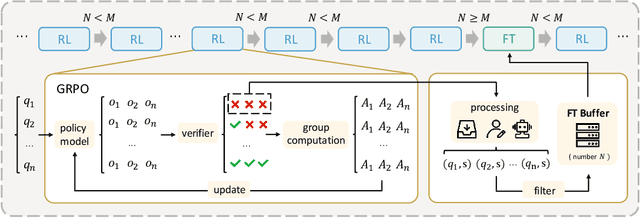
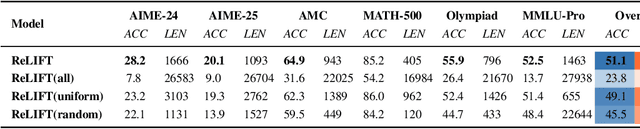
Recent advances in large language model (LLM) reasoning have shown that sophisticated behaviors such as planning and self-reflection can emerge through reinforcement learning (RL). However, despite these successes, RL in its current form remains insufficient to induce capabilities that exceed the limitations of the base model, as it is primarily optimized based on existing knowledge of the model rather than facilitating the acquisition of new information. To address this limitation, we employ supervised fine-tuning (SFT) to learn what RL cannot, which enables the incorporation of new knowledge and reasoning patterns by leveraging high-quality demonstration data. We analyze the training dynamics of RL and SFT for LLM reasoning and find that RL excels at maintaining and improving performance on questions within the model's original capabilities, while SFT is more effective at enabling progress on questions beyond the current scope of the model. Motivated by the complementary strengths of RL and SFT, we introduce a novel training approach, \textbf{ReLIFT} (\textbf{Re}inforcement \textbf{L}earning \textbf{I}nterleaved with Online \textbf{F}ine-\textbf{T}uning). In ReLIFT, the model is primarily trained using RL, but when it encounters challenging questions, high-quality solutions are collected for fine-tuning, and the training process alternates between RL and fine-tuning to enhance the model's reasoning abilities. ReLIFT achieves an average improvement of over +5.2 points across five competition-level benchmarks and one out-of-distribution benchmark compared to other zero-RL models. Furthermore, we demonstrate that ReLIFT outperforms both RL and SFT while using only 13\% of the detailed demonstration data, highlighting its scalability. These results provide compelling evidence that ReLIFT overcomes the fundamental limitations of RL and underscores the significant potential.
OVO-Bench: How Far is Your Video-LLMs from Real-World Online Video Understanding?
Jan 09, 2025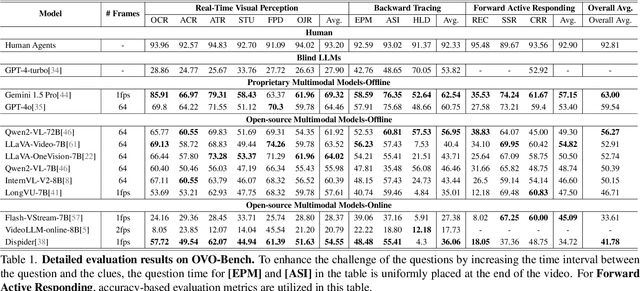
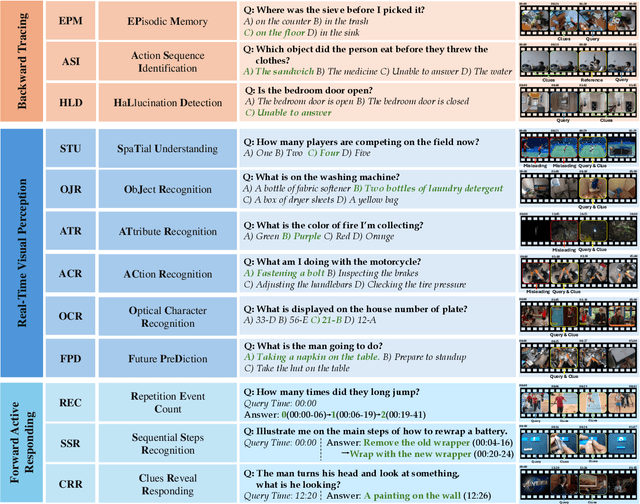
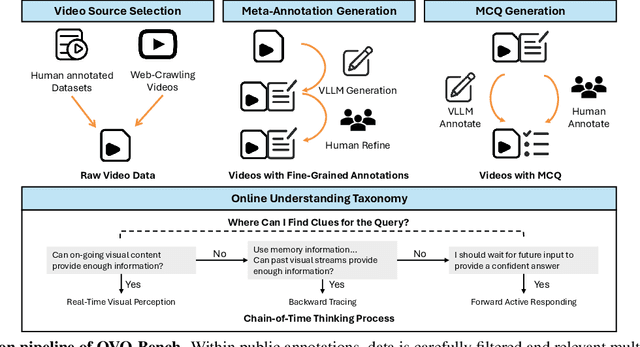
Temporal Awareness, the ability to reason dynamically based on the timestamp when a question is raised, is the key distinction between offline and online video LLMs. Unlike offline models, which rely on complete videos for static, post hoc analysis, online models process video streams incrementally and dynamically adapt their responses based on the timestamp at which the question is posed. Despite its significance, temporal awareness has not been adequately evaluated in existing benchmarks. To fill this gap, we present OVO-Bench (Online-VideO-Benchmark), a novel video benchmark that emphasizes the importance of timestamps for advanced online video understanding capability benchmarking. OVO-Bench evaluates the ability of video LLMs to reason and respond to events occurring at specific timestamps under three distinct scenarios: (1) Backward tracing: trace back to past events to answer the question. (2) Real-time understanding: understand and respond to events as they unfold at the current timestamp. (3) Forward active responding: delay the response until sufficient future information becomes available to answer the question accurately. OVO-Bench comprises 12 tasks, featuring 644 unique videos and approximately human-curated 2,800 fine-grained meta-annotations with precise timestamps. We combine automated generation pipelines with human curation. With these high-quality samples, we further developed an evaluation pipeline to systematically query video LLMs along the video timeline. Evaluations of nine Video-LLMs reveal that, despite advancements on traditional benchmarks, current models struggle with online video understanding, showing a significant gap compared to human agents. We hope OVO-Bench will drive progress in video LLMs and inspire future research in online video reasoning. Our benchmark and code can be accessed at https://github.com/JoeLeelyf/OVO-Bench.
InternLM-XComposer2.5-OmniLive: A Comprehensive Multimodal System for Long-term Streaming Video and Audio Interactions
Dec 12, 2024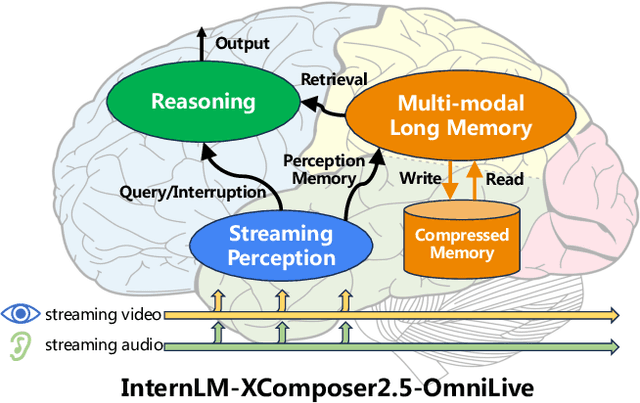
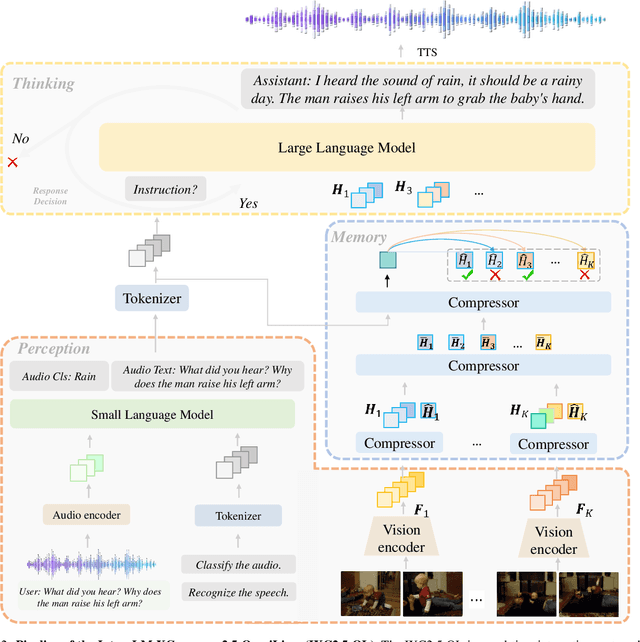

Creating AI systems that can interact with environments over long periods, similar to human cognition, has been a longstanding research goal. Recent advancements in multimodal large language models (MLLMs) have made significant strides in open-world understanding. However, the challenge of continuous and simultaneous streaming perception, memory, and reasoning remains largely unexplored. Current MLLMs are constrained by their sequence-to-sequence architecture, which limits their ability to process inputs and generate responses simultaneously, akin to being unable to think while perceiving. Furthermore, relying on long contexts to store historical data is impractical for long-term interactions, as retaining all information becomes costly and inefficient. Therefore, rather than relying on a single foundation model to perform all functions, this project draws inspiration from the concept of the Specialized Generalist AI and introduces disentangled streaming perception, reasoning, and memory mechanisms, enabling real-time interaction with streaming video and audio input. The proposed framework InternLM-XComposer2.5-OmniLive (IXC2.5-OL) consists of three key modules: (1) Streaming Perception Module: Processes multimodal information in real-time, storing key details in memory and triggering reasoning in response to user queries. (2) Multi-modal Long Memory Module: Integrates short-term and long-term memory, compressing short-term memories into long-term ones for efficient retrieval and improved accuracy. (3) Reasoning Module: Responds to queries and executes reasoning tasks, coordinating with the perception and memory modules. This project simulates human-like cognition, enabling multimodal large language models to provide continuous and adaptive service over time.