 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIFT: Unlocking Global Optimality in Post-Training via Finite-Temperature Gibbs Initialization
Jan 14, 2026The prevailing post-training paradigm for Large Reasoning Models (LRMs)--Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL)--suffers from an intrinsic optimization mismatch: the rigid supervision inherent in SFT induces distributional collapse, thereby exhausting the exploration space necessary for subsequent RL. In this paper, we reformulate SFT within a unified post-training framework and propose Gibbs Initialization with Finite Temperature (GIFT). We characterize standard SFT as a degenerate zero-temperature limit that suppresses base priors. Conversely, GIFT incorporates supervision as a finite-temperature energy potential, establishing a distributional bridge that ensures objective consistency throughout the post-training pipeline. Our experiments demonstrate that GIFT significantly outperforms standard SFT and other competitive baselines when utilized for RL initialization, providing a mathematically principled pathway toward achieving global optimality in post-training. Our code is available at https://github.com/zzy1127/GIFT.
DataFlow: An LLM-Driven Framework for Unified Data Preparation and Workflow Automation in the Era of Data-Centric AI
Dec 18, 2025The rapidly growing demand for high-quality data in Large Language Models (LLMs) has intensified the need for scalable, reliable, and semantically rich data preparation pipelines. However, current practices remain dominated by ad-hoc scripts and loosely specified workflows, which lack principled abstractions, hinder reproducibility, and offer limited support for model-in-the-loop data generation. To address these challenges, we present DataFlow, a unified and extensible LLM-driven data preparation framework. DataFlow is designed with system-level abstractions that enable modular, reusable, and composable data transformations, and provides a PyTorch-style pipeline construction API for building debuggable and optimizable dataflows. The framework consists of nearly 200 reusable operators and six domain-general pipelines spanning text, mathematical reasoning, code, Text-to-SQL, agentic RAG, and large-scale knowledge extraction. To further improve usability, we introduce DataFlow-Agent, which automatically translates natural-language specifications into executable pipelines via operator synthesis, pipeline planning, and iterative verification. Across six representative use cases, DataFlow consistently improves downstream LLM performance. Our math, code, and text pipelines outperform curated human datasets and specialized synthetic baselines, achieving up to +3\% execution accuracy in Text-to-SQL over SynSQL, +7\% average improvements on code benchmarks, and 1--3 point gains on MATH, GSM8K, and AIME. Moreover, a unified 10K-sample dataset produced by DataFlow enables base models to surpass counterparts trained on 1M Infinity-Instruct data. These results demonstrate that DataFlow provides a practical and high-performance substrate for reliable, reproducible, and scalable LLM data preparation, and establishes a system-level foundation for future data-centric AI development.
Let's Verify Math Questions Step by Step
May 20, 2025Large Language Models (LLMs) have recently achieved remarkable progress in mathematical reasoning. To enable such capabilities, many existing works distill strong reasoning models into long chains of thought or design algorithms to construct high-quality math QA data for training. However, these efforts primarily focus on generating correct reasoning paths and answers, while largely overlooking the validity of the questions themselves. In this work, we propose Math Question Verification (MathQ-Verify), a novel five-stage pipeline designed to rigorously filter ill-posed or under-specified math problems. MathQ-Verify first performs format-level validation to remove redundant instructions and ensure that each question is syntactically well-formed. It then formalizes each question, decomposes it into atomic conditions, and verifies them against mathematical definitions. Next, it detects logical contradictions among these conditions, followed by a goal-oriented completeness check to ensure the question provides sufficient information for solving. To evaluate this task, we use existing benchmarks along with an additional dataset we construct, containing 2,147 math questions with diverse error types, each manually double-validated. Experiments show that MathQ-Verify achieves state-of-the-art performance across multiple benchmarks, improving the F1 score by up to 25 percentage points over the direct verification baseline. It further attains approximately 90% precision and 63% recall through a lightweight model voting scheme. MathQ-Verify offers a scalable and accurate solution for curating reliable mathematical datasets, reducing label noise and avoiding unnecessary computation on invalid questions. Our code and data are available at https://github.com/scuuy/MathQ-Verify.
STMGF: An Effective Spatial-Temporal Multi-Granularity Framework for Traffic Forecasting
Apr 08, 2024



Accurate Traffic Prediction is a challenging task in intelligent transportation due to the spatial-temporal aspects of road networks. The traffic of a road network can be affected by long-distance or long-term dependencies where existing methods fall short in modeling them. In this paper, we introduce a novel framework known as Spatial-Temporal Multi-Granularity Framework (STMGF) to enhance the capture of long-distance and long-term information of the road networks. STMGF makes full use of different granularity information of road networks and models the long-distance and long-term information by gathering information in a hierarchical interactive way. Further, it leverages the inherent periodicity in traffic sequences to refine prediction results by matching with recent traffic data. We conduct experiments on two real-world datasets, and the results demonstrate that STMGF outperforms all baseline models and achieves state-of-the-art performance.
Position-Aware Parameter Efficient Fine-Tuning Approach for Reducing Positional Bias in LLMs
Apr 01, 2024Recent advances in large language models (LLMs) have enhanced their ability to process long input contexts. This development is particularly crucial for tasks that involve retrieving knowledge from an external datastore, which can result in long inputs. However, recent studies show a positional bias in LLMs, demonstrating varying performance depending on the location of useful information within the input sequence. In this study, we conduct extensive experiments to investigate the root causes of positional bias. Our findings indicate that the primary contributor to LLM positional bias stems from the inherent positional preferences of different models. We demonstrate that merely employing prompt-based solutions is inadequate for overcoming the positional preferences. To address this positional bias issue of a pre-trained LLM, we developed a Position-Aware Parameter Efficient Fine-Tuning (PAPEFT) approach which is composed of a data augmentation technique and a parameter efficient adapter, enhancing a uniform attention distribution across the input context. Our experiments demonstrate that the proposed approach effectively reduces positional bias, improving LLMs' effectiveness in handling long context sequences for various tasks that require externally retrieved knowledge.
RHCO: A Relation-aware Heterogeneous Graph Neural Network with Contrastive Learning for Large-scale Graphs
Nov 20, 2022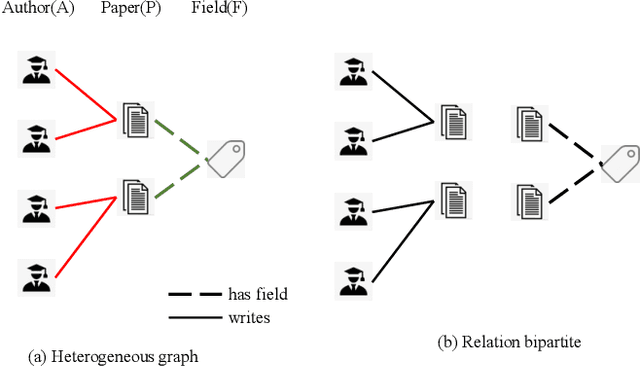
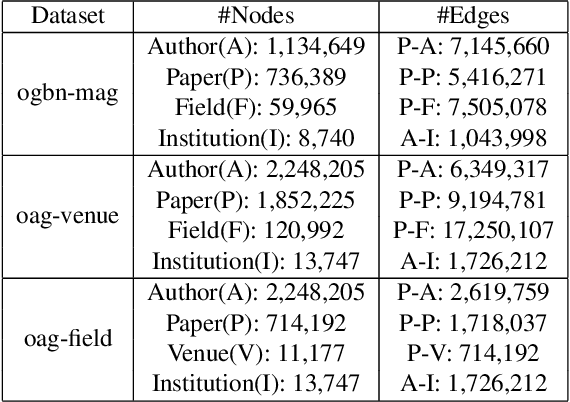
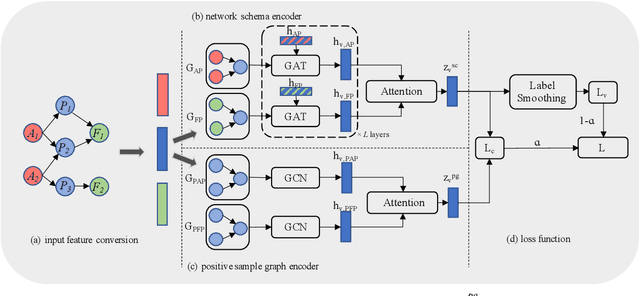
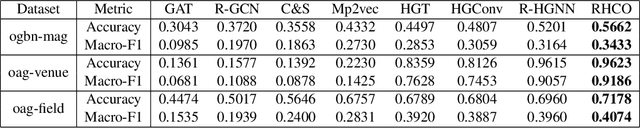
Heterogeneous graph neural networks (HGNNs) have been widely applied in heterogeneous information network tasks, while most HGNNs suffer from poor scalability or weak representation when they are applied to large-scale heterogeneous graphs. To address these problems, we propose a novel Relation-aware Heterogeneous Graph Neural Network with Contrastive Learning (RHCO) for large-scale heterogeneous graph representation learning. Unlike traditional heterogeneous graph neural networks, we adopt the contrastive learning mechanism to deal with the complex heterogeneity of large-scale heterogeneous graphs. We first learn relation-aware node embeddings under the network schema view. Then we propose a novel positive sample selection strategy to choose meaningful positive samples. After learning node embeddings under the positive sample graph view, we perform a cross-view contrastive learning to obtain the final node representations. Moreover, we adopt the label smoothing technique to boost the performance of RHCO. Extensive experiments on three large-scale academic heterogeneous graph datasets show that RHCO achieves best performance over the state-of-the-art models.
LightXML: Transformer with Dynamic Negative Sampling for High-Performance Extreme Multi-label Text Classification
Jan 09, 2021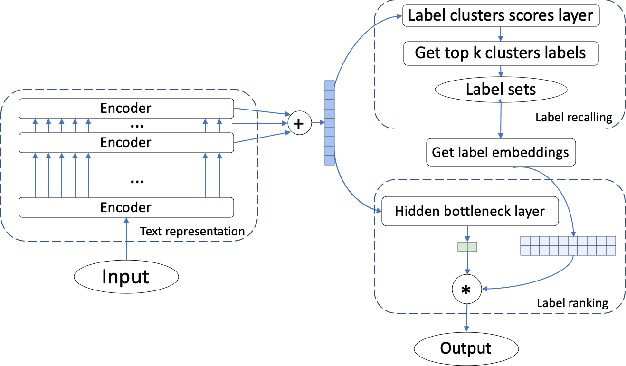
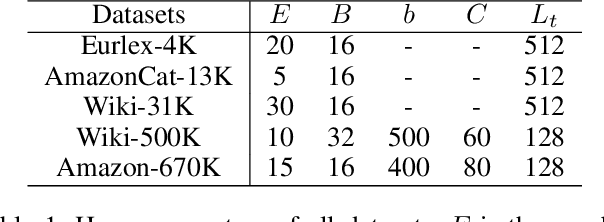


Extreme Multi-label text Classification (XMC) is a task of finding the most relevant labels from a large label set. Nowadays deep learning-based methods have shown significant success in XMC. However, the existing methods (e.g., AttentionXML and X-Transformer etc) still suffer from 1) combining several models to train and predict for one dataset, and 2) sampling negative labels statically during the process of training label ranking model, which reduces both the efficiency and accuracy of the model. To address the above problems, we proposed LightXML, which adopts end-to-end training and dynamic negative labels sampling. In LightXML, we use generative cooperative networks to recall and rank labels, in which label recalling part generates negative and positive labels, and label ranking part distinguishes positive labels from these labels. Through these networks, negative labels are sampled dynamically during label ranking part training by feeding with the same text representation. Extensive experiments show that LightXML outperforms state-of-the-art methods in five extreme multi-label datasets with much smaller model size and lower computational complexity. In particular, on the Amazon dataset with 670K labels, LightXML can reduce the model size up to 72% compared to AttentionXML.