 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sonar Moment: Benchmarking Audio-Language Models in Audio Geo-Localization
Jan 06, 2026Geo-localization aims to infer the geographic origin of a given signal. In computer vision, geo-localization has served as a demanding benchmark for compositional reasoning and is relevant to public safety. In contrast, progress on audio geo-localization has been constrained by the lack of high-quality audio-location pairs. To address this gap, we introduce AGL1K, the first audio geo-localization benchmark for audio language models (ALMs), spanning 72 countries and territories. To extract reliably localizable samples from a crowd-sourced platform, we propose the Audio Localizability metric that quantifies the informativeness of each recording, yielding 1,444 curated audio clips. Evaluations on 16 ALMs show that ALMs have emerged with audio geo-localization capability. We find that closed-source models substantially outperform open-source models, and that linguistic clues often dominate as a scaffold for prediction. We further analyze ALMs' reasoning traces, regional bias, error causes, and the interpretability of the localizability metric. Overall, AGL1K establishes a benchmark for audio geo-localization and may advance ALMs with better geospatial reasoning capability.
Behavior Tokens Speak Louder: Disentangled Explainable Recommendation with Behavior Vocabulary
Dec 17, 2025
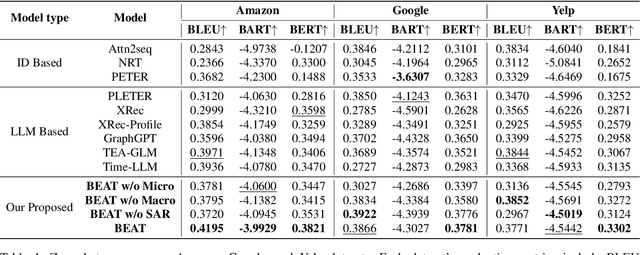


Recent advances in explainable recommendations have explored the integration of language models to analyze natural language rationales for user-item interactions. Despite their potential, existing methods often rely on ID-based representations that obscure semantic meaning and impose structural constraints on language models, thereby limiting their applicability in open-ended scenarios. These challenges are intensified by the complex nature of real-world interactions, where diverse user intents are entangled and collaborative signals rarely align with linguistic semantics. To overcome these limitations, we propose BEAT, a unified and transferable framework that tokenizes user and item behaviors into discrete, interpretable sequences. We construct a behavior vocabulary via a vector-quantized autoencoding process that disentangles macro-level interests and micro-level intentions from graph-based representations. We then introduce multi-level semantic supervision to bridge the gap between behavioral signals and language space. A semantic alignment regularization mechanism is designed to embed behavior tokens directly into the input space of frozen language models. Experiments on three public datasets show that BEAT improves zero-shot recommendation performance while generating coherent and informative explanations. Further analysis demonstrates that our behavior tokens capture fine-grained semantics and offer a plug-and-play interface for integrating complex behavior patterns into large language models.
Improving Temporal Link Prediction via Temporal Walk Matrix Projection
Oct 05, 2024



Temporal link prediction, aiming at predicting future interactions among entities based on historical interactions, is crucial for a series of real-world applications. Although previous methods have demonstrated the importance of relative encodings for effective temporal link prediction, computational efficiency remains a major concern in constructing these encodings. Moreover, existing relative encodings are usually constructed based on structural connectivity, where temporal information is seldom considered. To address the aforementioned issues, we first analyze existing relative encodings and unify them as a function of temporal walk matrices. This unification establishes a connection between relative encodings and temporal walk matrices, providing a more principled way for analyzing and designing relative encodings. Based on this analysis, we propose a new temporal graph neural network called TPNet, which introduces a temporal walk matrix that incorporates the time decay effect to simultaneously consider both temporal and structural information. Moreover, TPNet designs a random feature propagation mechanism with theoretical guarantees to implicitly maintain the temporal walk matrices, which improves the computation and storage efficiency. Experimental results on 13 benchmark datasets verify the effectiveness and efficiency of TPNet, where TPNet outperforms other baselines on most datasets and achieves a maximum speedup of $33.3 \times$ compared to the SOTA baseline. Our code can be found at \url{https://github.com/lxd99/TPNet}.
Co-Neighbor Encoding Schema: A Light-cost Structure Encoding Method for Dynamic Link Prediction
Jul 30, 2024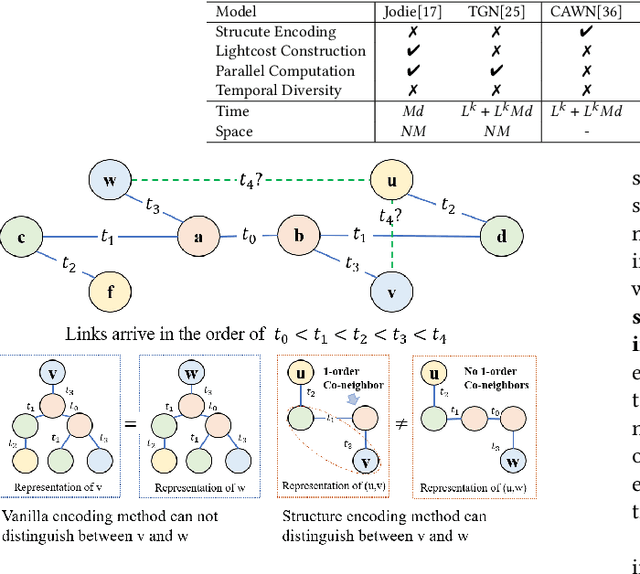

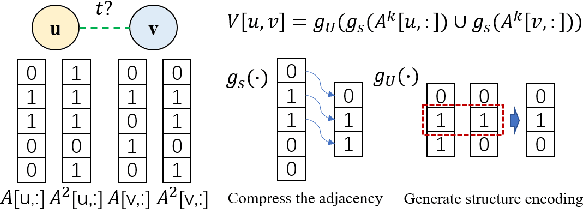
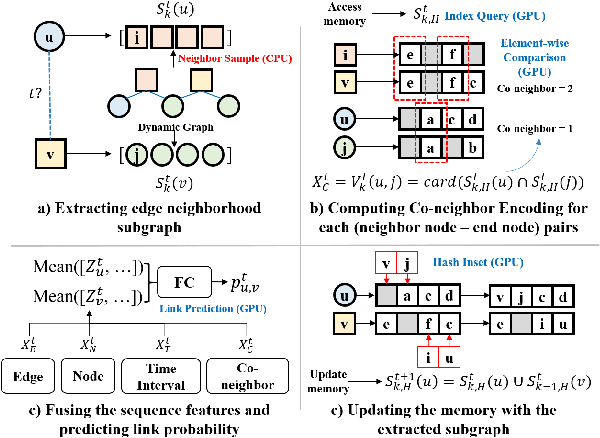
Structure encoding has proven to be the key feature to distinguishing links in a graph. However, Structure encoding in the temporal graph keeps changing as the graph evolves, repeatedly computing such features can be time-consuming due to the high-order subgraph construction. We develop the Co-Neighbor Encoding Schema (CNES) to address this issue. Instead of recomputing the feature by the link, CNES stores information in the memory to avoid redundant calculations. Besides, unlike the existing memory-based dynamic graph learning method that stores node hidden states, we introduce a hashtable-based memory to compress the adjacency matrix for efficient structure feature construction and updating with vector computation in parallel. Furthermore, CNES introduces a Temporal-Diverse Memory to generate long-term and short-term structure encoding for neighbors with different structural information. A dynamic graph learning framework, Co-Neighbor Encoding Network (CNE-N), is proposed using the aforementioned techniques. Extensive experiments on thirteen public datasets verify the effectiveness and efficiency of the proposed method.
DyGKT: Dynamic Graph Learning for Knowledge Tracing
Jul 30, 2024



Knowledge Tracing aims to assess student learning states by predicting their performance in answering questions. Different from the existing research which utilizes fixed-length learning sequence to obtain the student states and regards KT as a static problem, this work is motivated by three dynamical characteristics: 1) The scales of students answering records are constantly growing; 2) The semantics of time intervals between the records vary; 3) The relationships between students, questions and concepts are evolving. The three dynamical characteristics above contain the great potential to revolutionize the existing knowledge tracing methods. Along this line, we propose a Dynamic Graph-based Knowledge Tracing model, namely DyGKT. In particular, a continuous-time dynamic question-answering graph for knowledge tracing is constructed to deal with the infinitely growing answering behaviors, and it is worth mentioning that it is the first time dynamic graph learning technology is used in this field. Then, a dual time encoder is proposed to capture long-term and short-term semantics among the different time intervals. Finally, a multiset indicator is utilized to model the evolving relationships between students, questions, and concepts via the graph structural feature. Numerous experiments are conducted on five real-world datasets, and the results demonstrate the superiority of our model. All the used resources are publicly available at https://github.com/PengLinzhi/DyGKT.
Research on Foundation Model for Spatial Data Intelligence: China's 2024 White Paper on Strategic Development of Spatial Data Intelligence
May 30, 2024This report focuses on spatial data intelligent large models, delving into the principles, methods, and cutting-edge applications of these models. It provides an in-depth discussion on the definition, development history, current status, and trends of spatial data intelligent large models, as well as the challenges they face. The report systematically elucidates the key technologies of spatial data intelligent large models and their applications in urban environments, aerospace remote sensing, geography, transportation, and other scenarios. Additionally, it summarizes the latest application cases of spatial data intelligent large models in themes such as urban development, multimodal systems, remote sensing, smart transportation, and resource environments. Finally, the report concludes with an overview and outlook on the development prospects of spatial data intelligent large models.
Regions are Who Walk Them: a Large Pre-trained Spatiotemporal Model Based on Human Mobility for Ubiquitous Urban Sensing
Nov 17, 2023User profiling and region analysis are two tasks of significant commercial value. However, in practical applications, modeling different features typically involves four main steps: data preparation, data processing, model establishment, evaluation, and optimization. This process is time-consuming and labor-intensive. Repeating this workflow for each feature results in abundant development time for tasks and a reduced overall volume of task development. Indeed, human mobility data contains a wealth of information. Several successful cases suggest that conducting in-depth analysis of population movement data could potentially yield meaningful profiles about users and areas. Nonetheless, most related works have not thoroughly utilized the semantic information within human mobility data and trained on a fixed number of the regions. To tap into the rich information within population movement, based on the perspective that Regions Are Who walk them, we propose a large spatiotemporal model based on trajectories (RAW). It possesses the following characteristics: 1) Tailored for trajectory data, introducing a GPT-like structure with a parameter count of up to 1B; 2) Introducing a spatiotemporal fine-tuning module, interpreting trajectories as collection of users to derive arbitrary region embedding. This framework allows rapid task development based on the large spatiotemporal model. We conducted extensive experiments to validate the effectiveness of our proposed large spatiotemporal model. It's evident that our proposed method, relying solely on human mobility data without additional features, exhibits a certain level of relevance in user profiling and region analysis. Moreover, our model showcases promising predictive capabilities in trajectory generation tasks based on the current state, offering the potential for further innovative work utilizing this large spatiotemporal model.
Pretraining Language Models with Text-Attributed Heterogeneous Graphs
Oct 23, 2023In many real-world scenarios (e.g., academic networks, social platforms), different types of entities are not only associated with texts but also connected by various relationships, which can be abstracted as Text-Attributed Heterogeneous Graphs (TAHGs). Current pretraining tasks for Language Models (LMs) primarily focus on separately learning the textual information of each entity and overlook the crucial aspect of capturing topological connections among entities in TAHGs. In this paper, we present a new pretraining framework for LMs that explicitly considers the topological and heterogeneous information in TAHGs. Firstly, we define a context graph as neighborhoods of a target node within specific orders and propose a topology-aware pretraining task to predict nodes involved in the context graph by jointly optimizing an LM and an auxiliary heterogeneous graph neural network. Secondly, based on the observation that some nodes are text-rich while others have little text, we devise a text augmentation strategy to enrich textless nodes with their neighbors' texts for handling the imbalance issue. We conduct link prediction and node classification tasks on three datasets from various domains. Experimental results demonstrate the superiority of our approach over existing methods and the rationality of each design. Our code is available at https://github.com/Hope-Rita/THLM.
Self-optimizing Feature Generation via Categorical Hashing Representation and Hierarchical Reinforcement Crossing
Sep 14, 2023



Feature generation aims to generate new and meaningful features to create a discriminative representation space.A generated feature is meaningful when the generated feature is from a feature pair with inherent feature interaction. In the real world, experienced data scientists can identify potentially useful feature-feature interactions, and generate meaningful dimensions from an exponentially large search space, in an optimal crossing form over an optimal generation path. But, machines have limited human-like abilities.We generalize such learning tasks as self-optimizing feature generation. Self-optimizing feature generation imposes several under-addressed challenges on existing systems: meaningful, robust, and efficient generation. To tackle these challenges, we propose a principled and generic representation-crossing framework to solve self-optimizing feature generation.To achieve hashing representation, we propose a three-step approach: feature discretization, feature hashing, and descriptive summarization. To achieve reinforcement crossing, we develop a hierarchical reinforcement feature crossing approach.We present extensive experimental results to demonstrate the effectiveness and efficiency of the proposed method. The code is available at https://github.com/yingwangyang/HRC_feature_cross.git.
Adaptive Taxonomy Learning and Historical Patterns Modelling for Patent Classification
Aug 10, 2023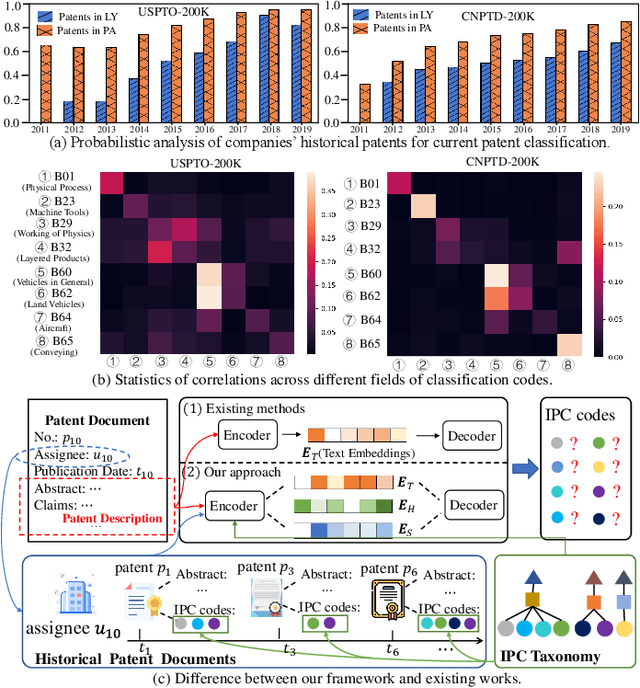

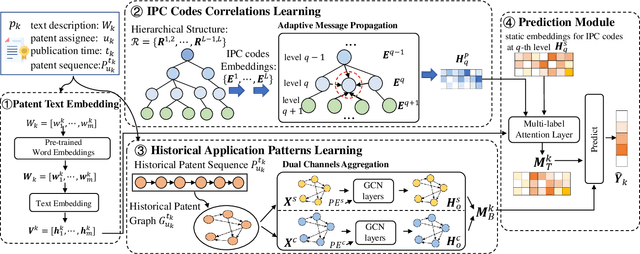
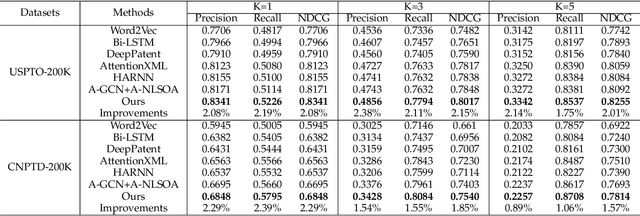
Patent classification aims to assign multiple International Patent Classification (IPC) codes to a given patent. Recent methods for automatically classifying patents mainly focus on analyzing the text descriptions of patents. However, apart from the texts, each patent is also associated with some assignees, and the knowledge of their applied patents is often valuable for classification. Furthermore, the hierarchical taxonomy formulated by the IPC system provides important contextual information and enables models to leverage the correlations between IPC codes for more accurate classification. However, existing methods fail to incorporate the above aspects. In this paper, we propose an integrated framework that comprehensively considers the information on patents for patent classification. To be specific, we first present an IPC codes correlations learning module to derive their semantic representations via adaptively passing and aggregating messages within the same level and across different levels along the hierarchical taxonomy. Moreover, we design a historical application patterns learning component to incorporate the corresponding assignee's previous patents by a dual channel aggregation mechanism. Finally, we combine the contextual information of patent texts that contains the semantics of IPC codes, and assignees' sequential preferences to make predictions. Experiments on real-world datasets demonstrate the superiority of our approach over the existing methods. Besides, we present the model's ability to capture the temporal patterns of assignees and the semantic dependencies among IPC codes.