 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEANCODE: Understanding Models Better for Code Simplification of Pre-trained Large Language Models
May 20, 2025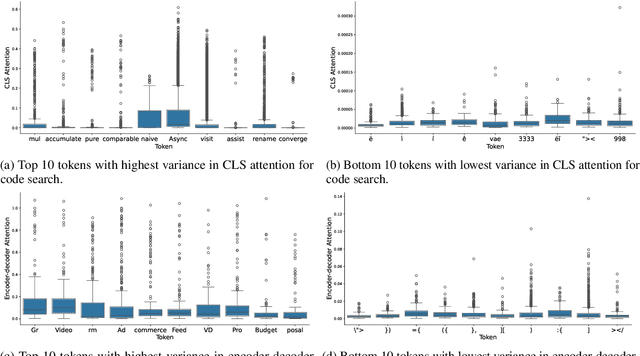
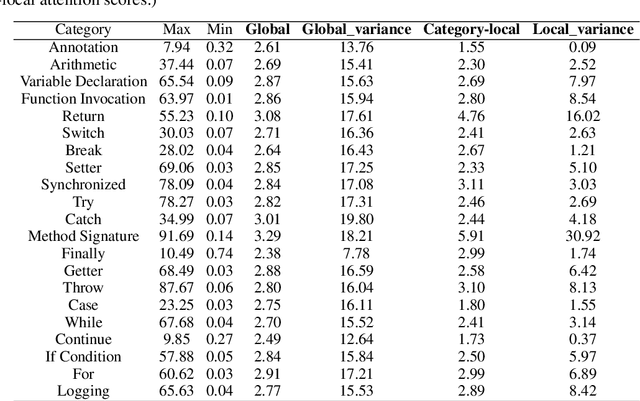
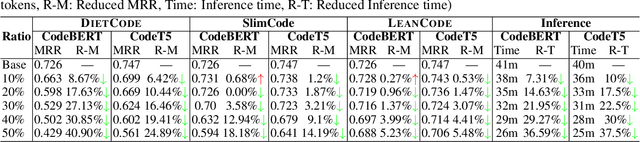

Large Language Models for code often entail significant computational complexity, which grows significantly with the length of the input code sequence. We propose LeanCode for code simplification to reduce training and prediction time, leveraging code contexts in utilizing attention scores to represent the tokens' importance. We advocate for the selective removal of tokens based on the average context-aware attention scores rather than average scores across all inputs. LeanCode uses the attention scores of `CLS' tokens within the encoder for classification tasks, such as code search. It also employs the encoder-decoder attention scores to determine token significance for sequence-to-sequence tasks like code summarization.Our evaluation shows LeanCode's superiority over the SOTAs DietCode and Slimcode, with improvements of 60% and 16% for code search, and 29% and 27% for code summarization, respectively.
Toward building next-generation Geocoding systems: a systematic review
Mar 24, 2025



Geocoding systems are widely used in both scientific research for spatial analysis and everyday life through location-based services. The quality of geocoded data significantly impacts subsequent processes and applications, underscoring the need for next-generation systems. In response to this demand, this review first examines the evolving requirements for geocoding inputs and outputs across various scenarios these systems must address. It then provides a detailed analysis of how to construct such systems by breaking them down into key functional components and reviewing a broad spectrum of existing approaches, from traditional rule-based methods to advanced techniques in information retrieval, natural language processing, and large language models. Finally, we identify opportunities to improve next-generation geocoding systems in light of recent technological advances.
A Comprehensive Review of 3D Object Detection in Autonomous Driving: Technological Advances and Future Directions
Aug 28, 2024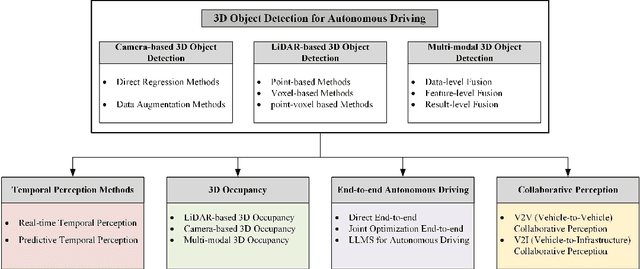

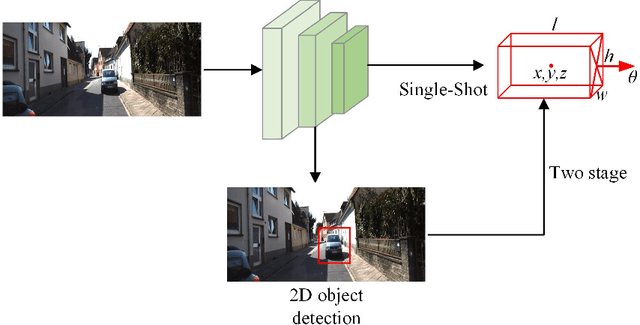

In recent years, 3D object perception has become a crucial component in the development of autonomous driving systems, providing essential environmental awareness. However, as perception tasks in autonomous driving evolve, their variants have increased, leading to diverse insights from industry and academia. Currently, there is a lack of comprehensive surveys that collect and summarize these perception tasks and their developments from a broader perspective. This review extensively summarizes traditional 3D object detection methods, focusing on camera-based, LiDAR-based, and fusion detection techniques. We provide a comprehensive analysis of the strengths and limitations of each approach, highlighting advancements in accuracy and robustness. Furthermore, we discuss future directions, including methods to improve accuracy such as temporal perception, occupancy grids, and end-to-end learning frameworks. We also explore cooperative perception methods that extend the perception range through collaborative communication. By providing a holistic view of the current state and future developments in 3D object perception, we aim to offer a more comprehensive understanding of perception tasks for autonomous driving. Additionally, we have established an active repository to provide continuous updates on the latest advancements in this field, accessible at: https://github.com/Fishsoup0/Autonomous-Driving-Perception.
Learning-based Models for Vulnerability Detection: An Extensive Study
Aug 14, 2024Though many deep learning-based models have made great progress in vulnerability detection, we have no good understanding of these models, which limits the further advancement of model capability, understanding of the mechanism of model detection, and efficiency and safety of practical application of models. In this paper, we extensively and comprehensively investigate two types of state-of-the-art learning-based approaches (sequence-based and graph-based) by conducting experiments on a recently built large-scale dataset. We investigate seven research questions from five dimensions, namely model capabilities, model interpretation, model stability, ease of use of model, and model economy. We experimentally demonstrate the priority of sequence-based models and the limited abilities of both LLM (ChatGPT) and graph-based models. We explore the types of vulnerability that learning-based models skilled in and reveal the instability of the models though the input is subtlely semantical-equivalently changed. We empirically explain what the models have learned. We summarize the pre-processing as well as requirements for easily using the models. Finally, we initially induce the vital information for economically and safely practical usage of these models.
Rectifier: Code Translation with Corrector via LLMs
Jul 10, 2024Software migration is garnering increasing attention with the evolution of software and society. Early studies mainly relied on handcrafted translation rules to translate between two languages, the translation process is error-prone and time-consuming. In recent years, researchers have begun to explore the use of pre-trained large language models (LLMs) in code translation. However, code translation is a complex task that LLMs would generate mistakes during code translation, they all produce certain types of errors when performing code translation tasks, which include (1) compilation error, (2) runtime error, (3) functional error, and (4) non-terminating execution. We found that the root causes of these errors are very similar (e.g. failure to import packages, errors in loop boundaries, operator errors, and more). In this paper, we propose a general corrector, namely Rectifier, which is a micro and universal model for repairing translation errors. It learns from errors generated by existing LLMs and can be widely applied to correct errors generated by any LLM. The experimental results on translation tasks between C++, Java, and Python show that our model has effective repair ability, and cross experiments also demonstrate the robustness of our method.
Research on Foundation Model for Spatial Data Intelligence: China's 2024 White Paper on Strategic Development of Spatial Data Intelligence
May 30, 2024This report focuses on spatial data intelligent large models, delving into the principles, methods, and cutting-edge applications of these models. It provides an in-depth discussion on the definition, development history, current status, and trends of spatial data intelligent large models, as well as the challenges they face. The report systematically elucidates the key technologies of spatial data intelligent large models and their applications in urban environments, aerospace remote sensing, geography, transportation, and other scenarios. Additionally, it summarizes the latest application cases of spatial data intelligent large models in themes such as urban development, multimodal systems, remote sensing, smart transportation, and resource environments. Finally, the report concludes with an overview and outlook on the development prospects of spatial data intelligent large models.
When Less is Enough: Positive and Unlabeled Learning Model for Vulnerability Detection
Aug 21, 2023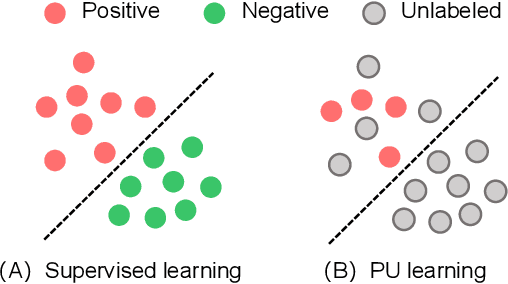
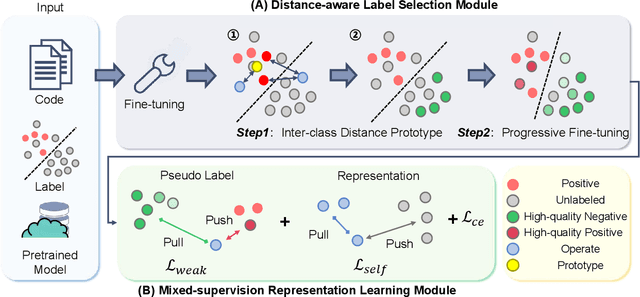

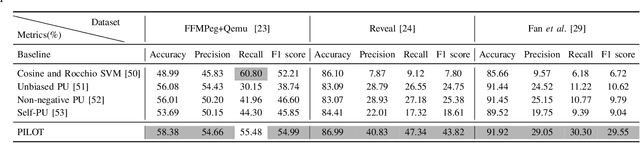
Automated code vulnerability detection has gained increasing attention in recent years. The deep learning (DL)-based methods, which implicitly learn vulnerable code patterns, have proven effective in vulnerability detection. The performance of DL-based methods usually relies on the quantity and quality of labeled data. However, the current labeled data are generally automatically collected, such as crawled from human-generated commits, making it hard to ensure the quality of the labels. Prior studies have demonstrated that the non-vulnerable code (i.e., negative labels) tends to be unreliable in commonly-used datasets, while vulnerable code (i.e., positive labels) is more determined. Considering the large numbers of unlabeled data in practice, it is necessary and worth exploring to leverage the positive data and large numbers of unlabeled data for more accurate vulnerability detection. In this paper, we focus on the Positive and Unlabeled (PU) learning problem for vulnerability detection and propose a novel model named PILOT, i.e., PositIve and unlabeled Learning mOdel for vulnerability deTection. PILOT only learns from positive and unlabeled data for vulnerability detection. It mainly contains two modules: (1) A distance-aware label selection module, aiming at generating pseudo-labels for selected unlabeled data, which involves the inter-class distance prototype and progressive fine-tuning; (2) A mixed-supervision representation learning module to further alleviate the influence of noise and enhance the discrimination of representations.
Machine vision detection to daily facial fatigue with a nonlocal 3D attention network
Apr 21, 2021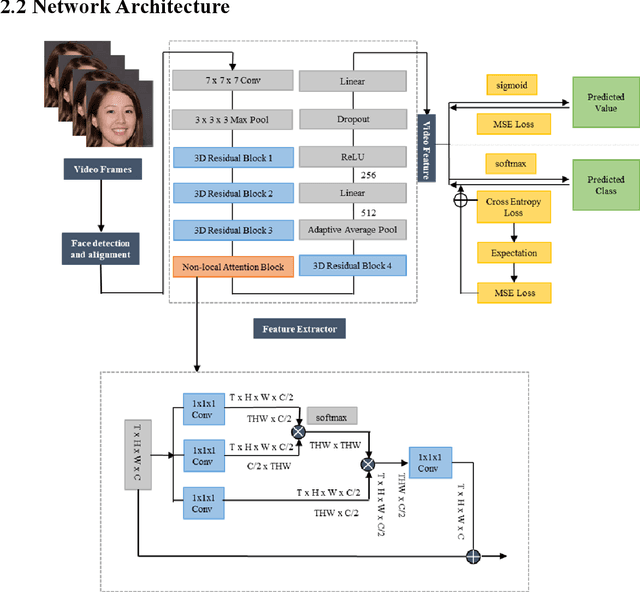
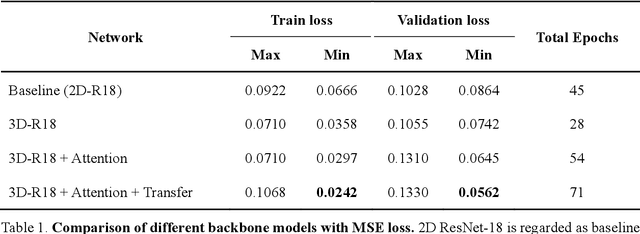
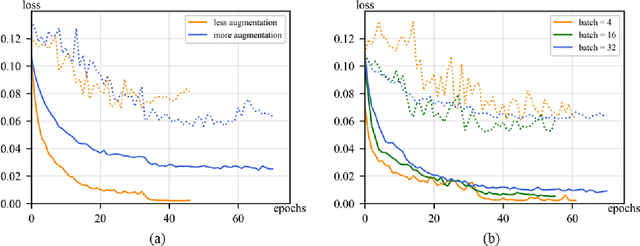
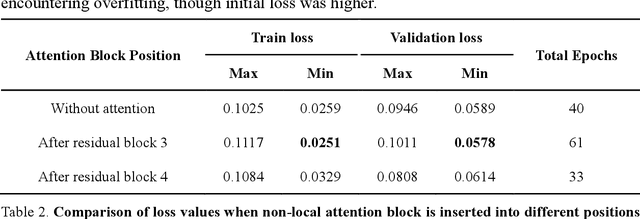
Fatigue detection is valued for people to keep mental health and prevent safety accidents. However, detecting facial fatigue, especially mild fatigue in the real world via machine vision is still a challenging issue due to lack of non-lab dataset and well-defined algorithms. In order to improve the detection capability on facial fatigue that can be used widely in daily life, this paper provided an audiovisual dataset named DLFD (daily-life fatigue dataset) which reflected people's facial fatigue state in the wild. A framework using 3D-ResNet along with non-local attention mechanism was training for extraction of local and long-range features in spatial and temporal dimensions. Then, a compacted loss function combining mean squared error and cross-entropy was designed to predict both continuous and categorical fatigue degrees. Our proposed framework has reached an average accuracy of 90.8% on validation set and 72.5% on test set for binary classification, standing a good position compared to other state-of-the-art methods. The analysis of feature map visualization revealed that our framework captured facial dynamics and attempted to build a connection with fatigue state. Our experimental results in multiple metrics proved that our framework captured some typical, micro and dynamic facial features along spatiotemporal dimensions, contributing to the mild fatigue detection in the wild.
Zero Cost Improvements for General Object Detection Network
Nov 16, 2020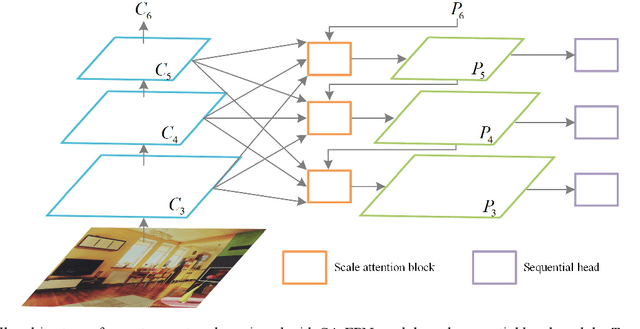
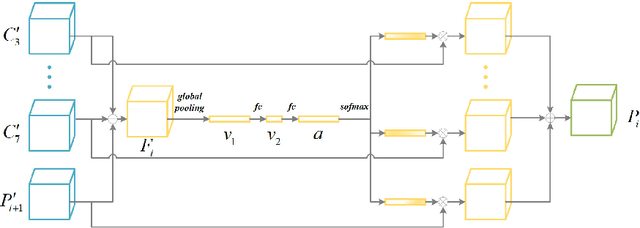
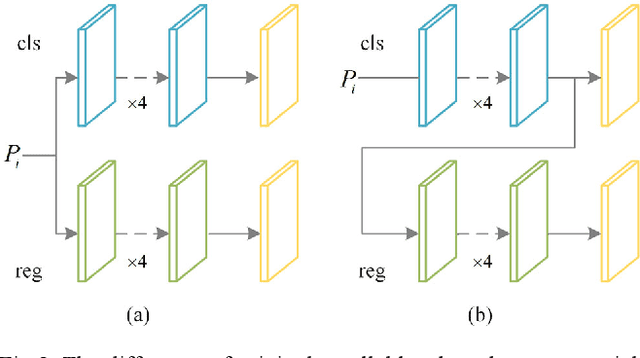
Modern object detection networks pursuit higher precision on general object detection datasets, at the same time the computation burden is also increasing along with the improvement of precision. Nevertheless, the inference time and precision are both critical to object detection system which needs to be real-time. It is necessary to research precision improvement without extra computation cost. In this work, two modules are proposed to improve detection precision with zero cost, which are focus on FPN and detection head improvement for general object detection networks. We employ the scale attention mechanism to efficiently fuse multi-level feature maps with less parameters, which is called SA-FPN module. Considering the correlation of classification head and regression head, we use sequential head to take the place of widely-used parallel head, which is called Seq-HEAD module. To evaluate the effectiveness, we apply the two modules to some modern state-of-art object detection networks, including anchor-based and anchor-free. Experiment results on coco dataset show that the networks with the two modules can surpass original networks by 1.1 AP and 0.8 AP with zero cost for anchor-based and anchor-free networks, respectively. Code will be available at https://git.io/JTFGl.
A context-based geoprocessing framework for optimizing meetup location of multiple moving objects along road networks
Dec 10, 2018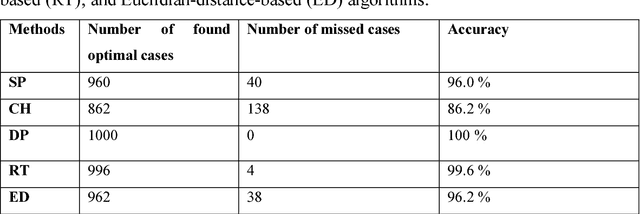
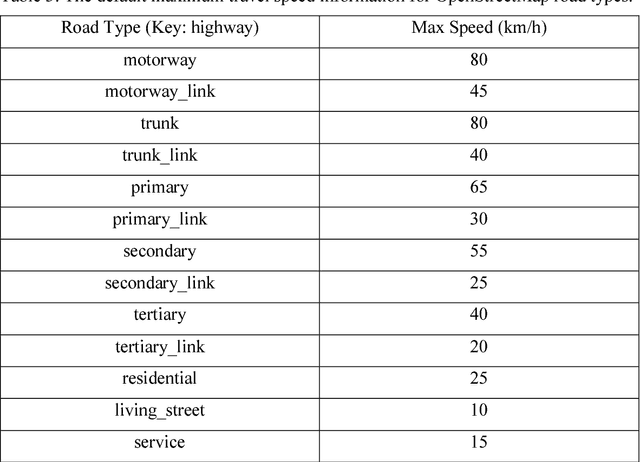
Given different types of constraints on human life, people must make decisions that satisfy social activity needs. Minimizing costs (i.e., distance, time, or money) associated with travel plays an important role in perceived and realized social quality of life. Identifying optimal interaction locations on road networks when there are multiple moving objects (MMO) with space-time constraints remains a challenge. In this research, we formalize the problem of finding dynamic ideal interaction locations for MMO as a spatial optimization model and introduce a context-based geoprocessing heuristic framework to address this problem. As a proof of concept, a case study involving identification of a meetup location for multiple people under traffic conditions is used to validate the proposed geoprocessing framework. Five heuristic methods with regard to efficient shortest-path search space have been tested. We find that the R* tree-based algorithm performs the best with high quality solutions and low computation time. This framework is implemented in a GIS environment to facilitate integration with external geographic contextual information, e.g., temporary road barriers, points of interest (POI), and real-time traffic information, when dynamically searching for ideal meetup sites. The proposed method can be applied in trip planning, carpooling services, collaborative interaction, and logistics management.
* 34 pages, 8 figures